







1 论文解读
1.1 总览
CRNN是2015年提出的论文,论文的全称是《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition》。顾名思义,针对文字识别,CRNN一方面提出了一个端到端的网络,另一方面则将文字识别问题转换成了序列识别问题。代码地址为:https://github.com/chibohe/text(包括CRNN、GRCNN、FAN、SAR、DAN、SATRN的复现)总体而言,CRNN的主要贡献有以下4点:
- 提出了一个可端到端训练的网络,由特征提取层(feature extraction)、序列模型(sequence modeling)、转译层(transcription)三部分组成;
- 将文字识别问题转化成序列识别问题,可处理任意长度的文本;
- 在无需词典进行后处理修正的情况下,识别效果依然表现良好;
- 框架简单,模型可以足够小。
根据第一点,论文的主体框架为CNN+BiLSTM+CTC, 整体架构详情见下图:
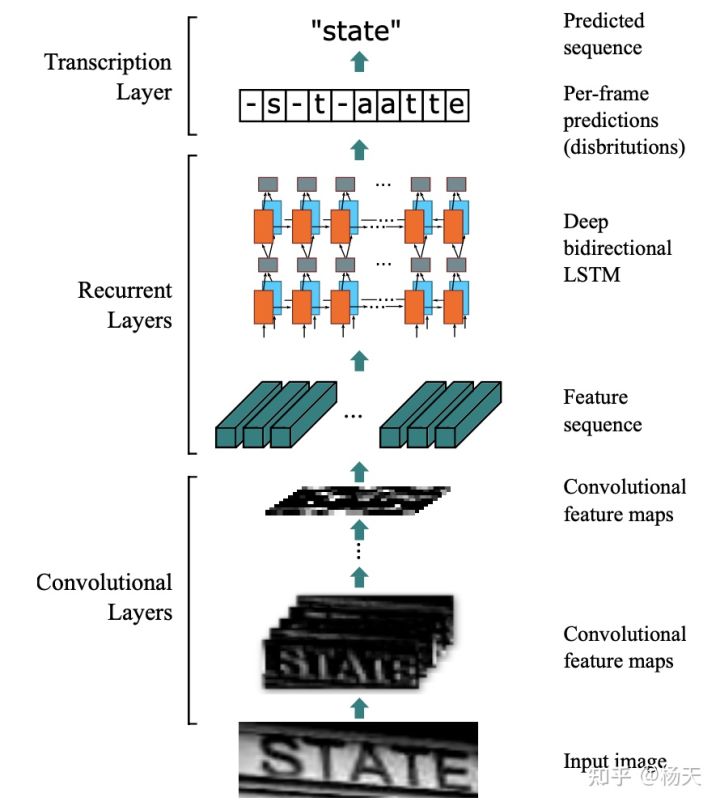
CRNN强大的地方就是它只是一个框架,其中的feature extraction和sequence modeling部分都是可以替换成不同的模型的,比如feature extraction部分,可以换成任意的抽取图像特征的模型,想要追求性能就换成小模型,想要追求效果就换成大模型,非常灵活。
1.2 特征提取层 Convolutional Layers
用CNN将原图转换成一系列的特征图,所有的卷积操作均采用3x3的卷积核,并且卷积核的数量会逐渐从最开始的64个,逐渐双倍递增至512.其中需要重点注意的是池化操作,在一般的maxpooling操作中,当kernel_size=(2, 2), stride=(2, 2)时,特征图的高度和宽度会缩减至原先的二分之一。而在论文的第三个maxpooling和第四个maxpooling中,采用的尺寸是kernel_size=(2, 1), 即高度缩减为原先的二分之一,而宽度只会减一。这样的操作是为了保留水平方向的信息,便于去处理长文本的识别。
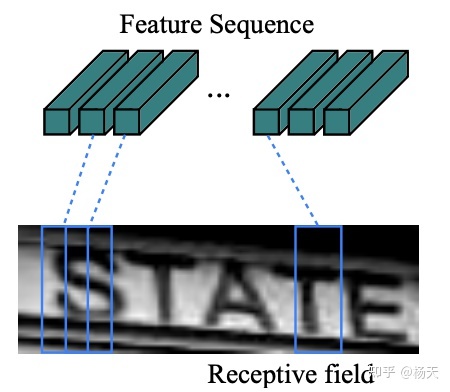
最后我们具体来看一下经过CNN后,图片尺寸的变化。在这里我们将一个张量表示为(B, C, H, W),其中B是批量处理的图片数量,C是通道个数,H是高度,W是宽度。假设原图是1通道的灰度图,高为32,宽为128,即(1, 1, 32, 128)。在经过特征提取层之后,尺寸变为(1, 512, 1, 26). 具体示意图如下,相当于feature sequence长度为26,而每个的通道数为512维。切成26个feature sequence。
1.3 Sequence modeling 序列模型
接下来要把feature sequence输入到RNN内,输入的是31个维度为512的feature sequence(向量)
在序列模型中,我们的一个基本假设是处理的文本都是水平单向的。之所以提这一点,是因为后来文字识别领域有一大问题是处理弯曲文本的识别,也就是非水平的文本,而这恰恰是CRNN不熟悉的范围。为什么要加一个序列模型呢,是因为在特征提取层之后,我们得到了一系列的特征向量,这些特征向量代表的都是图片的视觉信息,而其中的语义尚未被挖掘。所以增加序列模型的目的,在于提取其中的语义关联。
RNN层使用双向LSTM(bidirectional LSTM),双向的好处是,可以根据后面的语句信息,预测出更准确序列。例如“我的手机坏了,我想要___新手机”,单向的LSTM可能会预测到“买”或者“修”,但是双向的LSTM,根据后面的语义信息“新手机”,可以预测到“买”。
使用双向LSTM的好处是:
(1)文本是一个序列,抽取特征的CNN模型只能看到附近几帧的图片特征,而双向LSTM可以融合更远的特征,使得模型看到完整的整个字;
(2)LSTM可以和CNN使用Back-Propagation Through Time (BPTT)的方法拼接起来一起训练;
(3)LSTM可以处理任意长度的输入。
Sequence Modeling的输出
y
=
y
1
,
y
2
.
.
.
,
y
T
y=y_1,y_2...,y_T
y=y1,y2...,yT的,
y
t
y_t
yt表示第t帧为字典中每个字符的概率,是一个N+1维的向量。其中T为feature sequence的个数,N为字典中字符的个数(比如a,b,c……)。故序列模块的输出为一个T*(N+1)的概率图。N+1是因为要加入一个空白符ϵ。
1.4 CTC 转译层
1.4.1 Connectionist Temporal Classification(CTC)
适合语音识别和手写字符识别任务
输入表示:符号序列 X = [ x 1 , x 2 , . . . , x T ] X = [x_1,x_2,...,x_T] X=[x1,x2,...,xT]
输出表示:符号序列 Y = [ y 1 , y 2 , . . . , y U ] Y= {[y_1,y_2,...,y_U]} Y=[y1,y2,...,yU]
目标:找到输入X和输入Y之间精确的映射关系。其中:
- X和Y都是变长的
- X和Y的长度比值也是变化的
- X和Y相应的元素之间没有严格的对齐
损失函数的定义:对于给定的输入X,我们训练模型希望最大化Y的后验概率P(Y|X),P(Y|X)应该是磕到的,这样就可以利用梯度下降训练模型了。当我们训练好一个模型后,输入X,我们希望输出Y的条件概率最大,即
Y
∗
=
a
r
g
max
Y
P
(
Y
∣
X
)
Y^* = arg\max _YP(Y|X)
Y∗=argYmaxP(Y∣X)
希望尽量快速的得到
Y
∗
Y^*
Y∗值,利用CTC我们能在低投入情况下快速找到一个近似的输出。
CTC的对齐
假设对于一段音频,我们希望的输出是Y=[c, a, t] 这个序列,一种将输入输出进行对齐的方式如下图所示,先将每个输入对应一个输出字符,然后将重复的字符删除。
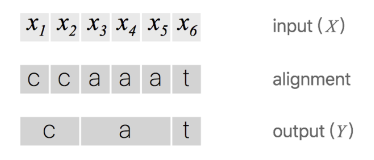
上述对齐方式有两个问题:
1、通常这种对齐方式是不合理的。比如在语音识别任务中,有些音频片可能是无声的,这时候应该是没有字符输出的。
2、对于一些本应含有重复字符的输出,这种对齐方式没法得到准确的输出。例如输出对齐的结果为[ h , h , e , l , l , l , o ] ,通过去重操作后得到的不是“hello”而是“helo”。
为了解决上述问题,CTC算法引入的一个新的占位符用于输出对齐的结果。这个占位符称为空白占位符,通常使用符号ϵ。则上图变为:

在这个映射方式中,如果在标定文本中有重复的字符,对齐过程中会在两个重复的字符当中插入ϵ占位符。利用这个规则,上面的“hello”就不会变成“helo”了。
下图说明有效对齐和无效对齐。在无效的对齐方式中举了三种例子,占位符插入位置不对导致的输出不对,输出长度与输入不对齐,输出缺少字符a
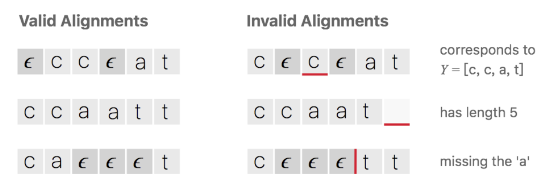
CTC算法的对齐方式有下列属性:
- 输入与输出的对齐方式是单调的,即如果输入下一输入片段时输出会保持不变或者也会移动到下一个时间片段
- 输入与输出是多对一的关系
- 输出的长度小于等于输入

CTC Loss是在计算由输出的概率图得到真实标签hello的概率,若这个概率很大,说明RNN已经训练的很好了。若概率比较下,那么Loss就很大,反向传播可以提高生成hello的概率。那么根据概率图生成hello的路径由很多种,比如概率图第一列取h字母,第二列取e字母,第三列取l字母,一直往下,直到凑成hello(下图中的箭头表示路径),由于知道每个字母的概率,所以很容易计算出由该路径得出hello的总概率(连乘)。但是这样的路径由很多,所有的路径的概率求和,即是由概率图得到hello的概率,也是我们Loss要求的。
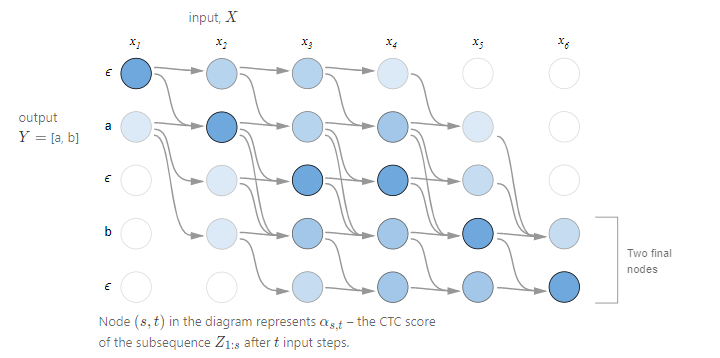
用公式来说明:对于一对输入输出(X, Y)来说,CTC的目标是将下式概率最大化
P
(
Y
∣
X
)
=
∑
A
∈
A
X
,
Y
∏
t
=
1
T
p
t
(
a
t
∣
X
)
P(Y|X) = \sum_{A\in A_{X,Y}}\prod^T_{t=1}p_t(a_t|X)
P(Y∣X)=A∈AX,Y∑t=1∏Tpt(at∣X)
解释一下,对于RNN+CTC模型来说,RNN输出的就是
p
t
(
a
t
∣
X
)
p_t(a_t|X)
pt(at∣X)概率,t表示的是RNN里面的时间的概念。乘法表示一条路径的所有字符概率相乘,加法表示多条路径。因为上面说过CTC对齐输入输出是多对一的,例如heϵlϵloc与heeϵlϵlo对应的都是“hello”,这就是输出的其中两条路径,要将所有的路径相加才是输出的条件概率.(动态规划)
heϵlϵloc与heeϵlϵlo`对应的都是“hello”,这就是输出的其中两条路径,要将所有的路径相加才是输出的条件概率.(动态规划)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











