







 本文介绍了ApacheKafka,一个用于大数据实时处理的分布式事件流平台,其特点包括高吞吐量、可靠性、多种消息模式以及独特的Broker、Topic和Partition设计。重点讲解了点对点和发布/订阅模式,以及Kafka的基本架构组件如Producer、Consumer和ConsumerGroup。
本文介绍了ApacheKafka,一个用于大数据实时处理的分布式事件流平台,其特点包括高吞吐量、可靠性、多种消息模式以及独特的Broker、Topic和Partition设计。重点讲解了点对点和发布/订阅模式,以及Kafka的基本架构组件如Producer、Consumer和ConsumerGroup。
1.Kafka概述
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。(传统使用)
Kafka是一个开源的分布式事件流平台(event streaming platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
Apache Kakfa 官网:
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
2.Kafka的特点
- 高吞吐量:单机每秒处理几十上百万的消息量。即使存储了许多TB的消息,它也保持稳定的性能。
- 高性能:单节点支持上千个客户端,并保证零停机和零数据丢失,异步化处理机制
- 持久化: 将消息持久化到磁盘。通过将数据持久化到硬盘以及replica(follower节点)防止数据丢失。顺序读,顺序写;利用Linux的页缓存。
- 零拷贝:减少了很多的拷贝技术,以及可以总体减少阻塞事件,提高吞吐量。
- 可靠性 :Kafka是分布式,分区,复制和容错的。
- 分布式系统,易于向外扩展。 所有的Producer、Broker和Consumer都会有多个,均为分布式的。无需停机即可扩展机器。多个Producer、Consumer可能是不同的应用。
- 客户端状态维护:消息被处理的状态是在Consumer端维护,而不是由server端维护。当失败时能自动平衡。
- 支持online(在线)和offline(离线)的场景。
- 支持多种客户端语言。 Kafka支持 Java、.NET、PHP、Python等多种语言。
3.消息队列的模式
3.1 点对点模式(一对一)
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
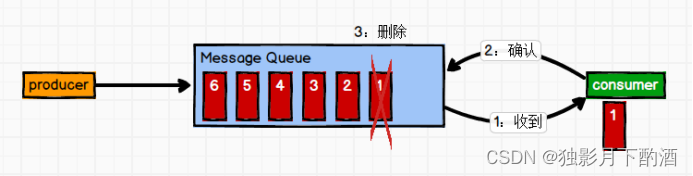
3.2 发布/订阅模式(一对多)
Kafka是发布订阅模式。 消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
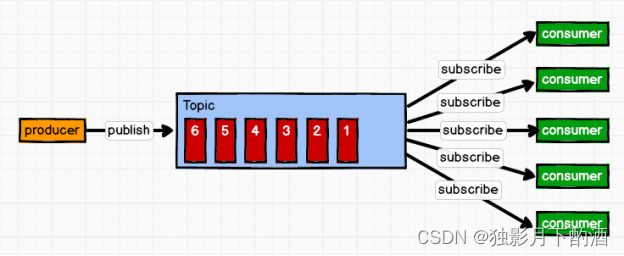
4.Kafka基本架构
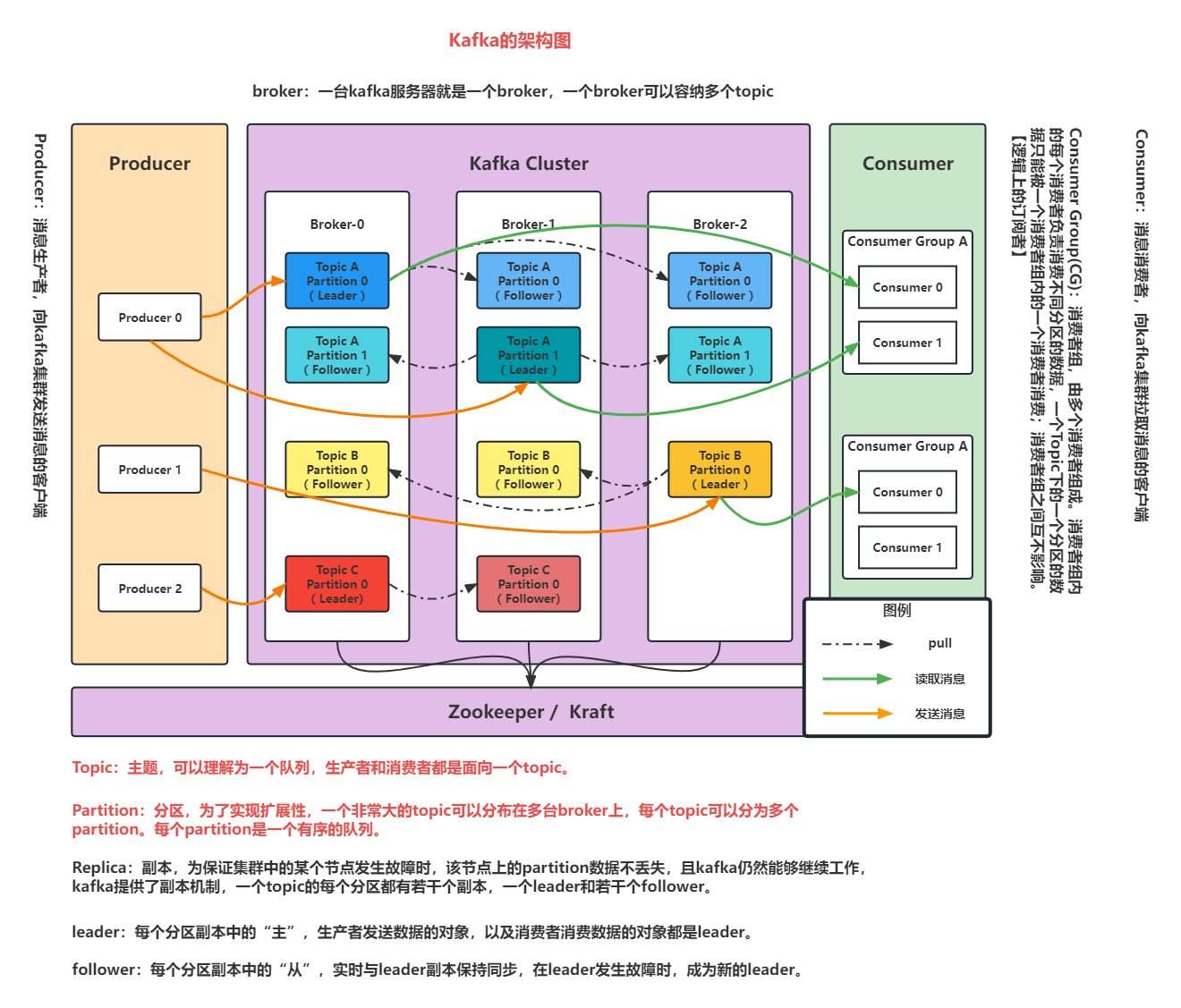
1)Producer : 消息生产者,就是向kafka broker发消息的客户端;
2)Consumer : 消息消费者,向kafka broker取消息的客户端;
3)Consumer Group (CG): 消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个topic下的一个分区只能被一个消费者组内的一个消费者所消费;消费者组之间互不影响。消费者组是逻辑上的一个订阅者。
4 )Broker : 一台kafka服务器就是一个broker。一个broker可以容纳多个topic。
5)Topic : 可以理解为一个队列,生产者和消费者面向的都是一个topic;
6)Partition: 为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
8)leader: 每个分区副本中的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
9)follower: 每个分区副本中的“从”,实时与leader副本保持同步,在leader发生故障时,成为新的leader。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









