







第一章 预备知识
C++融合了三种不同的编程方式:过程性编程(C语言代表的)、面向对象编程(C语言基础上添加的类代表的)、泛型编程(C++模板支持)。
Linux上源代码文件编译完后生成后缀.o的目标代码文件,然后执行链接后生成文件名为a.out(默认取名)的可执行程序。
C++源文件名的后缀有.cpp、.cxx、.cc、.C
预处理器:在源代码被编译之前,替换或者添加文本。比如将预处理器编译指令包含的文件的内容添加到源代码文件中,或者替换宏。
C++头文件没有后缀,C头文件转换为C++后,后缀.h去掉,最前面加前缀c(表明来自C语言)。
using namespace std ,using编译指令,使用命名空间std。命名空间的作用就是对于同一个产品,可以通过名称空间的名称指出想使用哪个厂商的产品。对应到C++中就是区分开相同名称的函数、类等。
第二章 开始学习C++
C++中函数原型对于函数来讲就相当于变量声明对于变量,它是指出函数涉及的类型,如返回类型、参数类型。简答来说函数原型就是函数头,去掉参数列表中的参数名称,保留类型。
在源程序中使用函数时,需要提前提供函数原型,有两种方法实现:
- 直接在源代码中输入函数原型
- 包含该函数所在的头文件,其中定义了函数原型
不要混淆函数原型和函数定义,函数原型只描述了函数接口,即发送给函数的信息和函数返回的信息,也就是只有函数头部。而函数定义包含了函数体的代码。C++和C中将这两项特性(函数原型和函数定义)分开了,库文件中包含了函数定义,而头文件中包含了函数的原型。
在定义函数时,如果函数不接受任何参数,则可以在函数参数列表中写void。
没有返回值的函数,它的返回类型写成void。比如:void print() {}
main函数是程序的开始,它由操作系统调用,main函数的返回值是返回给操作系统。在这个层面也可以叫返回值为退出值,退出值为零意味着程序运行成功,非零意味着存在问题。
让程序能够访问名称空间的方法有三种:
- using namespace std;放在函数定义前,则文件中所有的函数都能够使用名称空间std中所有的元素。这里使用其他名称空间也一样。
- using namespace std;放在特定的函数定义中,则只有该函数能够使用名称空间std中的所有元素。
- 如果使用using std::cout;则说明只能够使用指定的元素cout。std名称空间中的其他元素不能使用;
- 不使用编译指令using,则在使用名称空间std中的元素时,必须加上前缀std::。
第三章 处理数据
使用sizeof运算符时,对类型名使用sizeof运算符时,应该将名称放在括号中;对变量名使用sizeof运算符时括号是可选的。
头文件climits定义了符号常来表示类型的大小限制。比如INT_MAX表示类型int能够存储的最大值。


初始化是将赋值和声明合并在一起。
// 声明了变量n_int,并将int的最大值赋值给它
int n_int = INT_MAX;
C++11的初始化方式
// 使用大括号初始化器对单个变量进行初始化,等号可用可不用
int hamburgers = {24};
int emus{7};
// 大括号内,可以不包含任何东西,此时变量将被初始化为0
int rocs = {};
确定常量的类型:
整数1429是存储为int、long还是其他类型呢?可以通过使用后缀的方式来表示类型。整数后面的l或者L表示该整数是long常量。u或者U表示unsigned int常量。大小写都可以。UL和LU都表示unsigned long类型。LL表示long long
基于字符的八进制和十六进制编码来使用转义序列。比如,Ctr + Z的ASCII码为26,对应的八进制编码为032,十六进制编码为0x1a。那么可以使用转义序列来表示该字符:\032或\x1a。也可以将这些编码用单引号括起来,可以得到相应的字符常量,如’\032’,或者在字符串中“hi\x1a there”。
const限定符,用于表示常量,常量的变量名一般全部大写。声明常量时必须同时初始化。
const int num = 1;
const int num;
num = 1; // 这是错误的,因为num被声明为常量,不能再赋值更改
浮点数
浮点数表示法
2.53
8.33E5 //E表示10,指的是10的5次方,e也可以,指数可以是负数,也可以是正数。
注意数字和E之间不能有空格
C++ 有三种浮点类型:float(32位)、double(64位)、long double(80、96、或128位)
浮点常量,程序中的浮点常量,程序将把它存储为哪种浮点类型呢?默认情况下,像8.24和2.4E8都存储为double类型 。如果希望常量为float类型,这是用后缀f或者F,对于long double类型则使用L或者l。如下:
1.23f
2.45E20F
2.2L
在C++中,浮点数是有精度限制的。对于float,只保证6位有效数字。如果要更高的精度,则使用double或者long double
C++ 算术运算符
取模运算符%,只能用于整数,浮点数不行
算数表达的运算顺序,先看运算符优先级,如果运算符优先级一样,则看运算符结合性,一般都是从左往右结合,很少部分从右往左结合。
除法时,如果两个操作数是整数,则运算结果为整数,小数部分丢弃。如果其中一个操作数为浮点数,则结果为浮点数。
浮点常量默认是double,不同类型进行运算时,C++会自动把他们全部转为同一类型。
类型转换
将类型所占空间较小的值转化为类型所占空间较大的值时,不会出现问题,只是所占字节数变大了。如果反过来进行转换,则会出现精度问题、溢出问题等。
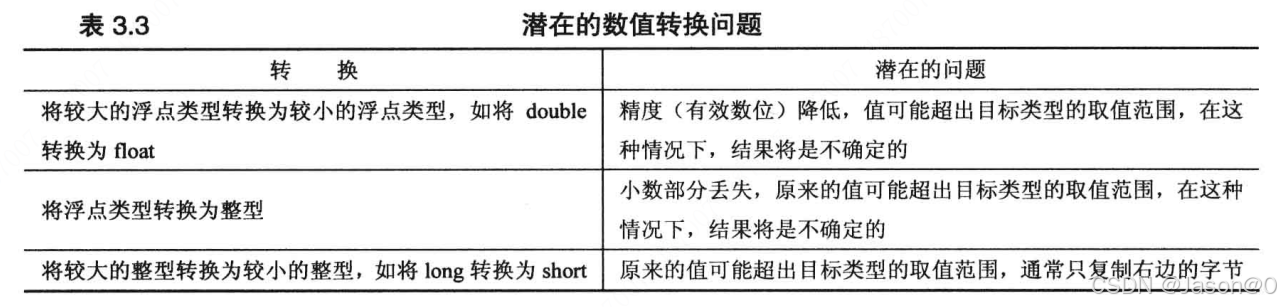
将0赋值给bool类型变量时,将被转换为false,非零值赋值给bool时转换为true.
算数运算中的类型转化:


强制类型转换:(typename) value
C++ 新增了一个自动类型auto,让编译器根据初始值的类型推断变量的类型。
auto n = 100; // 编译器把变量的类型设置成与初始值相同
第四章 复合类型
4.1 数组
short months[12]; // 数组声明:类型 变量名[元素个数]
元素个数必须是整形常数(如10)或者const值,也可以是常量表达式(如8*sizeof(int)),即其中所有值在编译时都是已知的。
int nums[3] = {1, 2, 3}; // 在声明时,用花括号给数组初始化
sizeof(nums) // 得到整个数组所占用的字节数,即三个int的大小
sizeof(nums[1]) //得到该元素占用的字节数,即一个int的大小
float nums[5] = { 0.5, .03}; // 编译器会把之后的元素自动赋值为0
long totals = {0} ; // 这表示全部为0
可以让编译器去计算数组元素个数
short things[] = {1, 2, 3};
C++11新增列表初始化
double earnings[4] { 1.2 , 2.3 , 3.4, 5.6}; // 可以直接省略等号
int nums[10[ { }; // 可以在大括号内不包含任何东西,这将把所有元素初始化为0
4.2 字符串
C++处理字符串的方式有两种:一种是C风格的char类型数组,一种是string类。
C风格的字符串以空字符结尾,空字符为\0,其ASCII码为0,用于标记字符串的结尾。
char cat[3] = { 'c' , 'a', 't', '\0'} ; // a string
char dog[3] = {'d', 'o', 'g' } ; // not a string
如果使用cout输出上面的字符串,cat可以正常输出,遇到空字符自动停止。但是dog的话会打印三个字母,然后继续将随后内存中各个字节解释为要打印的字符,直到遇到空字符。这是很危险的。
还可以用字符串常量的方式将字符数组初始化为字符串。这时会自动包含空字符,不需要显示包括它。因此这里的数组元素个数要比字符串字符个数多一个。
char bird[4] = "cat";
's' // 表示的是单个字符
“s” // 表示的是两个字符,一个s和一个空字符
注意字符串常量在C++表示的是一个地址值,是字符串所在内存的地址。
char str = "aabc"; // 这条语句试图将一个内存地址赋值给str,这是将指针类型赋值给char类型,是不合法的。
C++中允许拼接字符串常量,只要是以空白(空格、制表符、换行)分隔的字符串常量,都将自动拼接成一个。
cout << "abc" "der" ;
cout << "abcder";
cout << "abc"
"der";
// 以上这些都是等效的,注意拼接时第二个字符串的第一个字符将紧跟在第一个字符串的最后一个字符(不考虑\0),第一个字符串中的\0将被第二个字符串的第一个字符替换
sizeof计算的数组本身的长度,而strlen计算的是存储在数组中的字符串的长度,不包括空字符。
char ss[12] = "aaa";
cout << sizeof(ss) << endl; // 输出12
cout << strlen(ss) << endl; // 输出3
const int Size = 24; // Size叫符号常量,将一个变量声明为一个常量可用于表示数组长度
char name[Size]; // 符号常量Size表示数组长度合法
在C++中读到空字符,即为字符串的结束,即便后面还有字符也不读了。
const int Size = 24; // Size叫符号常量,将一个变量声明为一个常量可用于表示数组长度
char name[Size] = "C++owboy" ; // 符号常量Size表示数组长度合法
name[3] = '\0';
cout << name >> endl; // 输出C++
cin读取字符串时,它是一个字符一个字符读取的,遇到空白(空格、换行符、制表符)时,就算完成一个字符串的读取并自动在结尾添加空字符,存入对应变量中。空白后面还有字符的话,将放入输入队列中,等待下一个cin读取。
cin是读取单个单词的,但有时候需要读取一整行,把单词之间的空白也读进去,这时候可以使用istream中的类(如cin)提供的一些面向行的成员函数。getline和get。这两个函数都读取一行输入直到到达换行符,而getline将丢弃换行符,get会保留在输入序列中。
cin.getline();// getline函数的调用方法,遇到换行符输入结束。
cin.getline(name, 20); // 有两个参数,第一个参数是用来存放输入行的数组,第二个参数是要读取的字符数,如果这个参数为20,则函数最多读取19个,剩下的一个用来存放自动在结尾添加的空字符。
// getline() 在读取指定数目字符或遇到换行符时停止
istream类中还有有一个成员函数get读取一行,但是他会把换行符读入输入队列中。
// get会把换行符读入并且留在输入队列中,而不是存放字符串的数组中,既然是在输入队列中,那这时再调用get读取的话,第一时间读到的就是换行符,完了立刻停止读取。导致之后实际输入的字符串没有被读取。解决办法是多调用一次get,让其把换行符读走。
#include<iostream>
#include<cstring>
using namespace std;
int main()
{
const int Size = 12;
char name1[Size];
char name2[Size];
cin.get(name1, Size);
cin.get(); // 如果没有这个get,那么第一个get读入的换行符放在输入队列中,第二个get在输入队列中读取时,读到的第一个字符就是换行符,那么会立刻停止读取,导致name2中没有有效读入
cin.get(name2, Size).get();
cout << name1 << " " << name2 << endl;
}
// 两种调用方式cin.get(name1, Size);和cin.get();
// cin.get(); 不带任何参数,读取下一个字符
// cin.get(name1, Size); 参数的解释和getline一样,但是它会把换行符留在输入队列中,不会读取到第一个参数中。
// 可以进行链式调用,因为cin.get()返回的是cin对象所以可以cin.get().get()。getline也是一样
4.3 string类简介
C++11允许将列表初始化用于C风格字符串和string对象。
// 中间可以加等号也可以不加
char str1[] { " abcd "}; // C风格字符串列表初始化
string str2 { "edcrfv" }; // string 对象列表初始化
4.3.2 赋值、拼接和附加
不可以将一个数组赋值给另一个数组,但可以将一个string对象赋值给另一个string对象。
char str1[20] ;
char str2[20] = "adv";
string str3;
string str4 = "abc";
str1 = str2; // 无效
str3 = str4; // 有效
字符串拼接,可以使用运算符+,以及+=,将两个字符串进行拼接。
string str5;
str5 = str3 + str4;
str3 += str4;
对于C风格的字符串可以使用strcpy和strcat函数进行字符串赋值和拼接。
#include<cstring> // c风格字符串库,c开头的头文件表示c语言的库
strcpy(str1, str2); // 将str2复制到str1
strcat(str1, str2); // 将str2拼接到str1
4.4 结构简介
数组只能存储同一类型的元素。如果想要存储不同类型的元素就需要用到结构。结构是用户定义的类型,声明定义好类型后,就可以创建它的变量(对象)。
定义结构
// 关键字 struct 用于定义结构
struct player
{
char name[20]; //结构成员
int height;
float score;
}; // 分号别忘了
// 定义好结构后,就可以创建该类型的变量了
player person1;
player person2;
// 在C++ 中声明结构变量时,允许省略struct关键字,但是在C中要加上。这表明结构声明定义了一种新类型。
可以使用成员运算符,通过结构变量来访问成员。
结构变量初始化
player person = { "name", 120, 25.5}; // 每个值用逗号分隔
player person1 { "name", 120, 25.5}; //列表初始化
C++使用户定义的结构类型与内置类型尽可能相似,例如可以将结构作为参数传递给函数,也可以让函数返回一个结构。也可以使用赋值运算符将结构赋值给另一个结构变量,这样结构中的每一个成员都将被设置成另一个结构中对应成员的值。即便成员是数组也可以。这种赋值成为成员赋值。
//可以同时完成结构的定义和创建结构变量
struct perks
{
int key_number;
char car[12];
} mr_smith, ms_jones;
// 甚至可以原地初始化
struct perks
{
int key_number;
char car[12];
} mr_glits =
{
7,
"Packard"
}; // 一般不推荐这种方式,不易阅读和理解
// 还可以声明没有名称的结构变量
struct
{
int key_number;
char car[12];
} mr_glits;
// 这样将导致该结构,永远只有一个变量,之后无法在创建该结构的变量
C++结构包含了C结构的所有特性,但是C++结构的特性更多,例如,C++结构除了成员变成之外,还可以包含成员函数。
创建结构数组和创建普通数组一样。
player person[20]; // player为一个定义的结构
// 通过成员运算符“.” 访问每一个元素的成员
cout << person[10].name ;
// 结构数组初始化
player person[2] = {
{"name1", 12, 25.5},
{"name2", 14, 26.5}
};
4.5 共用体
共同体是一种数据格式,可以存储不同的数据类型,但只能同时存储其中的一种类型。也就是说结构可以同时存储int、long和double类型的数据,但是共用体只能存储int、long或double。共用体的语法和结构相似,但含义不同。
union one4all
{
int int_val;
long long_val;
double double_val;
};
one4all pail;
pail.int_val = 14;
cout << pail.int_val ; // 存储一个int值
pail.double_val = 1.38;
cout << pail.double_val; // 存储一个double,int 值丢失
因此,可以看出pail有时可以是int变量,有时又可以是double变量。共用体每次只能存储一个值,因此它必须有足够的空间来存储最大的成员,所以,共用体的长度为其最大成员的长度。
4.6 枚举
enum工具提供了一种创建符号常量的方式,这种方式可以代替const。他还允许定义新类型。使用enum的句法如下:
enum spectrum {red, orange, yellow, green}
// 这条语句完成了两项工作,一是让spectrum成为新的类型,spectrum被称为枚举。二是red、orange等作为符号常量,它们对应的整数值0开始以此类推,这些符号常量叫作枚举量。
spectrum band; //用枚举名来声明这种类型的变量
// 枚举变量具有一些特性,只能将定义枚举时使用的枚举量赋给这种枚举的变量
band = red;
band = 200; // error
对于枚举只定义了赋值运算符,没有定义算术运算符。
枚举量是整形,可以被提升为int类型,但int类型不能自动转换为枚举类型。
int color = red; // 有效,枚举可以提升为int
band = 3; // 无效,int不能转换为枚举
color = 3 + red; // 有效,枚举转换为int
枚举更常被用来定义相关的符号常量,而不是新类型。
可以使用赋值运算符显示设置枚举量的值。
enum bits {one = 1, tow = 2, four = 4, eight = 8};
// 指定的值必须是整数,也可以只显示指定其中一些枚举量的值
enum bigstep {first, second = 100, third}; // 这里first默认是0,second是100,那third就是101以此类推。
// 也可以创建多个值相同的枚举量
enum {zero, null = 0, one, numero_uno = 1}; // 匿名枚举
4.7 指针和自由存储空间
计算机程序在存储数据时必须跟踪三种属性:
- 信息存储在何处
- 存储的值为多少
- 存储的信息是什么类型
指针是一个变量,存储的值是地址,而不是值本身。对于常规变量可以应用地址运算符&来获取其地址。&home
通过解引用运算符(*)可以获得指针表示的地址所指向的内存空间中的值。假设mainly是指针变量。*mainly表示存储在该地址处的值。
声明指针
int* ptr; // 星号两边有没有空格都可以
//以下是声明了一个指针和一个int变量
int* ptr1, ptr2;
// 如果需要声明两个指针必须有两个星号
int* ptr1, *pt2;
需要注意:指针变量虽然是不同类型的指针,表示它们所指向的值的不同类型,同时也表示内存空间大小不同。但是指针变量本身的大小是一样,根据计算机系统的不同,指针变量本身的大小一般是2字节或者4字节。
指针的危险
在创建指针时,计算机会分配用来存储地址的指针,但是不会分配用来存储指针所指向的数据的内存。为数据提供空间是一个独立的步骤,也就是指针初始化或者赋值(赋值一个地址)。不这么做会引来麻烦。
int* fellow;
*fellow = 23;
以上示例中fellow是一个指针,已经分配了存储地址的内存空间,但是并没有存储数据的内存空间。我们不知道fellow到底指向哪里,这时fellow是没有初始化或者赋值的,它可以是任意值。不管是什么值,程序都将他解释为存储23的地址。那如果fellow中的值是某个程序代码的地址,那计算机将把程序代码替换为23。这会导致一些隐秘且又严重的错误。
因此,当我们声明了一个指针时,一定要记得在使用它之前,对它进行初始话或者赋值一个可用且合理的地址。
指针和数字
指针是一种单独的类型,不是整型。整数能进行加减乘除。而指针描述的是地址,对地址进行相乘没有任何意义。从操作上看,整数和指针也是不一样的。所以不能将整数赋值给指针,必须进行强制类型转换,把整数转成指针类型。
int* pt;
pt = 0xB800000; // type mismatch
pt = (int*)0xB800000; // type match
使用new来分配内存
前面都是将指针初始化为变量地址,变量是在编译时分配的有名称的内存。而指针只是为可以通过名称直接访问的内存提供的别名。
指针真正的用武之地是在运行阶段分配未命名的内存以存储值。在这种情况下,只能通过指针来访问内存。
C语言中,可以使用库函数malloc()来分配内存。C++中仍可以这样做,但是C++有更好的方法,new运算符。
程序员需要告诉new,为哪种类型分配内存,new将找到一个长度正确的内存块。程序员的责任是将地址赋给一个指针。
int* ptr = new int;
**注意:**对于指针,需要指出的另一点是,new分配的内存和常规变量声明分配的内存是不同的,常规变量的内存在栈区,new分配的内存在堆区。堆区内存有限,用完记得释放。
使用delete释放内存
new申请完内存后,用完后,需要使用delete释放。
int* pt = new int;
delete pt; // delete后面加上指向内存块的指针
delete将释放指向的内存,但是指针变量本身依然存在,可以将pt指向一个新分配的内存块。
一定要记得new和delete 配套使用,有分配就要有释放。否则将发生内存泄漏,也就是这块被分配的内存再也无法给其他程序使用了。如果内存泄漏严重,则程序将无内存可以分配,导致程序将由于不断寻找更多内存而又找不到而终止。
同时不要释放已经释放的内存块,C++标准指出,这样的结果将是不确定的 ,这意味着什么情况都可能发生。
另外不能使用delete释放声明变量所获得内存,delete只能用于释放通过new分配的内存。
int* ps = new int;
delete ps; // ok
delete ps; // not ok now
int jugs = 5;
int * pi = &jugs;
delete pi; // not allowed ,memory not allocated by new
注意:使用delete的关键在于,将它用于new分配的内存,这并不意味着要使用用于new的指针,而是用于new的地址。
int* ps = new int;
int* pq = ps;
delete pq; // ok
最好不要创建两个指向同一块内存的指针,因为这会增加错误的删除同一块内存两次的可能性。
使用new来创建动态数组
通常对于大型数据,比如数组、字符串、结构,应使用new,这正是new的用武之地。如果通过声明来创建数组,则程序在编译时将为他分配内存空间。不管程序最终是否使用数组,数组都在那里,它占用了内存。在编译时给数组分配内存被称为静态联编,意味着数组是在编译时加入到程序中。但是使用new时,如果在运行阶段需要数组,则创建它,如果不需要,则不创建。还可以在程序运行时选择数组长度。这被称为动态联编,意味着数组是在程序运行时创建的。这种数组叫做动态数组。使用静态联编时,必须在编写程序时指定数组长度;使用动态联编, 程序将在运行时确定数组长度。
//创建动态数组
int* psome = new int[10]; //10个元素的int数组
// new运算符返回第一个元素的地址, psome指向数组的第一个元素
对于使用new创建的数组,应该使用另一种格式的delete来释放。
int* psome = new int[10]; //10个元素的int数组
delete [] psome;
方括号告诉程序应该是释放整个数组,而不是指针指向的元素。
判断标准:如果使用new时带方括号,则delete也带方括号。如果new不带,则delete也不带。
注意:new和delete的格式不匹配,导致的后果是不确定的,这意味着程序员不能依赖于某一种特定行为。
int* pt = new int;
short* ps = new short[10];
delete [] pt; // 未定义行为,不要这么做
delete ps; // 未定义行为,不要这么做
使用new和delete时,应遵守的规则
- 不要使用delete释放不是new分配的内存
- 不要使用delete释放同一个内存两次
- 如果使用new [ ] 为数组分配内存,则应使用delete [ ] 来释放
- 如果使用new [ ] 为一个实体分配内存,则应使用delete(没有方括号)来释放
- 对空指针应用delete是安全的
使用动态数组
int* ptr = new int[10];
这里将ptr指针移动一下,将指向第二个元素,实际上是移动了四个字节,因为int占四个字节。
double* p3 = new double[3];
p3[0] = 0.2;
p3[1] = 0.5;
p3[2] = 0.8;
cout << p[1] < endl; // 打印0.5
p3 = p3 + 1; //指针移动
cout << p[0] << endl; // 打印0.5
cout << p[1] << endl; //打印0.8
p3 = p3 - 1;
delete [] p3;
从以上代码可以看出,可以将指针当作数组名使用,但是指针和数组名还是有本质差别。我们不能修改数组名的值,它是一个常量。但是指针是变量,它的值是可以改的。p3 = p3 + 1;这条语句指出了数组名和指针之间的根本差别。
4.8 指针、数组和指针算术
指针和数组基本等价的原因在于指针算术和C++内部处理数组的方式。将整数加1,其值将增1。但是将指针加一后,增加的量等于它指向的类型的字节数。比如将double类型的指针加一后,则数值将增加8。double类型占用的内存空间是8字节。
同时,在C++中将数组名解释为地址。
double wages[3] = {1.0, 2.0, 3.0};
double* pw = wages; // 数组名直接就是地址,表示数组的第一个元素
cout << sizeof(wages) << endl; // 输出24
cout << sizeof(pw) << endl; // 输出4字节
// wages == &wages[0] == 数组第一个元素的地址
// wages[1] == *(pw + 1)
wages[1] == *(pw + 1),使用数组表示法时,C++都执行如下转换:
arrayname[i] becomes *(arrayname + 1)
如果使用的是指针,则C++也执行同样的转换pointername[i] becomes *(pointername+ 1)
区别:
- 指针是变量,可以更改它的值,数组名是常量,不能改它的值,它的值在初始化就决定了
- 对数组应用sizeof运算符得到数组的长度,而对指针应用sizeof运算符得到指针的长度,即指针变量本身内存空间大小。即便指针指向数组,和数组长度无关
值得反复阅读的经典部分

声明的常规变量,就是对内存空间取了个名字,通过这个名字去访问对应的内存空间。
用&对变量名取地址,获得被命名的内存空间的地址,用new运算符返回的是未命名的内存的地址。
对指针解引用的方法有*运算符,也有数组表示法,如果指针指向的是数组的话,*p和p[0]一样,*(p+1)和p[1]一样。
指针算术
C++允许指针加一,结果就是在原有地址上加上所指对象类型的总字节数。两个指针也可以相减,得到两个指针的差,是一个整数,表示两个指针之间的间隔,间隔了几个元素,这种仅当两个指针指向同一个数组时才有意义。
在cout和C++其他表达式中,char数组、char指针以及引号括起来的字符串常量都被解释为字符串的第一个字符的地址。
指针和字符串
一般来说给cout提供一个地址,它将打印地址,但是如果指针的类型为char*,则cout会显示指向的字符串,如果想显示字符串的地址,则必须将指针强制转换为另一种指针类型,比如(int*)。
字符串常量(字面量)是不能被修改的。
char* str = "abc";
str[0] = 'q'; //非法的
//最好声明成常量
const char* str = "abc";
cout << str << (int*)str << endl; //打印字符串和字符串地址,对于char类型的指针,需要强制转换地址
char animal[20] = "bear";
char* ps;
ps = new char[strlen(animal) + 1]; //streln获取的字符串长度,没有包含空字符,所以需要加一。不包含空字符就不是表示字符串
strcpy(ps, animal); // 直接将animal赋值给ps是不行的,因为赋值的是地址,不是字符串,得用库函数strcpy
char food[9] = "carrots";
strcpy(food, "abcdefghrydkslsssdedd"); // 错误,这个时候复制的字符串的长度大于数组的长度,会导致多出的部分被赋值到数组后的内存字节中,这可能会覆盖程序正在使用的其他内存,很危险。要避免这种问题,就需要使用strncpy
strncpy(food, "abcdefghrydkslsssdedd", 8); //第三个参数指定复制的长度,这时只复制了8个,还剩一个空间用来存放空字符。
food[8] = '\0'; // 如果复制的字符串长度小于8个字符,则strncpy会自动加上空字符
要将字符串放到数组中,要么在数组初始化时,用=赋值。要么只能使用库函数strcpy或strncpy。

使用new创建动态结构
在运行时创建数组优于在编译时创建数组,结构也是如此。
// people是一个结构
people* ptr = new people;
//把足以存储people结构的一块可用内存的地址赋给ptr。
需要注意的是创建动态结构时,不能用成员运算符句点来访问成员。因为这种方式创建的结构没有名称,只知道他的地址ptr。ptr不是他的名称是他的地址。C++专门为这种情况提供了一个运算符:箭头成员运算符(->),用于指向结构的指针ptr。就像句点运算符可用于结构名一样。比如name是people结构的一个成员,则可以ptr->name来访问。ptr表示指向结构的指针,那如果把它转换成结构本身,则也可以使用句点运算符,即(*ptr).name。记住要加括号,运算符优先级规则。
自动存储、静态存储和动态存储
C++有3种管理数据内存的方式:自动存储、静态存储和动态存储(也叫作自由存储空间或堆)。C++11新增了第四种类型:线程存储。
- 自动存储:在函数内部定义的常规变量使用自动存储空间,被称为自动变量,它们在函数调用时自动产生,函数结束时消亡。自动变量是一个局部变量,其作用域为包含他的代码块,代码块是被包含在花括号中的一段代码。目前接触到的代码块就是整个函数,但是函数内部也可以有代码块。自动变量存储在栈中,执行代码块时,其中的变量将依次加入栈中,而离开代码块时,将按照相反的顺序释放这些变量,这被称为后进先出。因此在程序执行的过程中,栈将不断地增大和缩小。
- 静态存储:静态存储是整个程序执行期间都存在的存储方式。使变量成为静态的方式有两种:一种是在函数外面定义它,另一种是在声明变量时使用关键字static。自动存储和静态存储的关键在于,这些方法严格的限制了变量的寿命,变量可能存在于整个生命周期(静态变量),也可能只是特定函数被执行时存在(自动变量)。
- 动态存储:new和delete运算符提供了一种比自动变量和静态变量更灵活的方法。它们管理了一个内存池,这在C++中被称为自由存储空间(free store)或堆(heap)。该内存池同用于自动变量和静态变量的内存是分开的。new和delete分配的内存的生命周期不完全受程序或函数的生存时间限制。new和delete让程序员对程序如何使用内存有更大的控制权。然后内存管理也更复杂了。在栈中,自动添加和删除机制使得占用的内存总是连续的。但new和delete的相互影响可能导致占用的自由存储区不连续,这使得跟踪新分配内存的位置更困难。
内存泄漏:如果使用new运算符在自由存储空间(或堆)上创建变量后,没有调用delete,将会发生内存泄漏。如果没有调用delete,则即使包含指针的内存(指向该内存空间的指针变量自身)由于作用域规则或者对象生命周期的原因而被释放,在自由存储空间上动态分配的变量或者结构依然存在。这时将没有指针变量指向该自由存储空间上的内存,导致无法访问该内存中的数据,因为指针已经被释放了,但是自由存储空间上的内存没有被delete。这将导致内存泄露,即该内存在程序的整个生命周期内都不在可以使用。这些内存被分配出去,但无法收回。极端的情况就是,内存泄漏非常严重,以至于应用程序可用的内存被耗尽,出现内存耗尽错误,程序崩溃。甚至这种泄露还会给一些操作系统或者在相同的内存空间中运行的程序带来负面影响,导致他们崩溃。
4.10 数组的替代品
4.10.1 模板类vector
vector类是new创建动态数组的替代品,实际上vector类确实使用new和delete来管理内存,但这种工作是自动完成的。
使用vector类,必须包含头文件vector。其次vector包含在名称空间std中,因此可以使用using编译指令。
#include <vector>
using namespace std;
vector<int> vi; // 模板类使用尖括号来指定数组中存放的元素类型,初始长度为0,之后添加删除元素会自动调整大小
int n = 10;
vector<int> nums(n); // 通过n指定数组的大小。
4.10.2 模板类array(c++11)
vector功能比数组强大,但是代价是效率稍低。如果需要长度固定的数组,使用数组是更加选择,代价是不那么方便和安全。C++11新增了模板类array,他也位于std名称空间中。与数组一样,array的长度也是固定的,也是使用栈(静态内存分配),而不是自由存储区(堆)。因此效率与数组相同,但更安全、方便。要创建array对象,需要包含头文件array。
#include <array>
using namespace std;
array<int, 5> ai; //创建了包含5个int类型的数组
array<double, 4> ad = {1.2, 2.1, 3.4, 4.3};
//不能用变量来指定array数组的大小
4.10.3 比较数组、vector对象和array对象
都可以使用下标运算符来访问数组中的元素。array对象和数组存储在相同内存区域中(即栈),而vector对象存储在另一个区域(自由存储区或堆)中。可以将一个array对象赋值给另一array对象。但是对于数组必须逐元素赋值数组。
第五章 循环和关系表达式
5.1 for循环
C++中任何值或者任何变量或者任何值于运算符的组合都是表达式。
C++中赋值表达式也有返回值,x = 20;的返回值就是左侧x的值,即返回20。所以允许x = y = z = 0;这种表达式。这种方法可以快速将若干个变量设置为同一个值。赋值运算符的优先级是从右往左的。
像x < y这样的表达式,就会返回true或者false。
记住C++中每个表达式都有值。
从表达式到语句的转变很容易,只需要在表达式后面加上分号;即可。
for循环中常用的递增运算符和递减运算符。
a++ // 先使用a的值计算当前的表达式,然后再将a的值递增一
++a // 先将a的值递增一,再使用a的值计算当前表达式
// 递减运算符同理
前缀运算符(递增和递减)和解引用运算符(*)的优先级一样,以从右到左的方式结合。后缀运算符(递增和递减)优先级一样,但比前缀运算符的优先级高。这两个运算符以从左到右的方式进行结合。
//pt是一个指针变量
*++pt; // 含义:*和前缀递增优先级一样,以从右到左结合,先将++用于pt,然后将*用于被递增的pt。
++*pt; // 含义:先将*用于pt,然后将取得的值加一。
*pt++; // 含义:后缀运算符的优先级更高,因此先看后缀运算符这块,后缀运算符是先使用pt再加一,先使用pt与*解引用得到值,然后再将pt指针加一。
5.1.9 组合赋值运算符
就是将一个运算符和赋值运算符组合起来一起用。
i = i + 1;
i += 1; // 组合赋值运算符
5.1.10 复合语句(语句块)
其实无论是函数,还是for、while循环,他们之后都只能接一条语句。那为什么我们可以放多条语句呢,就是因为语句块的存在。通过花括号将多条语句括起来,那么整个花括号就被当做一条语句。如果不加花括号,那就真的只能写一条语句了。
复合语句还有一个特点就是在语句块中的定义的变量,仅当程序执行到语句块中的语句时,变量才存在。程序离开语句块了变量将被释放。
5.1.11 其他语法技巧–逗号运算符
语句块允许把两条或者多条语句放到按C++句法只能放一条语句的地方。逗号运算符对表达式完成同样的任务,允许将两个或者多个表达式放到C++句法只允许放一个表达式的地方。
// 比如for循环表达式第三部分。i-- , j++
for (int i = 0; i < 10; i--, j++)
{
}
当然逗号不一定总是逗号运算符,在变量声明时可用于将多个变量隔开。
逗号运算符还有两个特性:
- 确保先计算第一个表达式,在计算第二个表达式,也就是逗号运算符是一个顺序点。
i = 20, j = 2*i,先计算i=20 - 逗号表达式的值是第二部分的值。上述表达式的值为40
- 在所有运算符中逗号的优先级是最低的。
cate = 70, 240; // cate的值是70,因为=运算符的优先级高于逗号
cate = (70, 240); // cate的值是240,因为括号优先级高于赋值运算符。先计算括号表达式的值,而括号表达式中是一个逗号表达式,逗号表达式的值是240。
第七章 函数-C++的编程模块
7.1 复习函数的基本知识
C++中函数完成如下工作:
- 提供函数定义
- 提供函数原型
- 调用函数
库函数是已经定义和编译好的函数,同时可以使用标准库头文件提供其原型,因此只需要正确地调用这种函数即可。
7.1.1 定义函数
函数分为有返回值的函数和没有返回值的函数,没有返回值的函数被称为void函数,其通用格式如下:
void functionName(parameterList)
{
statements
return;
}
有返回值类型的函数
typeName functionName(parameterList)
{
statements
return value;
}
C++对返回值的类型有一定的限制:不能是数组,但可以是其他任何类型。虽然不能直接返回数组,但是可以将数组作为结构或者对象组成部分来返回。
7.1.2 函数原型和函数调用
void printNum(int num);
void printNum(int num)
{
statements
return;
}
- 为什么需要原型?
原型描述了函数到编译器的接口,也就是说,它将函数返回值的类型(如果有的话)以及参数的类型和数量告诉编译器。 - 原型的语法
函数原型是一条语句,因此必须以分号结束。获得函数原型最简单的方法是,复制函数定义中的函数头,并添加分号。还有就是函数原型不要求提供变量名,有类型列表就够了。原型中的变量名相当于占位符,因此不必与函数定义中的变量同名。void printNum(int); - 原型的功能
3.1 编译器正确处理函数返回值
3.2 编译器检查使用的参数数目是否正确
3.3 编译器检查使用的参数类型是否正确
7.2 函数参数和按值传递
- 一般情况下,函数调用传递值都是按值传递,即形参获得的值是实参的副本。C++使用参数表示实参,使用参量表示形参。
- 函数中声明的变量包括参数是该函数私有的,在函数调用时,计算机将为这些变量分配内存,在函数调用结束时,计算机将释放这些变量使用的内存。这些变量被称为局部变量。
7.2.1 多个参数
- 函数可以有多个参数,每个参数之间用逗号分开即可。
- 如果两个参数的类型相同,则必须分别指定每个参数的类型。
- 原型中的变量名不必和定义中的变量名相同,而且可以省略。
7.3 函数和数组
int sum_arr(int arr[], int n) // arr 是数组名,n是数组长度
// 这里需要注意的是方括号指出arr是一个数组,而方括号为空则表明,可以将任何长度的数组传递给该函数。但是实际上,arr并不是一个数组,而是一个指针!将数组传递给该函数时,数组会退化为指针。
7.3.1 函数如何使用指针来处理数组
- 大多数情况下,C++和C语言一样,也将数组名视为指针。C++将数组名解释为其第一个元素的地址。
- 在函数原型中 int arr[] 和 int* arr 是等价的,因为数组作为实参传递给函数时,我们传递的是数组名,而数组名就是指向数组第一个元素的指针。所以参数类型也可以声明为int* arr。由于数组元素类型是int,所以是int型指针。
- 在其他情况下int arr[] 和 int* arr 含义是不一样的,一个表示指向一个数组,一个是表示指向一个地址。
- 数组名和指针一样,可以使用方括号数组表示法访问数组元素
int arr[5];
// 那么 arr 表示数组的首地址,也就是 &arr[0]。
// 数组名本身并不表示整个数组的地址 (在内存中的位置),但是你可以通过取数组的地址 &arr 来获取整个数组的地址。这个地址的类型是 int(*)[5](指向具有 5 个整数的数组的指针)。
std::cout << "arr: " << arr << std::endl; // 输出 arr[0] 的地址
std::cout << "&arr: " << &arr << std::endl; // 输出整个数组的地址
//注意:arr 和 &arr 表示的地址在值上是相同的,但它们的类型不同。
#include <iostream>
int main() {
int arr[5] = {1, 2, 3, 4, 5};
std::cout << "arr: " << arr << std::endl; // 地址 of arr[0]
std::cout << "&arr: " << &arr << std::endl; // 地址 of arr itself
std::cout << "First element: " << *arr << std::endl; // 输出第一个元素的值: 1
std::cout << "Size of arr: " << sizeof(arr) << std::endl; // 数组的总大小(字节数)
std::cout << "Size of &arr: " << sizeof(&arr) << std::endl; // 指针类型的大小
std::cout << "Size of arr[0]: " << sizeof(arr[0]) << std::endl; // 单个元素的大小
return 0;
}
/输出
arr: 0x7ffee2c1b590 // 表示 arr[0] 的地址
&arr: 0x7ffee2c1b590 // 表示整个数组的地址 (值相同,但类型不同)
First element: 1
Size of arr: 20 // 5 * sizeof(int) (假设 sizeof(int) = 4)
Size of &arr: 8 // 指针类型的大小 (通常是8字节在64位系统上)
Size of arr[0]: 4 // sizeof(int)
7.3.2 将数组作为参数意味着什么
- 仔细看会发现,数组名称传递给函数时,其实数组的内容并没有传递给函数内部,而是数组的位置。包含元素的类型以及数组的长度,有了这些信息后,函数便可以使用原来的数组。
- 传递常规变量时,函数将使用该变量的拷贝,但传递数组时,函数使用的就是原来的数组。实际上,这种区别并不违反C++按值传递的方法,函数仍然传递一个值,这个值就被赋值给一个新变量,但是这个值是一个地址,而不是数组的内容。
void fillArray(int arr[], int size); // 数组名,长度
void fillArray(int arr[size]); // 这种写法是错误的
7.3.3 更多数组函数示例
// 编写一个处理double数组的函数,并且修改数组
void f_modify(double arr[], int n);
// 如果不修改数组
void f_no_change(const double arr[], int n); // const double arr[] == const double *arr
// 以上这样的方式传递数组是不可以在函数中使用sizeof 来获取原始数组的长度,而必须依赖程序员传入正确的元素数
7.3.4 使用数组区间的函数
- 传统的做法一般是将数据种类、数组的起始位置和数组中元素数量提交给它。传统C++做法是将指向数组起始处的指针(指针指出数组的位置和数据类型)作为一个参数,将数组长度作为第二个参数。这样便给函数提供了找到所有数据所需的信息。
- 还有另一种给函数提供所需信息的方法,即指定元素区间,这样可以通过传递两个指针来完成,一个指针标识数组开头,另一个指针表示数组的尾部。
double elboud[20];
// 则指针elboud和elboud + 20 定义了区间,首先数据名指向第一个元素,表达式elboud + 20指向数组结尾后面的一个位置
// STL使用了超尾的概念来指定区间,对于数组,标识数组结尾的参数将是指向最后一个元素后面的指针。
7.3.5 指针和const
- 有两种方式将const关键字用于指针,第一种方法是让指针指向一个常量对象,这样可以防止使用该指针来修改所指向的值;第二种方法是将指针本身声明为常量,这样可以防止改变指针指向的位置。
// 声明一个指向常量的指针
int age = 39;
const int *ptr = &age; // 该声明指出,ptr指向一个const int ,因此不能使用ptr来修改这个值,换句话说*ptr的值为const,不能被修改
// 有一个很微妙的问题,ptr的声明只是意味着不能通过ptr去修改age,age的值本身并不是一个常量,可以使用age变量去修改原来age的值。
- 以前都是将常规变量的地址赋值给常规指针,而上面将常规变量的地址赋值给指向const 的指针。因此还有两种可能,将const变量的地址赋值给指向const的指针,将const地址赋值给常规指针。这两种操作都可行嘛?第一种可行,第二种不可行
const float g_earth = 9.80
const float * pe = &g_earth; // 有效
float * pm = &g_earth; //无效,g_earth是常量,而pm是非const的,它可以去改g_earth
- 对于一级间接关系,即一维指针,将非const指针赋值给const指针这是可以的
int age = 39;
int * pd = &age;
const int * pt = pd; // 可以的
- 然而进入两级间接关系时,即二维指针,将非const指针赋值给const指针的方式不在安全。
int * p1;
const int **pp2;
pp2 = &p1; // 不允许,因为会导致可以使用p1来修改const数据
- 尽可能使用const,将指针参数声明为指向常量数据的指针有两条理由:1.可避免无意间修改数据导致的编程错误;2.使用const使得函数能够处理const和非const实参,否则函数只能接受非const数据
- 第二种使用const的方式使得无法修改指针的值
int sloth = 3;
const int * ps = &sloth; // 指针指向 const int,但指针本身的地址值,即指向可以变
int * const finger = &sloth; // 指针指向 int ,但是指针本身的地址值不能变
- 还可以声明指向const对象的const指针。
double trouble = 2.0E30;
const double * const stick = &trouble;
void show_array(const double arr[], int n);
// 该声明中使用const,意味着不能修改传递给他的数组中的值。只要只有一层间接关系,就可以使用这种技术,例如这里的数组元素是基本类型,但如果他们是指针或者指向指针的指针,则不能使用const。也就是说如果这里声明为一个二维数组,那就不能使用const了,二层间接关系中不能将非const地址赋值给const地址
7.4 函数和二维数组
int data[3][4] = {{1,2,3,4}, {2,3,4,}, {5,6,7,}};
int total = sum(data, 3);
// sum函数声明
int sum(int (*ar2)[4], int size);
- sum函数声明中int (*ar2)[4] 表示ar2是一个指向四个int元素构成的数组的指针。
- 圆括号必须要有,int *ar2[4] 表示ar2是一个数组,该数组由4个int 指针元素构成。
int sum(int ar2[][4], int size);
- 上面这个声明也表示ar2是一个指针,指向4个int元素构成的数组。因此指针类型指定了列数4,所以sum中size表示的是行数,没有传递列数
- 指针类型指定了列数,因此sum函数只能接收列数为4的数组。但行数是通过size指定,所以对行数没有限制。
- 在函数内部使用ar2表示的二维数组,最简单的办法就是将ar2看作二维数组的名称。
- *(ar2 + r) == ar2[r] 表示编号为r的元素,ar2 + r 表示指向编号为r的元素。
- ar2[r] 表示下标为r的元素,而在该声明中ar2指向数组,因此ar2[r]是第r个数组,包含四个int元素。
- 因此ar2[r][c] 表示的就是ar2[r] 数组中的第c个元素。
- 必须对指针ar2进行两次解引用才能得到数据。
- 最简单的办法是使用两次方括号 ar2[r][c] == ((ar2 + r) + c)
- ar2 + r 表示指向第r行的指针(一层指针都没解除),*(ar2 + r) 表示指向第r行的第一个元素的指针,有两层指针要解除,现在已经解除一层,但还是指针,只是变成了第r行第一个元素的指针。
- *(ar2+r) + c 表示指向第r行第c列的指针,也是最后一层指针,指向了具体的元素。
- *( *(ar2+r)+c) 两层指针全部解除,现在就是第r行第c列的元素。
- ar2 参数声明时没有使用const,因为这种技术只能用于指向基本类型的指针,而ar2是指向指针的指针。
7.5 函数和C-风格字符串
- 将字符串作为参数传递时意味着传递的是地址。
- 有关设计数组函数的知识也适用于字符串函数。
7.5.1 将C-风格字符串作为参数的函数
要将字符串作为参数传递给函数,则表示字符串的方式有三种:
- char 数组
- 用引号括起来的字符串常量(也称为字符串字面值)
- 被设置为字符串的地址的char指针
可以说是将字符串作为参数来传递,但实际上传递的是字符串第一个字符的地址。这意味着字符串函数原型应将其表示字符串的形参声明为char* 类型。
- C- 风格字符串与常规char数组之间一个重要区别是,字符串有内置的结束字符,前面说过包含字符,但不以空字符结尾的char数组只是数组,而不是字符串。这就不用将字符串长度作为参数传递给函数,而函数可以遍历字符串中的每个字符,直到遇到结尾空字符为止。
7.5.2 返回C-风格字符串的函数
函数无法返回一个字符串,但是可以返回字符串的地址,这样效率更高。
7.6 函数和结构
与数组不同的是结构名就只是结构名,要获得结构的地址,必须使用地址运算符&。&表示取地址运算符,也表示引用变量。
- 按值传递结构有一个缺点,如果结构非常大,则复制结构将增加内存要求,降低系统运行速度。出于这些原因,可以传递结构的地址,使用指针来访问结构的成员
- C++提供了第三种选择,按照引用传递。
7.6.1 传递和返回结构
while (cin >> rplace.x >> rplace.y)
// cin 是istream类的一个对象,cin >> rplace.x 时,会调用>>运算符重载函数并且会返回istream对象
// 也正是因为每次调用都返回istream对象,所以才可以链式调用,cin >> rplace.x >> rplace.y 这条语句最终返回的就是cin对象。
// 而在上面while 条件判断中时,会根据cin输入是否成功,被转换为bool值true或者false。
// 比如cin期待用户输入两个数字,如果用户输入了q,cin >> 将知道q不是数字,从而将q留在输入队列中,并返回一个被转换为false的值,导致循环结束。
7.6.3 传递结构的地址
void show_polar (const polar* pda)
{
using namespace std;
cout << pda->distance;
cout << pda->angle ;
// 通过结构指针访问结构成员,需要用->运算符
}
7.7 函数和string对象
虽然C-风格字符串和string对象的用途几乎相同,但与数组相比,string对象与结构的更相似。
void display(const string sa[], int n);
7.9 递归
递归即函数自己调用自己,c++不允许main()自己调用自己。递归就是首先层层往下不断调用自己,直到遇到终止条件,然后层层网上开始返回。
7.10 函数指针
与数据项相似,函数也有地址。函数的地址是存储其机器语言代码的内存的开始地址。通常这些地址对用户而言,既不重要,也没什么用处,但对程序而言,却很有用。例如,可以编写将另一个函数的地址作为参数的函数。
7.10.1 函数指针的基础知识
将一个函数传递给另一个函数,必须要完成下面的工作:
- 获取函数的地址
- 声明一个函数指针
- 使用函数指针来调用函数
- 获取函数地址:函数名表示的就是函数的地址。即think() 是一个函数,那么think就是函数的地址。
- 声明函数指针:首先指定指向的函数类型,这意味着声明应该指定函数的返回类型以及函数的特征标(参数列表)。也就是说声明应该像函数原型那样指出有关函数的信息。
// 函数原型
double pam(int);
// 函数指针
double (*pf) (int)
// 用(*pf) 替换了pam,由于pam是函数,因此(*pf)也是函数。如果(*pf)是函数,那么pf就是函数指针。
- 使用指针来调用函数:前面讲过,(*pf)扮演的角色与函数名相同,因此使用(*pf)时,只需要将他看作函数名即可。
double pam(int);
double (*pf)(int);
pf = pam; // 赋值,pf指向了一个函数,赋值是要将函数名赋值给函数指针,pf才是函数指针
double x = pam(4);
double y = (*pf)(5); // 通过函数指针调用其指向的函数
double z = pf(5); // C++也允许像使用函数名那样使用pf
// 函数原型
const double* f1(const double [], int);
// 函数指针
const double* (*p1)(const double * , int);
// 可以在声明的同时进行初始化
const double* (*p1)(const double * , int) = f1;
// c++11的自动推导功能
auto p2 = f1;
// 函数指针数组
// 函数原型
const double* f1(const double ar[], int n);
const double* f2(const double [], int);
const double* f3(const double *, int);
// 函数指针数组
const double* (*pa[3])(const double *, int);
// 声明的同时,初始化
const double* (*pa[3])(const double *, int) = {f1, f2, f3};
[ ]运算符的优先级高于星号运算符,因此 *pa[3] 表示pa是一个数组,该数组有三个指针元素。而上面的声明就指出了每个指针指向的是什么。 那这时pa就不是函数指针了,而是指向函数指针的指针,因为pa是数组名,数组名是指向第一个元素的指针。
// 使用函数指针数组
pa[0](av, 3);
(*pa[1])(av, 3);
7.10.4 使用typedef进行简化
typedef能让你创建类型别名。
// 将p_fum声明为函数指针类型的别名
typedef const double * (*p_fun)(const double *, int); // p_func是函数指针类型别名
p_func p1 = f1;
p_func pa[3] = {f1, f2, f3}; // pa是一个有三个函数指针的数组
p_func (*pd)[3] = &pa; // pd指向一个有三个函数指针元素的数组,是数组指针
第八章 函数探幽
第十章 对象和类
10.1 过程性变成和面向对象编程
面向对象编程(OOP)最重要的特性:
- 抽象
- 封装和数据隐藏
- 多态
- 继承
- 代码的可重用性
- 面向对象编程:首先考虑数据以及如何使用这些数据,比如首先从用户的角度考虑对象—描述对象所需的数据以及描述用户与数据交互所需的操作。
- 过程性编程:首先考虑遵循的步骤,然后考虑如何表示数据
10.2 抽象和类
10.2.1 类型是什么
类型是什么?拥有共同的特征、属性、操作的某些东西。C++中基本类型完成了三项工作:
- 决定数据对象所需的内存
- 决定如何解释内存中的位(long和float在内存中占用的位数相同,但是将他们转换为数值的方法不同)
- 决定数据对象能执行的操作或方法
10.2.2 C++中的类
C++ 中的类是一种能够将抽象的东西转换为用户自定义的类型的工具,可以将抽象的东西描述为所拥有的属性和能执行的操作。
定义类,一般来说,类规范由两个部分组成:
- 类声明:以数据成员的方式描述数据部分,以成员函数(也被称为方法)的方式描述公有接口。
- 类方法定义:描述如何实现类成员函数
简单来说,类声明提供了类的蓝图,而方法定义则提供了细节。
接口就是一个共享框架,用于两个对象之间进行交互和互操作的,通过这个接口一个对象可以和另一个对象交互或者操作另一个对象。
类里面的成员函数也被称为接口,分公共接口和私有接口。用户可以通过公共接口来和对象进行交互,但是私有接口不行。私有接口只能类自身调用,比如给公共接口调用。
通常C++程序员将接口的声明放在头文件中,并将实现(类方法的代码)放在源码文件中。
能够将数据和方法组合成一个单元是类最吸引人的特性。
// stock00.h
// version 00
#ifndef STOCK00_H_
#define STOCK00_H_
#include <string>
class Stock // class declaration
{
private:
std::string company;
long shares;
double share_val;
double total_val;
void set_tot() {total_val = share * share_val; }
public:
void update(double price);
void show();
}; // note semicolon at the end
#endif
// #ifndef .... #endif 是为了防止头文件重复引用
访问控制
关键字public 和private 描述了对类成员的访问控制。使用类对象的程序都可以直接访问公有部分,但只能通过公有成员函数(或者友元)来访问对象的私有成员。防止程序直接访问数据被称为数据隐藏。
要修改类的私有成员,只能通过类的公有成员函数。因此公有成员函数是程序和对象的私有成员之间的桥梁,提供了对象和程序之间的接口。
类设计尽可能将公有接口和实现细节分开,公有接口表示设计的抽象组件。将实现细节放在一起并和抽象分开被称为封装。数据隐藏也是一种封装(实现细节放到私有部分)。其实就是类的声明放在头文件中,而类中所有公有接口的实现放在.cpp文件中。当把这个类给别人使用时只需给头文件就行。那么他就看不到具体的公有接口实现,只看得到公有接口的抽象,也就是这些公有接口叫什么名字,有什么功能,怎么调用。
控制对成员的访问:公有还是私有
隐藏数据是OOP的主要目标之一,因此数据项通常放在私有部分。组成类接口的成员函数放在公有部分。否则就无法从程序中调用这些函数。不必在类中声明使用关键字private,因为这是类对象的默认访问控制。
类和结构
类描述看上去很像是包含成员函数以及public和private可见性标签的结构声明。实际上,C++对结构进行了扩展,使之具有与类相同的特性。他们之间唯一的区别是,结构的默认访问类型是public,而类是private。
10.2.3 实现成员函数
创建一个类一般分为两部分,一部分是类声明(声明成员数据、成员函数(函数原型)),一部分是对类声明中的成员函数进行代码实现(函数定义)。
成员函数的定义和常规函数定义非常相似,有函数体和函数头,也可以有返回类型和参数。但他们还有两个特殊特征:
- 定义成员函数时,使用作用域解析运算符(::)来标识函数所属的类
- 类方法可以访问类的private组件
void Stock::update(double price)
{
....
}
// 这不仅将update标识成员函数,还意味着可以将另一个类的成员函数也命名为update,通过类名的不同来防止重复
stock类的其他成员函数不必使用作用域解析运算符,就可以使用update方法,因为他们属于同一个类。
类方法的完整名称中包含类名,Stock::update是函数的限定名,而简单的update是全名的缩写。他只能在类作用域中使用。
方法的第二个特点是可以访问类的私有成员。
// 需要包含头文件,让编译器能够访问类声明
#include <stock00.h>
void Stock::update(double price)
{
...
}
这上面的代码中要包含类的头文件,这样在其他文件中包含该头文件时,编译器可以访问对应的类定义。
内联方法
其定义位于类声明中的函数都将自动成为内联函数。也就是把函数的实现细节直接放到了类声明中。类声明常将短小的成员函数作为内联函数。也可以在类声明之外定义成员函数,并使其成为内联函数,只需要在类实现部分中定义函数时使用inline限定符(放到函数头的最前面)。
- 内联函数的特殊规则要求:在每个使用他们的文件中都对其进行定义,也就是说在当前文件中声明了一个内联函数,就必须在当前文件对其进行定义,不能到其他文件定义。确保内联定义对多文件程序中的所有文件都可用,最简便的方法是将内联函数的定义直接放到类的头文件中
- 根据改写规则(rewrite rule):在类声明中定义方法等同于用原型替换方法定义,然后在类声明的后面将定义改写为内联函数。
class Stock
{
private:
void set_ot() { m_total = 10;} // 这种方式C++会直接标识为内联函数
}
// 表示内联函数的第二种方式
class Stock
{
private:
void set_ot();
};
inline void Stock::set_ot()
{
......
}
方法使用哪个对象
- 所创建的每个新对象都有自己的存储空间,用于存储其内部变量和类成员。但同一个类的所有对象共享同一组类方法。假设kate和joe都是Stock对象,则kate.shares将占用一个内存块,而joe.shares占用另一个内存块。但kate.show()和joe.show()都调用同一个方法,也就是说他们将执行同一个代码块,只是这些代码块用于不同的数据。
10.3类的构造函数和析构函数
C++中程序只能通过成员函数来访问数据成员,因此需要设计合适的成员函数,才能成功的将对象初始化。
一般来说,最好是在创建对象时对它进行初始化。C++提供了一个特殊成员函数–类构造函数,专门用于构造新对象、将值赋给它们的数据成员。类构造函数名称和类名相同。构造函数没有返回值,也没有声明返回类型。
10.3.1 声明和定义构造函数
// 函数原型,可以有默认值,原型位于类声明的公共部分
Stock(const string& co, long n = 0, double pr = 0.0);
// .cpp文件中 对构造函数的定义
Stock::Stock(const string& co, long n = 0, double pr = 0.0)
{
.....
}
// 上述代码和普通函数大体相同,区别在于程序声明对象时,将自动调用构造函数
// 需要注意:类构造函数参数名称不能和类数据成员名称相同,最好将类数据成员名称的前面加上m_
10.3.2 使用构造函数
两种使用构造函数来初始化对象的方式,第一种方式是显示的调用构造函数,第二种是隐式的调用构造函数。
// 显示调用
Stock food = Stcok("aa", 250, 1.25);
// 隐式调用
Stock garment("bbb", 50, 2.56);
// 每次创建类对象或者使用new动态分配内存时,C++都使用类构造函数
Stock *p = new Stock("aaa", 23, 2.3);
// 构造函数是用来构造对象的,不能用对象来调用构造函数,因为在用构造函数构造出对象之前,对象是不存在的。
10.3.3 默认构造函数
默认构造函数是在未提供显示初始值时,用来创建对象的构造函数。如果没有提供任何构造函数,C++将自动提供默认构造函数。
Stock pert; // 使用默认构造函数
// 默认构造函数没有参数,就创建对象,但不初始化其成员,这和下面的语句创建x,但没有给其提供值一样
int x;
// 默认构造函数
Stock Stock() {}
// 当且仅当没有定义任何构造函数时,编译器才会提供默认构造函数。为类定义了构造函数后,程序员就必须为其提供默认构造函数。也就是说提供了带参数的构造函数后,还有显示声明无参的默认构造函数。因为当我们定义了有参的构造函数后,编译器不会提供默认构造函数,那如果我们想创建对象,但又不显示初始化(提供参数),那么将报错。
// 定义默认构造函数的方式有两种:一种是给所有参数提供默认值,一种是定一个没有参数的构造函数
Stock(int a = 0, double c = 1.1) {}
10.3.4 析构函数
程序运行结束,对象过期,程序将自动调用析构函数完成清理工作。析构函数名和类名一样,前面加~号,且没有参数。
~Stock() {}
如果程序员没有提供析构函数,编译器将隐式的声明一个默认析构函数,并在发现导致对象被删除的代码后,提供默认析构函数的定义。
什么时候调用析构函数呢?由编译器决定,不应该在代码中显示调用析构函数。

10.3.5 改进Stock类
列表初始化类对象 C++11 特性
// 列表初始化对象,只要提供和某个构造函数参数列表匹配的内容并用花括号括起来 就可以
Stock hot = {"sss", 100, 45.2}; // 调用 参数列表匹配的构造函数
Stock rty {"asas"};
Stock temp {}; // 调用默认构造函数
const成员函数
const Stock land = Stock("sss");
land.show(); // 编译器拒绝第二行,报错
因为land对象是常对象,show函数代码无法确保调用对象不被修改。我们之前可以通过函数参数声明为const 引用或者指向const的指针来解决这种问题。但这里存在语法问题,show函数没有参数,这时需要一种新语法来保证函数不会修改调用对象,C++的解决方案是将const关键字放在函数的括号后面。
// show函数声明
void show() const ;
// show函数定义
void Stock::show() const
以这种方式声明和定义的类函数被称为const成员函数,就像应该尽可能将const引用和指针用作函数形参一样,只要类方法不修改调用对象,就应该将其声明为const。
10.3.6 构造函数和析构函数小结
如果构造函数只有一个参数,则将对象初始化为一个与参数类型相同的值时,该构造函数将被调用。
Bozo(int num) {}; // 单参数构造函数
Bozo tub = 32; // 构造函数将被调用
10.4 this指针
// 看下这个例子
const Stock & Stock::topval(const Stock& s) const
{
if (s.total_val > total_val)
return s;
else
return ????; // 这里返回什么,返回this指针解引用
}
this指针指向用来调用成员函数的对象(this被作为隐藏参数传递给方法)。这样调用函数stock1.topval(stock2) 将this设置为stock1的地址。所有类的方法都将this 指针设置为调用它的对象的地址。topval() 中的total_val 只不过是this->total_val的简写。
每个成员函数(包括构造函数和析构函数)都有一个this指针,this指针指向调用对象,如果方法需要引用整个调用对象,则可以使用表达式*this。在函数括号后面使用const限定符将this限定为const,这样将不能使用this来修改对象的值。
10.5 对象数组
Stock mystuff[4]; // 创建四个对象
当程序创建未被显示初始化的对象时,总是调用默认构造函数。上述声明要求,这个类要么没有显示的定义任何构造函数(这种情况下,编译器给一个隐式的默认构造函数),要么定义了个显示的默认构造函数。
可以用构造函数来初始化数组元素,这种情况下,必须为每个元素调用构造函数。
Stock stocks[2] = {
Stock("aa", 1),
Stock("bb", 2)
};
如果只是显示初始化部分数组元素,则剩下的元素将使用默认构造函数初始化。

10.6 类作用域


同样在定义成员函数时,必须使用作用域解析运算符
void Stock::show()
{}


10.6.1 作用域为类的常量
class Bakery
{
private:
const int Months = 12; // 错误
double costs[Months];
...
声明类只描述了对象的形式,并没有创建对象,因此,在创建对象前,将没有用于存储值的空间。
有两种方式可以实现上述目标:第一个是在类中声明一个枚举
class Bakery
{
private:
enum {Months = 12}; // 这里声明一个枚举,没有创建枚举变量
double costs[Months];
...

第二个是使用static关键字(C++提供了另一种在类中定义常量的方式)

10.6.2 作用域内枚举(C++11 特性)


10.7 抽象数据类型


















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









