






数据库关闭问题分析及解决
postgres数据库执行retart命令后,偶现错误
1 the database system is shutting down
2 the database system is starting up
一 数据库的关闭方式
| 关闭方式种类 | 方式含义 | 命令 |
|---|---|---|
| smart智能关闭模式 | 但凡有外部连接未结束,就需要等待这些连接结束后才会开始关闭数据库 | pg_ctl stop -m smart |
| fast快速关闭模式 | 通过向所有活动会话发送SIGTERM信号来结束这些会话 | pg_ctl stop -m fast |
| immediate直接关闭模式 | 向所有子进程发送SIGQUIT信号。通过这种方式关闭数据库,完整性是不可靠的。再次启动数据库时将会重放WAL日志进行恢复。 | pg_ctl stop -m immediate |
1 smart智能关闭模式
打开两个客户端,其中客户端1打开会话,客户端2用smart方式关闭数据库
客户端1
psql
psql (14.12 (Ubuntu 14.12-1.pgdg22.04+1))
Type "help" for help.
postgres=#
客户端2:
/usr/lib/postgresql/14/bin/pg_ctl -D /etc/postgresql/14/main stop -m smart
waiting for server to shut down............................................................... failed
pg_ctl: server does not shut down
HINT: The "-m fast" option immediately disconnects sessions rather than
waiting for session-initiated disconnection.
如果会话不关闭,数据库就无法关闭。如果会话自动退出,数据库就会正常关闭。
2 fast快速关闭模式
客户端1仍然有会话
客户端2:
/usr/lib/postgresql/14/bin/pg_ctl -D /etc/postgresql/14/main stop -m fast
waiting for server to shut down.... done
server stopped
看关闭日志:
LOG:"received fast shutdown request",,,,,,,,,"","postmaster",,0
LOG:"aborting any active transactions",,,,,,,,,"","postmaster",,0
FATAL:"terminating connection due to administrator command",,,,,,,,,"psql","client backend",,0
LOG:"shutting down",,,,,,,,,"","checkpointer",,0
LOG:"database system is shut down",,,,,,,,,"","postmaster",,0
看启动日志:
LOG:"database system was shut down at 2024-07-09 10:29:51 CST",,,,,,,,,"","startup",,0
LOG:"database system is ready to accept connections",,,,,,,,,"","postmaster",,0
快速关闭数据库, 断开客户端的连接(terminating connection due to administrator command),让已有的事务回滚,然后正常关闭数据库。
数据库启动时也是正常启动
3 immediate直接关闭模式
客户端1有会话
客户端2:
/usr/lib/postgresql/14/bin/pg_ctl -D /etc/postgresql/14/main stop -m immediate
waiting for server to shut down.... done
server stopped
看关闭日志:
LOG,00000,"received immediate shutdown request",,,,,,,,,"","postmaster",,0
LOG,00000,"database system is shut down",,,,,,,,,"","postmaster",,0
重启后数据库日志
LOG,00000,"database system was interrupted; last known up at 2024-07-09 11:43:31 CST",,,,,,,,,"","startup",,0
LOG,00000,"database system was not properly shut down; automatic recovery in progress",,,,,,,,,"","startup",,0
LOG,00000,"redo starts at 23/65021AC8",,,,,,,,,"","startup",,0
LOG,00000,"invalid record length at 23/65021D68: wanted 24, got 0",,,,,,,,,"","startup",,0
LOG,00000,"redo done at 23/65021D40 system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s",,,,,,,,,"","startup",,0
LOG,00000,"database system is ready to accept connections",,,,,,,,,"","postmaster",,0
立即关闭数据库,立即停止数据库进程,直接退出,下次启动时会进行实例恢复。
小结:
smart最为安全,但最慢
fast强制中断会话,而不管有操作有没有提交,没有加参数就是这种关库方式
immediate最暴力的方式,不管数据有没有落盘,就直接关掉, 待启动时进行实例恢复, 如果在关库前有大量的事务没有写入磁盘, 那这个恢复过程可能会非常的漫长。
二 重启问题分析
---------------2024-07-05 18:03:11.993-》2024-07-05 18:03:12.015
received fast shutdown request----1
aborting any active transactions-----------1
terminating connection due to administrator command, ---152
----------2024-07-05 18:03:12.087-》2024-07-05 18:08:19.228
connection received ---11701
the database system is shutting down,----11472
background worker "logical replication launcher" (PID 174581) exited with exit code 1,---1
incomplete startup packet
----------------------2024-07-05 18:09:06.759-》2024-07-05 18:09:06.814
ending log output to stderr ---1
database system was shut down at 2024-07-05 18:09:03 CST ---1
------------------------2024-07-05 18:09:06.816-》2024-07-05 18:09:06.848
connection received ----23
the database system is starting up --22
-----------------------------2024-07-05 18:09:06.86-》
database system is ready to accept connections
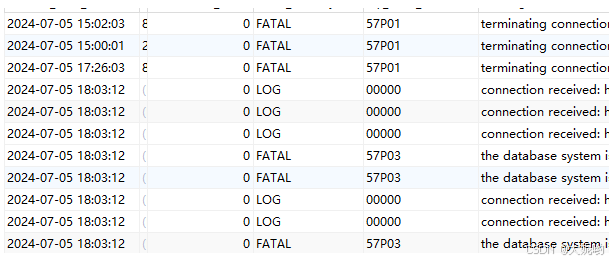
分析:
库log_connections=on会记录每一次尝试对服务器的连接被记录
执行完restart命令后:
the database system is shutting down:
先杀已有的连接,在杀连接的时候依然不停的有连接要连数据库,基本每连一次数据库就报错the database system is shutting down
所以导致数据库停不下来的主要原因是每秒近40个的服务连接请求(11701/307约等于38),因为没有成功断开导致数据库停不下来
把数据库进程kill完之后,重新start库:
the database system is starting up:
数据库系统正在进行重要的操作,例如崩溃恢复、数据恢复或重建索引等,这些操作需要一定的时间来完成。
结论:
处理过程:把postgres进程全部杀干净,杀掉之后重启库。重启成功
注意事项:之后重启数据库操作,保险起见应在服务关闭状态下执行

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









