







 该博客介绍了猿人学第一届爬虫比赛中第四题的解决方案,涉及处理雪碧图和样式干扰的问题。作者通过分析网页源码、抓包和动态生成j_key来获取隐藏图片信息,最终实现图片排序和数字转换。
该博客介绍了猿人学第一届爬虫比赛中第四题的解决方案,涉及处理雪碧图和样式干扰的问题。作者通过分析网页源码、抓包和动态生成j_key来获取隐藏图片信息,最终实现图片排序和数字转换。
猿人学第一届爬虫比赛第四题(雪碧图、样式干扰)
📣 概况
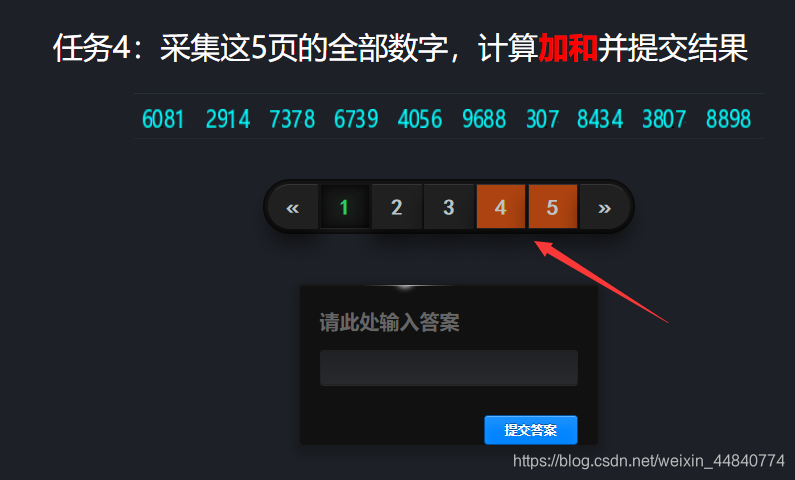
本题与前面几题要求一致,依旧是采集5页的全部数字,计算加和并提交结果。
可以发现,数据是以图片形式展示,并且第四第五页是无法通过页面查看的,
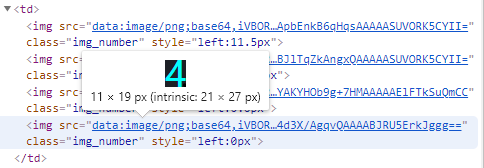

查看网页源码发现数据并不在源码中,抓包分析发现请求了两个文件,其中logininfo返回了登录信息,文件4返回了一串json数据。
拷贝其中的info信息,在浏览器中执行,发现info包含的是渲染图片的html代码,与题目第一页的数据比较,可以发现这些图片的顺序与网页展示的顺序不同,数量也不一致。


通过对网页的元素分析可以发现,网页通过display:none和left对某些图片进行了隐藏和移动。

通过initiator溯源请求,
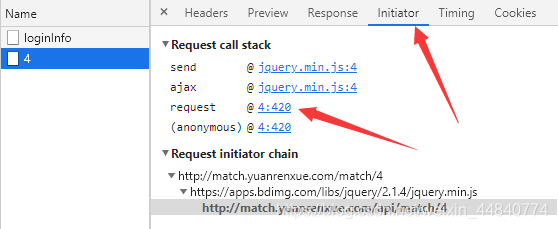
可以看到,此处对j_key通过css进行了隐藏,而j_key=’.’ + hex_md5(btoa(data.key + data.value).replace(/=/g, ‘’));。
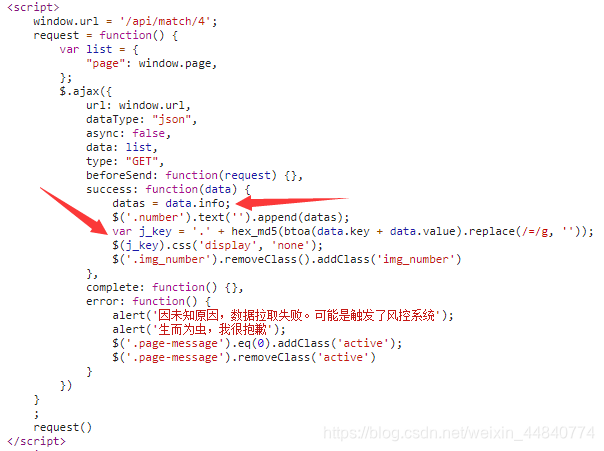
前面抓包时已经知道key和value都来自json数据,此处通过btoa函数进行了base64加密,然后再将=替换成空字符串后进行了md5加密,可以通过浏览器打印分析一下j_key.
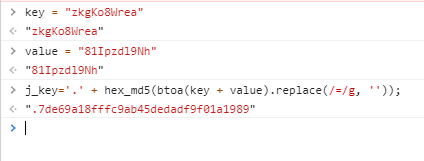
得到了一个32位的字符,在info信息中进行匹配,发现有23处匹配到了一样的字符.
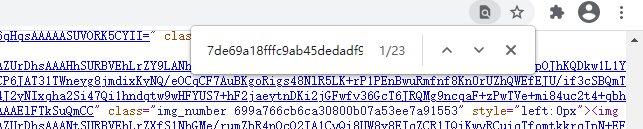
仔细研究后发现,在第一页出现了39张数字图片,而info中包含了62张图片,而62-39刚好等于23,所以这23张图片应该就是网页隐藏的图片。

刷新几次网页发现,每次的j_key都不相同,所以要动态生成。通过python构造如下:
def get_res(page):
url = 'http://match.yuanrenxue.com/api/match/4?page=' + str(page)
res = requests.get(url, headers=headers).json()
k = res['key']
v = res['value']
pat = '<td>(.*?)</td>'
td_list = re.compile(pat).findall(res['info'])
return k, v, td_list
def make_js(k, v, td_list):
kv = k + v
b64_kv = base64.encodebytes(bytes(kv.encode('utf-8')) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









