






 Ho-Kashyap算法是针对线性可分问题的一种优化方法,它结合最小化均方误差和保证线性可分性。通过迭代更新权重向量a和超参数b,确保找到的解既能最小化误差,又能保证线性可分。算法通过设置迭代条件和避免负梯度来确保在线性可分问题中收敛到一个合适的解。当问题线性可分时,算法能够收敛到满足条件的解,即预测值始终大于0。此外,算法还设定了一个停止条件,当误差绝对值小于初始b的最小值时结束迭代,保证了解的稳定性。
Ho-Kashyap算法是针对线性可分问题的一种优化方法,它结合最小化均方误差和保证线性可分性。通过迭代更新权重向量a和超参数b,确保找到的解既能最小化误差,又能保证线性可分。算法通过设置迭代条件和避免负梯度来确保在线性可分问题中收敛到一个合适的解。当问题线性可分时,算法能够收敛到满足条件的解,即预测值始终大于0。此外,算法还设定了一个停止条件,当误差绝对值小于初始b的最小值时结束迭代,保证了解的稳定性。
Ho-Kashyap 算法
任务:给定样本
{
x
1
,
x
2
,
.
.
.
,
x
n
}
,
x
i
=
[
x
i
1
,
x
i
2
,
⋯
,
x
i
d
]
T
\{x_1,x_2,...,x_n\},x_i=[x_{i1},x_{i_2},\cdots,x_{id}]^T
{x1,x2,...,xn},xi=[xi1,xi2,⋯,xid]T,设每个样本属于两类中的某一类
{
1
,
−
1
}
\{1,-1\}
{1,−1},用线性模型对样本进行划分。
方法:
将每个
x
i
x_i
xi转化成
y
i
y_i
yi,如果
x
i
x_i
xi属于{1}类,
y
i
=
[
1
,
x
i
1
,
x
i
2
,
⋯
,
x
i
d
]
T
y_i=[1,x_{i1},x_{i_2},\cdots,x_{id}]^T
yi=[1,xi1,xi2,⋯,xid]T,如果属于{-1}类,则
y
i
=
[
−
1
,
−
x
i
1
,
−
x
i
2
,
⋯
,
−
x
i
d
]
T
y_i=[-1,-x_{i1},-x_{i_2},\cdots,-x_{id}]^T
yi=[−1,−xi1,−xi2,⋯,−xid]T。
如果使用感知器方法,即寻找一个权向量
a
a
a,使得对于所有i都有
a
T
y
i
=
b
i
>
0
a^Ty_i=b_i>0
aTyi=bi>0,那么可以使用感知器准则函数县官的优化方法,如批处理感知器算法等:
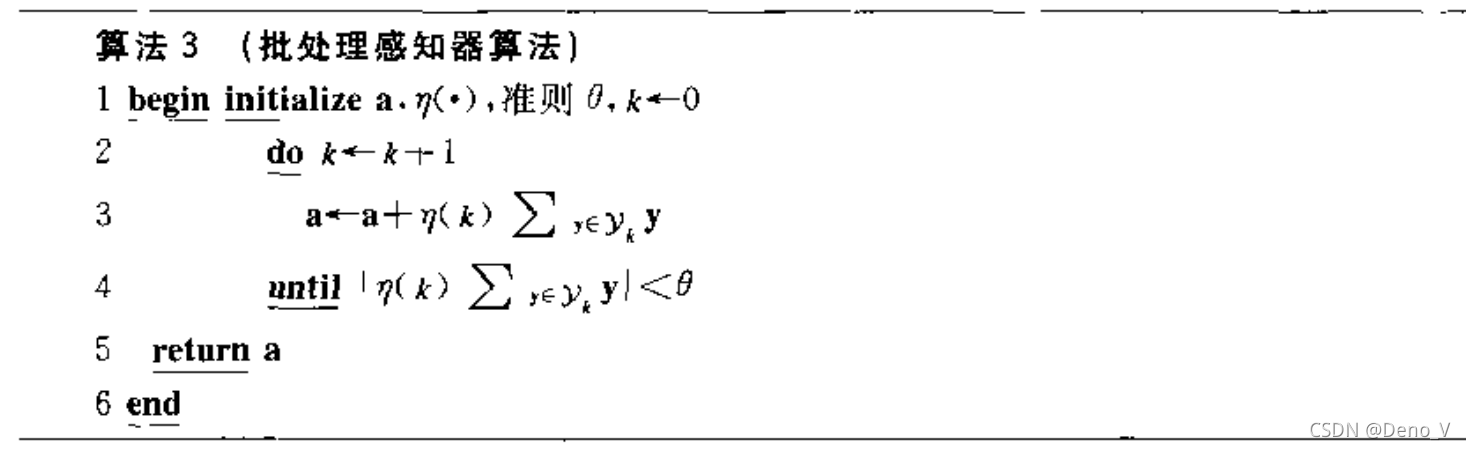

但是使用感知器的方法对于线性不可分的样本将会十分棘手,可能会导致算法无法收敛。
对于线性不可分的问题常常采用最小化均方误差的方法进行优化,例如需要最小化:
J
s
=
∥
Y
a
−
b
∥
2
,
Y
=
[
y
1
,
y
2
,
⋯
,
y
n
]
T
,
b
>
0
为
超
参
(
裕
度
)
J_s=\|Ya-b\|^2,Y=[y_1,y_2,\cdots,y_n]^T,b>0为超参(裕度)
Js=∥Ya−b∥2,Y=[y1,y2,⋯,yn]T,b>0为超参(裕度)
▽
a
J
s
=
2
Y
T
(
Y
a
−
b
)
\triangledown_a J_s = 2Y^T(Ya-b)
▽aJs=2YT(Ya−b)采用这种梯度迭代更新a的方法例如:

但是最小化均方误差的算法对于本来就是线性可分的问题表现的并不优秀例如:
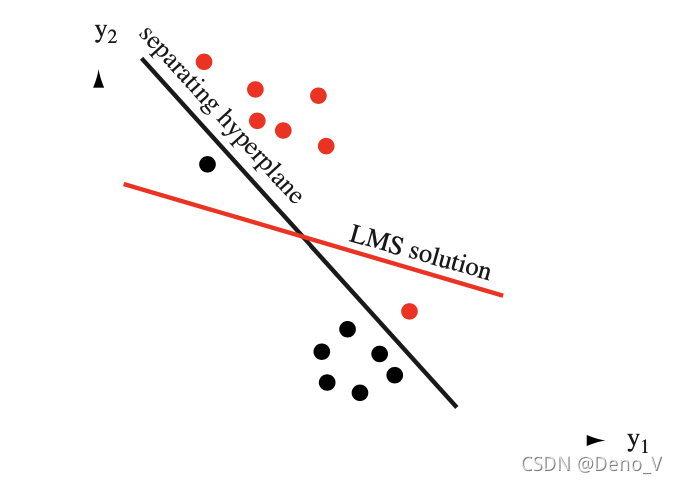
找到MSE最小的解却不是一个可分的解。
Ho-Kashyap Algorithm在采用最小均方误差的前提下又保证对于所有线性可分的问题,必然找到可分的解。
定义:
J
s
=
∥
Y
a
−
b
∥
2
,
Y
=
[
y
1
,
y
2
,
⋯
,
y
n
]
T
J_s=\|Ya-b\|^2,Y=[y_1,y_2,\cdots,y_n]^T
Js=∥Ya−b∥2,Y=[y1,y2,⋯,yn]T
▽
a
J
s
=
2
Y
T
(
Y
a
−
b
)
=
2
Y
T
e
\triangledown_a J_s = 2Y^T(Ya-b)=2Y^Te
▽aJs=2YT(Ya−b)=2YTe
▽
b
J
s
=
−
2
(
Y
a
−
b
)
=
−
2
e
\triangledown_b J_s = -2(Ya-b)=-2e
▽bJs=−2(Ya−b)=−2e其中e定义为误差向量。
HoK算法对b进行迭代优化,而直接让 ▽ a J s = 0 ⇔ Y T e = 0 ⇔ a = ( Y T Y ) − 1 Y T b = Y † b \triangledown_a J_s=0\Leftrightarrow Y^Te=0\Leftrightarrow a=(Y^TY)^{-1}Y^Tb=Y^\dag b ▽aJs=0⇔YTe=0⇔a=(YTY)−1YTb=Y†b(使用了伪逆)。
由于我们希望最终的解能线性可分,即
Y
a
^
=
b
^
>
0
Y\hat a=\hat b>0
Ya^=b^>0,所以我们希望迭代b的过程中,b不能小于0,这个通过初始化b并且在迭代过程中不允许b减小(仅保留对b的负梯度中正的部分)
b
(
k
+
1
)
=
b
(
k
)
+
η
(
k
)
▽
b
J
s
+
=
b
(
k
)
+
2
η
(
k
)
e
+
,
e
+
=
1
2
(
e
+
∣
e
∣
)
b(k+1)=b(k)+\eta(k)\triangledown_b J_s^+=b(k)+2\eta(k)e^+,e^+=\frac12 (e+|e|)
b(k+1)=b(k)+η(k)▽bJs+=b(k)+2η(k)e+,e+=21(e+∣e∣)
同时为了避免死循环设置了
k
m
a
x
k_{max}
kmax最大迭代次数
重点标记算法停止条件 a b s ( e ) ≤ b m i n abs(e)\le b_{min} abs(e)≤bmin , b m i n = m i n ( b ( 0 ) ) b_{min}=min(b(0)) bmin=min(b(0))即初始b中最小的元素,某个正数。

证明当 η ∈ ( 0 , 1 ) \eta\in(0,1) η∈(0,1)时,对于线性可分问题,HoK必然收敛到一个可分的解。
如果在迭代过程的第k步出现了 Y a ( k ) = b ( k ) Ya(k)=b(k) Ya(k)=b(k),即 e ( k ) = 0 e(k)=0 e(k)=0那么,此时算法已经终止,且由于b(k)>0,所以自然也找到了一个线性可分的解。
要担心的是如果出现了某种情况使得 e ( k ) e(k) e(k)中所有元素都小于等于0,且e(k)不为0向量。此时 e + ( k ) = 0 e^+(k)=0 e+(k)=0,算法将不会迭代更新,我们也无法判定是否找到了一个线性可分的解,或者线性可分的解是否存在。
幸运的是这种情况不会出现,因为令
▽
a
(
k
)
J
s
=
2
Y
T
(
Y
a
(
k
)
−
b
(
k
)
)
=
2
Y
T
e
(
k
)
=
0
⇔
Y
T
e
(
k
)
=
0
⇔
e
T
(
k
)
Y
=
0
\triangledown_{a(k)} J_s=2Y^T(Ya(k)-b(k))=2Y^Te(k)=0\Leftrightarrow Y^Te(k)=0\Leftrightarrow e^T(k)Y=0
▽a(k)Js=2YT(Ya(k)−b(k))=2YTe(k)=0⇔YTe(k)=0⇔eT(k)Y=0
假设问题是线性可分的,那么就存在
b
^
>
0
,
a
^
\hat b>0,\hat a
b^>0,a^,满足
Y
a
^
=
b
^
Y\hat a=\hat b
Ya^=b^。
进而
e
t
(
k
)
Y
a
^
=
0
=
e
t
(
k
)
b
^
e^t(k)Y\hat a=0=e^t(k)\hat b
et(k)Ya^=0=et(k)b^
由于
b
^
>
0
\hat b>0
b^>0所以e(k)必然为0向量,或者e(k)中有正有负。对于0向量我们可以说已经找到了一个线性可分的解。对于后者则可以继续优化,但是如果问题是线性可分的就绝对不会出现
e
(
k
)
e(k)
e(k)中所有元素都小于等于0且e(k)不为0向量的情况。
说明
Y
Y
†
YY^\dag
YY†是对称的,半正定的,满足:

有
e
(
k
)
=
Y
a
(
k
)
−
b
(
k
)
=
Y
Y
†
b
(
k
)
−
b
(
k
)
=
(
Y
Y
†
−
I
)
b
(
k
)
e(k)=Ya(k)-b(k)=YY^\dag b(k)-b(k)=(YY^\dag -I)b(k)
e(k)=Ya(k)−b(k)=YY†b(k)−b(k)=(YY†−I)b(k)
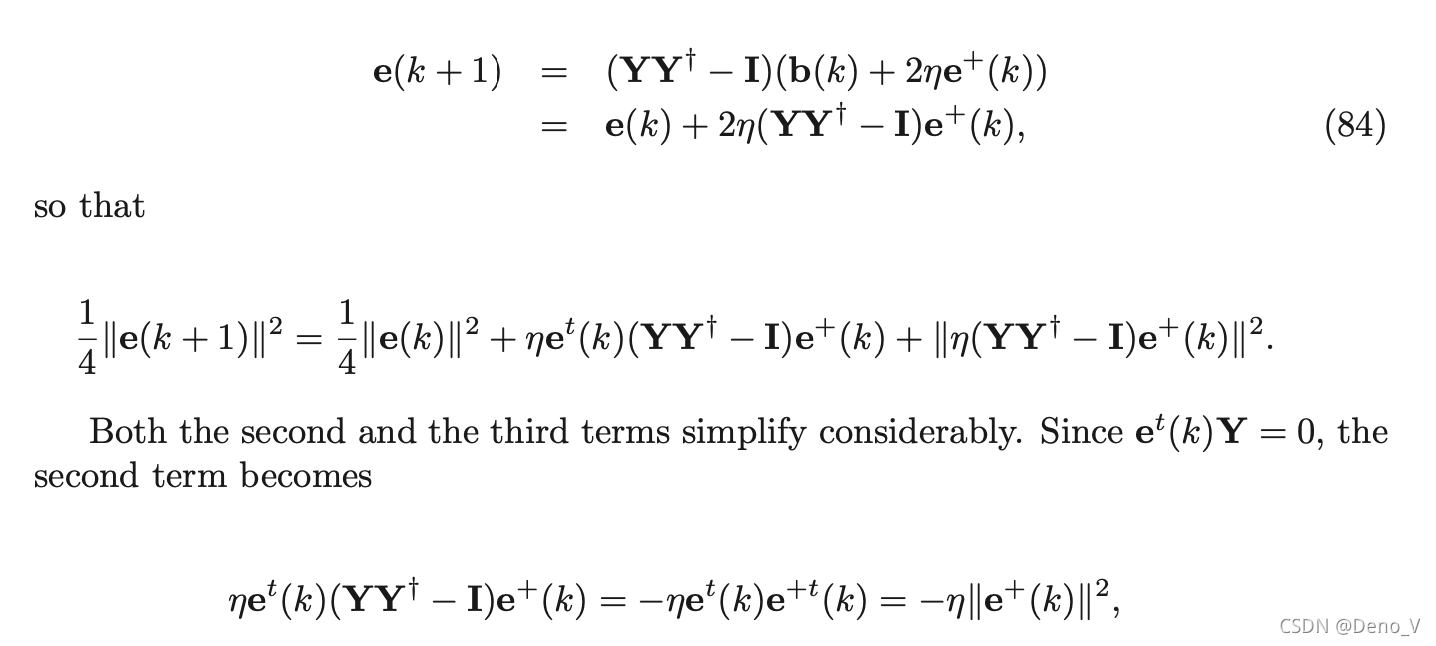
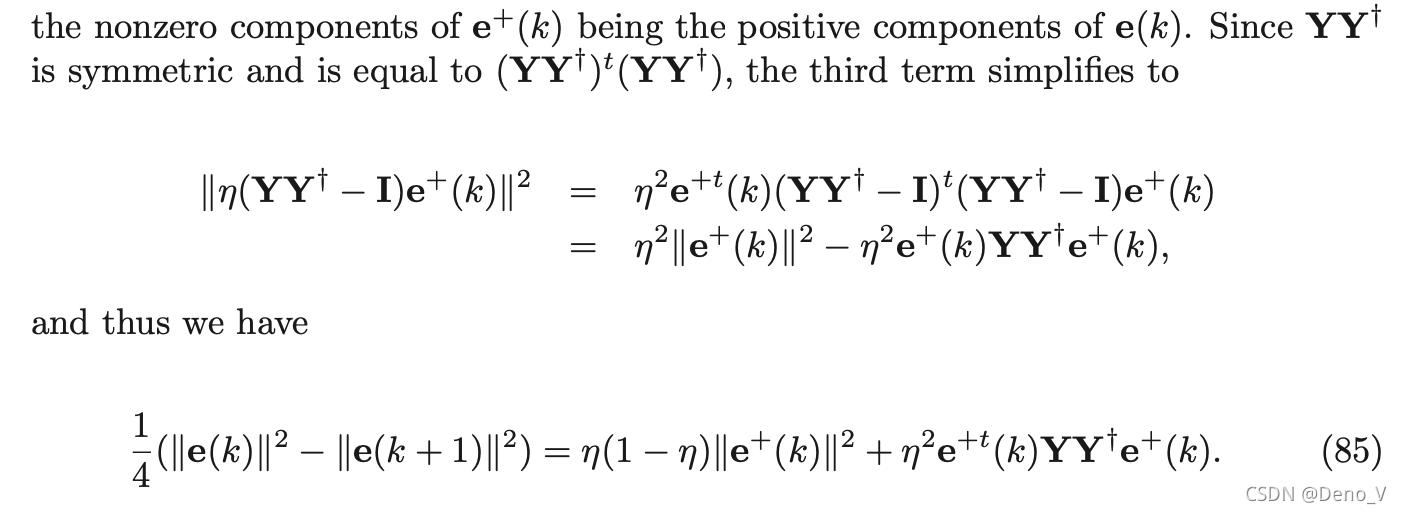
到这里为止说明了
∥
e
(
k
)
∥
\|e(k)\|
∥e(k)∥是单调递减的,又因为其有下界0,所以其必定是收敛的。
由于其收敛所以有:
lim
k
→
∞
η
(
1
−
η
)
∥
e
+
(
k
)
∥
2
+
η
2
e
+
t
(
k
)
Y
Y
†
e
+
(
k
)
=
0
\lim\limits_{k\to\infin} \eta(1-\eta)\|e^+(k)\|^2+\eta^2e^+t(k)YY^\dag e^+(k)=0
k→∞limη(1−η)∥e+(k)∥2+η2e+t(k)YY†e+(k)=0
当
η
∈
(
0
,
1
)
\eta\in(0,1)
η∈(0,1)时,第一项为正,由于
Y
Y
†
YY^\dag
YY†是对称的,半正定的,所以第二项也为正,进而
e
+
(
k
)
→
0
⇔
[
∣
e
(
k
)
∣
+
e
(
k
)
]
→
0
⇔
[
∣
e
(
k
)
∣
+
e
(
k
)
]
T
b
^
→
0
e^+(k)\to0\Leftrightarrow[|e(k)|+e(k)]\to 0\Leftrightarrow[|e(k)|+e(k)]^T\hat b\to 0
e+(k)→0⇔[∣e(k)∣+e(k)]→0⇔[∣e(k)∣+e(k)]Tb^→0
又有
e
t
(
k
)
b
^
=
0
e^t(k)\hat b=0
et(k)b^=0,故直接推出
∣
e
(
k
)
∣
→
0
,
e
(
k
)
→
0
|e(k)|\to 0,e(k)\to0
∣e(k)∣→0,e(k)→0。
到此证明了如果问题是线性可分的,那么该算法一定收敛到可分的解,且满足MSE的准则。
下面对上图中结束循环的条件 a b s ( e ( k ) ) < m i n ( b ( 0 ) ) abs(e(k))<min(b(0)) abs(e(k))<min(b(0))进行说明
事实上只要
Y
a
(
k
)
>
0
Ya(k)>0
Ya(k)>0就可以停止循环,
a
b
s
(
e
(
k
)
)
<
m
i
n
(
b
(
0
)
)
abs(e(k))<min(b(0))
abs(e(k))<min(b(0))是比
Y
a
(
k
)
>
0
Ya(k)>0
Ya(k)>0更严格的条件。
原因是:
Y
a
(
k
)
=
b
(
k
)
+
e
(
k
)
≥
b
(
0
)
+
e
(
k
)
)
≥
b
(
0
)
−
a
b
s
(
e
(
k
)
)
[
这
是
因
为
b
是
不
减
的
]
Ya(k)=b(k)+e(k)\ge b(0)+e(k))\ge b(0)-abs(e(k))\\ [这是因为b是不减的]
Ya(k)=b(k)+e(k)≥b(0)+e(k))≥b(0)−abs(e(k))[这是因为b是不减的]
当
a
b
s
(
e
(
k
)
)
<
m
i
n
(
b
(
0
)
)
abs(e(k))<min(b(0))
abs(e(k))<min(b(0))时,必然有:
Y
a
(
k
)
≥
b
(
0
)
−
a
b
s
(
e
(
k
)
)
>
0
Ya(k)\ge b(0)-abs(e(k))>0
Ya(k)≥b(0)−abs(e(k))>0
证毕。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









