







2021.12.1
基本流程:
准备工作——获取数据——解析内容——保存数据
准备工作:通过浏览器查看分析目标网页,学习编程基础规范
获取数据:通过HTTP库向目标站点发起请求,请求可以额外包含header等信息,若服务器能正常响应,会得到一个Response,便是所要获取的页面内容
解析内容:得到的内容可能是HTML、json等格式,可以用页面解析库、正则表达式等进行解析
保存数据:保存形式多样性,可为文本、存到数据库、或保存为特定格式的文本
2021.12.2
准备工作:
着重掌握:
user-Agent——用户浏览器版本等信息
cookie——读取、存储
编码规范:
第一行加入:#--coding:utf-8--或者#coding=utf-8
Python文件中可加入main函数用于测试:if_ name=="_ main _ ":
引入模块
引入自定义模块
from test1 import t1
引入系统模块
import sys
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式
import urllib.request, urllib.error # 制定url,获取网页数据
import xlwt # 进行excel操作
import sqlite3 # 进行sqlite数据库操作
2021.12.6
补充urllib
urllib 库用于操作网页 URL,并对网页的内容进行抓取处理
import urllib.request
# 获取get请求
# response = urllib.request.urlopen("http://www.baidu.com")
# print(response.read().decode("utf-8"))
# 获取post请求
# import urllib.parse
# data = bytes(urllib.parse.urlencode({"hello": "world"}), encoding="utf-8")
# response = urllib.request.urlopen("http://httpbin.org/post", data=data)
# print(response.read().decode("utf-8"))
# 超时异常处理
# try:
# response = urllib.request.urlopen("http://httpbin.org/get", timeout=0.01)
# print(response.read().decode("utf-8"))
# except urllib.error.URLError as e:
# print("time out")
# 获取头部信息
# response = urllib.request.urlopen("http://baidu.com")
# # print(response.status)
# print(response.getheader("Server"))
# url = "http://httpbin.org/post"
# headers = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
# }
# data = bytes(urllib.parse.urlencode({"name": "eric"}), encoding="utf-8")
# req = urllib.request.Request(url=url, data=data, headers=headers, method="POST")
# response = urllib.request.urlopen(req)
# print(response.read().decode("utf-8"))
# 访问豆瓣网
url = "http://douban.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
req = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
2021.12.7
补充BeautifulSoup
''
BeautifulSoup4将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup4
- Comment
'''
from bs4 import BeautifulSoup
file = open("./baidu.html", "rb") # rb:read bytes
html = file.read()
bs = BeautifulSoup(html, "html.parser") # 用BeautifulSoup指定解析器html.parser,解析html
# 1,Tag 标签及其内容:拿到他所找到的第一个内容
# print(bs.title)
# print(bs.a)
# print(bs.meta)
# print(bs.head)
# print(type(bs.head))
# 2,NavigableString 标签里的内容(字符串)
# print(bs.title.string)
# print(type(bs.title.string))
# print(type(bs.a.attrs)) # 拿到一个标签里的所有属性
# 3,BeautifulSoup 表示整个文档
# print(type(bs))
# print(bs)
# 4,Comment 是一个特殊的NavigableString,输出的内容不包含注释符号
# print(bs.a.string)
# print(type(bs.a.string))
# -------------------------
# 文档的遍历 获取特定标签的某一种内
# print(bs.head.contents) # 列表
# print(bs.head.contents[1])
# 更多内容 搜索BeautifulSoup文档
# 文档的搜索
# find_all()
# 字符串过滤:会查找与字符串完全匹配的内容
# t_list = bs.find_all("a")
import re
# 正则表达式搜索:使用search()方法来匹配内容
# t_list = bs.find_all(re.compile("a"))
# 1,方法:进入一个函数(方法),根据函数的要求来搜索(了解)
# def name_is_exists(tag):
# return tag.has_attr("name")
# t_list = bs.find_all(name_is_exists)
# for item in t_list:
# print(item)
# print(t_list)
# 2,kwargs 参数,根据标签内的参数查找
# t_list = bs.find_all(id="head")
# t_list = bs.find_all(class_=True)
# t_list = bs.find_all(href="http://news.baidu.com")
# print(t_list)
# 3,text参数,根据文本内容查找
# t_list = bs.find_all(text="hao123")
# t_list = bs.find_all(text=["hao123", "地图"])
# t_list = bs.find_all(text=re.compile("\d")) # 应用正则表达式来查找包含特定文本的内容(标签里的字符串)
# 4,limit 参数,限定查询的个数
# t_list = bs.find_all("a", limit=3)
# css选择器
# t_list = bs.select(".mnav")
# t_list = bs.select("#u1")
# t_list = bs.select("a[class='bri']")
# t_list = bs.select("head > title")
t_list = bs.select(".mnav ~ .bri")
print(t_list[0].get_text())
# t_list = bs.select('title') # 通过标签来查找
# t_list = bs.select(".mnav") # 通过类名来查找
# t_list = bs.select("#u1") # 通过id来查找
# t_list = bs.select("a[class='bri']") # 通过属性来查找
# t_list = bs.select("head > title") # 通过子标签查找
# t_list = bs.select(".mnav ~ .bri") # 通过兄弟节点查找
# print(t_list[0].get_text())
# for item in t_list:
# print(item)
2021.12.8
补充正则表达式
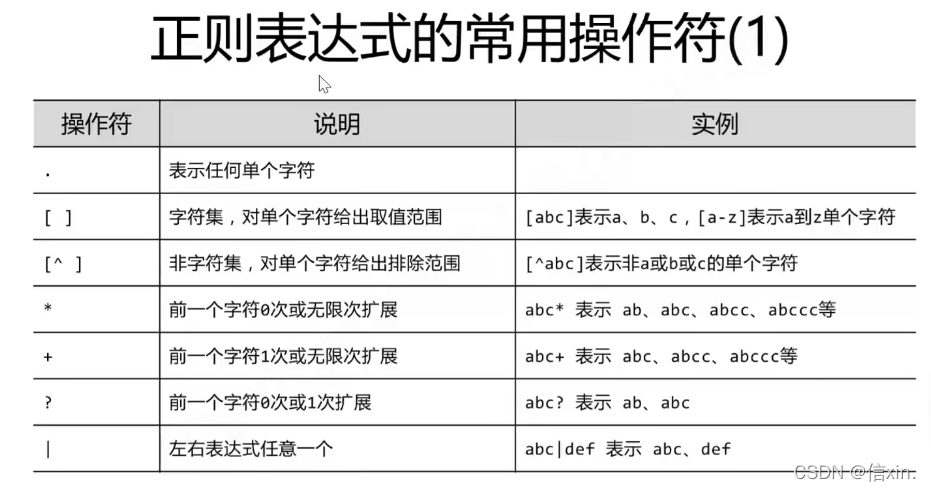
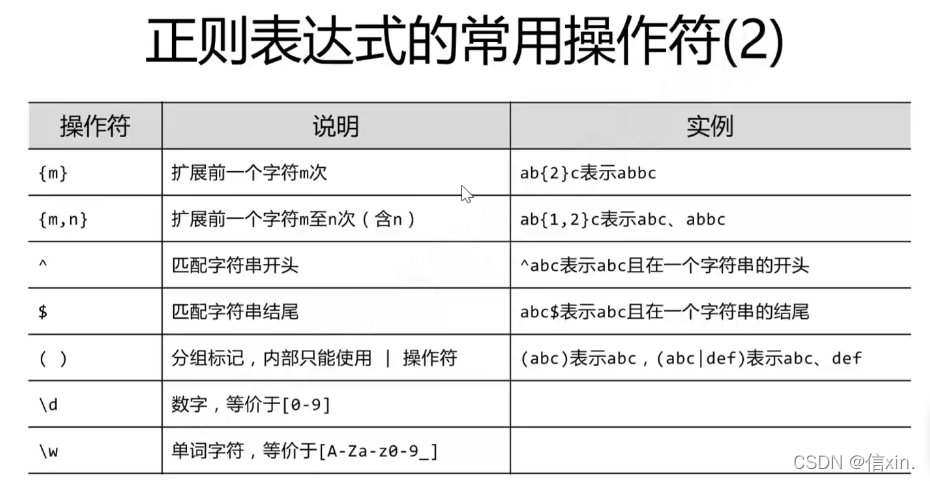

search():
re.search(“asd”, “Aasd”) # 参数1:规则,参数2:被校验的对象
findall():
re.findall(“a”, “ASDaDFGAa”) # 参数1:规则,参数2:被校验的对象
sub():
re.sub(“a”, “A”, “abcdcasd”) # 在参数3中a被A替换
建议在正则表达式中,被比较的字符串前面加r,不用担心转义字符的问题
a = r"\aacs-’"
2021.12.28
通过python保存数据到excel
import xlwt
workbook = xlwt.Workbook(encoding="utf-8") # 创建workbook对象
worksheet = workbook.add_sheet('sheet1') # 创建工作表
worksheet.write(0, 0, 'hello') # 写入参数,参数一:行,参数二:列,参数三:内容
workbook.save('student.xls') # 保存数据表


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









