



 本文介绍了Caffeine高性能本地缓存组件,探讨了其淘汰算法(如FIFO、LRU、LFU)以及Count-MinSketch算法的应用。同时,讨论了缓存添加策略、自定义过期规则和缓存清理机制,以及如何通过监听器处理缓存更新和清除事件。
本文介绍了Caffeine高性能本地缓存组件,探讨了其淘汰算法(如FIFO、LRU、LFU)以及Count-MinSketch算法的应用。同时,讨论了缓存添加策略、自定义过期规则和缓存清理机制,以及如何通过监听器处理缓存更新和清除事件。
Caffeine本地缓存
Caffine简介
-
简单说,Caffine 是一款高性能的本地缓存组件,由下面三幅图可见:不管在并发读、并发写还是并发读写的场景下,Caffeine的性能都大幅领先于其他本地开源缓存组件
-
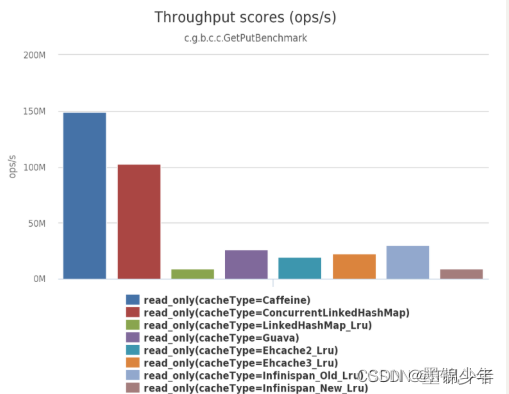
-
常见的缓存淘汰算法
FIFO
它是优先淘汰掉最先缓存的数据、是最简单的淘汰算法。缺点是如果先缓存的数据使用频率比较高的话,那么该数据就不停地进进出出,因此它的缓存命中率比较低
LRU
它是优先淘汰掉最久未访问到的数据。缺点是不能很好地应对偶然的突发流量。比如一个数据在一分钟内的前 59 秒访问很多次,而在最后 1 秒没有访问,但是有一批冷门数据在最后一秒进入缓存,那么热点数据就会被冲刷掉
LFU
最近最少频率使用。它是优先淘汰掉最不经常使用的数据,需要维护一个表示使用频率的字段,缺点主要有两个:
需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨大的开销
对突发性的稀疏流量响应迟钝,因为历史的数据已经积累了很多次计数,新来的数据肯定是排在后续的
比如某个歌手的老歌播放历史较多,新出的歌如果和老歌一起排序的话,就永无出头之日
问题:如果老板让你统计一个实时的数据流中元素出现的频率,并且准备随时回答某个元素出现的频率,不需要的精确的计数,那该怎么办?
Count–Min Sketch算法
Count-min Sketch算法是一个可以用来计数的算法,在数据大小非常大时,一种高效的计数算法,通过牺牲准确性提高的效率
基本的思路:
创建一个长度为 x 的数组,用来计数,初始化每个元素的计数值为 0;对于一个新来的元素,哈希到 0 到 x 之间的一个数,比如哈希值为i,作为数组的位置索引;这时,数组对应的位置索引 i 的计数值加 1;那么,这时要查询某个元素出现的频率,只要简单的返回这个元素哈希望后对应的数组的位置索引的计数值即可;考虑到使用哈希,会有冲突,即不同的元素哈希到同一个数组的位置索引,这样,频率的统计都会偏大
如何优化
使用多个数组,和多个哈希函数,来计算一个元素对应的数组的位置索引;那么,要查询某个元素的频率时,返回这个元素在不同数组中的计数值中的最小值即可;
Count–Min Sketch 算法类似布隆过滤器 (Bloom Filter)思想,对于频率统计我们其实不需要一个精确值。存储数据时,对 key 进行多次 hash 函数运算后,二维数组不同位置存储频率(Caffeine 实际实现的时候是用一维 long 型数组,每个 long 型数字切分成 16 份,每份 4 bit,默认 15 次为最高访问频率,每个 key 实际 hash 了四次,落在不同 long 型数字的 16 份中某个位置)。读取某个 key 的访问次数时,会比较所有位置上的频率值,取最小值返回。为了解决数据访问模式随时间变化的问题,也为了避免计数无限增长,对于所有 key 的访问频率之和有个最大值,当达到最大值时,会进行 reset 即对各个缓存 key 的频率除以 2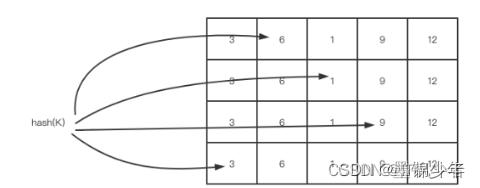
窗口设计
对同一对象的 “稀疏突发” 的场景下,TinyLFU 会出现问题。在这种情况下,新突发的 key 无法建立足够的频率以保留在缓存中,从而导致不断的 cache miss。通过设计称为 Window Tiny LFU(W-TinyLFU)的策略(包含两个缓存区域),Caffeine 解决了这个问题
缓存访问频率存储主要分为两大部分,即 LRU 和 Segmented LRU 。新访问的数据会进入第一个 LRU,在 Caffeine 里叫 WindowDeque。当 WindowDeque 满时,会进入 Segmented LRU 中的 ProbationDeque,在后续被访问到时,它会被提升到 ProtectedDeque。当 ProtectedDeque 满时,会有数据降级到 ProbationDeque 。数据需要淘汰的时候,对 ProbationDeque 中的数据进行淘汰。具体淘汰机制:取 ProbationDeque 中的队首和队尾进行 PK,队首数据是最先进入队列的,称为受害者,队尾的数据称为攻击者,比较两者频率大小,大胜小汰;
————————————————
-
先说一下什么是“加载”,当查询缓存时,缓存未命中,那就需要去第三方数据库中查询,然后将查询出的数据先存入缓存,再返回给查询者,这个过程就是加载
-
Caffeine 提供了四种缓存添加策略:手动加载,自动加载,手动异步加载和自动异步加载
-
添加 Maven 依赖
-
<!-- caffeine缓存框架 -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.8.8</version>
</dependency> -
手动加载
// 初始化缓存,设置了 1 分钟的写过期,100 的缓存最大个数
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES)
.maximumSize(100)
.build();int key = 1;
// 使用 getIfPresent 方法从缓存中获取值。如果缓存中不存指定的值,则方法将返回 null
System.out.println("不存在值,返回null:" + cache.getIfPresent(key));// 也可以使用 get 方法获取值,该方法将一个参数为 key 的 Function 作为参数传入。
// 如果缓存中不存在该 key 则该函数将用于提供默认值,该值在计算后插入缓存中:
System.out.println("返回默认值:" + cache.get(key, a -> 2));缓存元素可以通过调用 cache.put(key, value)方法被加入到缓存当中。如果缓存中指定的 key 已经存在对应的缓存元素的话,那么先前的缓存的元素将会被直接覆盖掉。因此,通过 cache.get(key, k -> value) 的方式将要缓存的元素通过原子计算的方式 插入到缓存中,以避免和其他写入进行竞争
-
自动加载
LoadingCache<String, Object> cache2 = Caffeine
.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(TestCache::createObject);String key2 = "dragon";
// 查找缓存,如果缓存不存在则生成缓存元素, 如果无法生成则返回 null
Object value = cache2.get(key2);
System.out.println(value);异步手动加载、
-
@Test
-
public void test() throws ExecutionException, InterruptedException {
AsyncCache<String, Integer> cache = Caffeine.newBuilder().buildAsync();// 会返回一个 future对象, 调用 future 对象的 get 方法会一直卡住直到得到返回,和多线程的 submit 一样
CompletableFuture<Integer> ageFuture = cache.get("张三", name -> {
System.out.println("name:" + name);
return 18;
});Integer age = ageFuture.get();
System.out.println("age:" + age);
} -
expireAfterWrite
-
某个数据在多久没有被更新后,就过期。举个例子
-
只能是被更新,才能延续数据的生命,即便是数据被读取了,也不行,时间一到,也会过期
expireAfter
-
自定义缓存策略,满足多样化的过期时间要求
移除监听器
-
当缓存中的数据发送更新,或者被清除时,就会触发监听器,在监听器里可以自定义一些处理手段,比如打印出哪个数据被清除,原因是什么。这个触发和监听的过程是异步的,就是说可能数据都被删除一小会儿了,监听器才监听到
-
removalListener 方法的参数是一个 RemovalListener 对象,但是可以函数式传参,如上述代码,当数据被更新或者清除时,会给监听器提供三个内容,(键,值,原因)分别对应代码中的三个参数,(键,值)都是更新前,清除前的旧值, 这样可以了解到清除的详细了。清除的原因有 5 个,存储在枚举类 RemovalCause 中:
-
EXPLICIT : 表示显式地调用删除操作,直接将某个数据删除
REPLACED:表示某个数据被更新
EXPIRED:表示因为生命周期结束(过期时间到了),而被清除
SIZE:表示因为缓存空间大小受限,总权重受限,而被清除
COLLECTED : 用于我们的垃圾收集器,也就是我们上面减少的软引用,弱引用a -
API
-
V getIfPresent(K key) :如果缓存中 key 存在,则获取 value,否则返回 null
void put( K key, V value):存入一对数据 <key, value>
Map<K, V> getAllPresent(Iterable<?> var1) :参数是一个迭代器,表示可以批量查询缓存 void putAll( Map<? extends K, ? extends V> var1); 批量存入缓存 void invalidate(K var1):删除某个 key 对应的数据 void invalidateAll(Iterable<?> var1):批量删除数据
void invalidateAll():清空缓存
long estimatedSize():返回缓存中数据的个数
CacheStats stats():返回缓存当前的状态指标集
ConcurrentMap<K, V> asMap():将缓存中所有的数据构成一个 map
void cleanUp():会对缓存进行整体的清理,比如有一些数据过期了,但是并不会立马被清除,所以执行一次 cleanUp 方法,会对缓存进行一次检查,清除那些应该清除的数据
V get(K var1, Function<? super K, ? extends V> var2):第一个参数是想要获取的 key,第二个参数是函数

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









