







 本文介绍了Apache Flink作为一个实时数据处理框架的主要特点和优势,包括低延迟、高吞吐、事件驱动和基于流的世界观。对比了Flink与Spark Streaming的数据模型和运行时架构,并通过Wordcount案例展示了Flink的用法。Flink支持事件时间和处理时间,提供精确一次的状态一致性保证,适合现代大数据处理需求。
本文介绍了Apache Flink作为一个实时数据处理框架的主要特点和优势,包括低延迟、高吞吐、事件驱动和基于流的世界观。对比了Flink与Spark Streaming的数据模型和运行时架构,并通过Wordcount案例展示了Flink的用法。Flink支持事件时间和处理时间,提供精确一次的状态一致性保证,适合现代大数据处理需求。
1.Flink概念
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
为什么选择flink?
- 流数据更真实地反映了我们的⽣活⽅式
- 传统的数据架构是基于有限数据集的
- 我们的⽬标
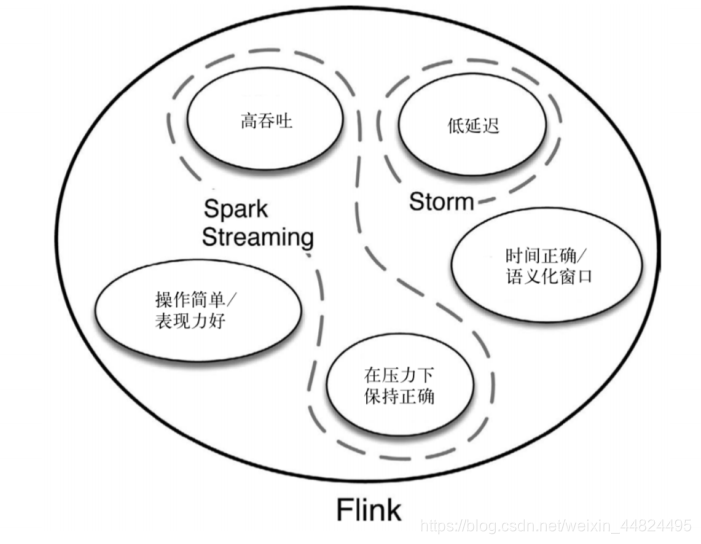
➢ 低延迟(Spark Streaming的延迟是秒级,Flink延迟是毫秒级)
➢ ⾼吞吐(阿⾥每秒钟使⽤Flink处理4.6PB,双⼗⼀⼤屏)
➢ 结果的准确性和良好的容错性(exactly-once)
2.数据处理的演变
2.1 传统数据处理架构
2.1.1 事务处理
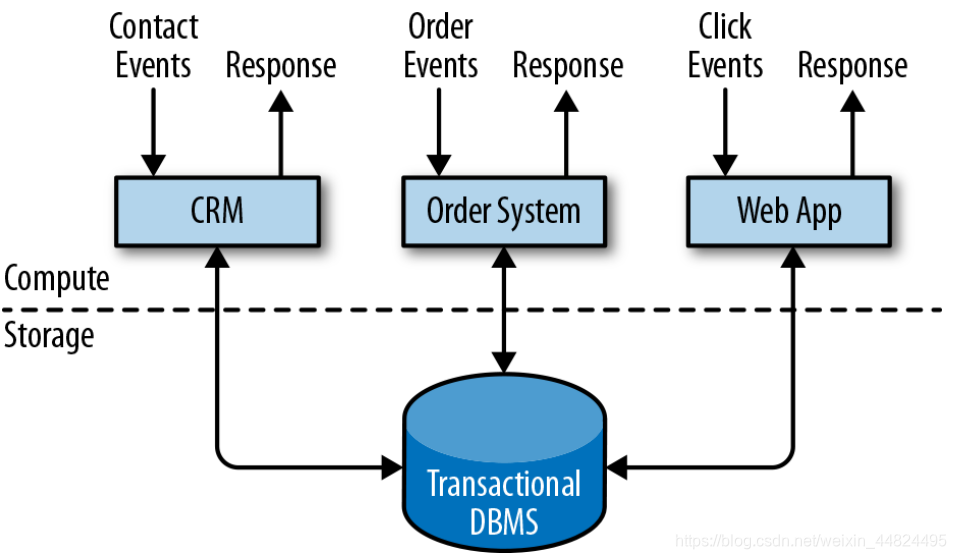
公司将各种应用程序用于日常业务活动,例如企业资源规划(ERP)系统,客户关系管理(CRM)软件和基于 Web 的应用程序。这些系统通常设计有单独的层,用于数据处理(应用程序本身)和数据存储(事务数据库系统)。
需要写入传统型数据库,数据量超过了DBMS的负担
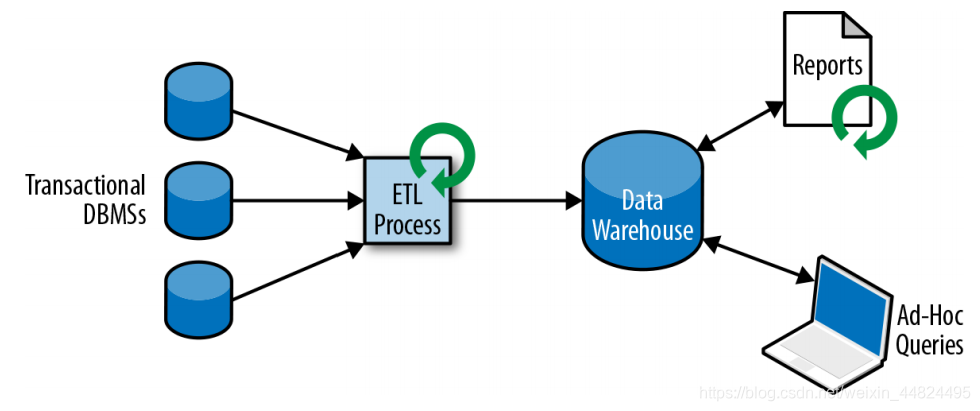
2.1.2 分析处理(Hive):MySQL -> Sqoop -> Hive
将数据从业务数据库复制到数仓,再进⾏分析和查询
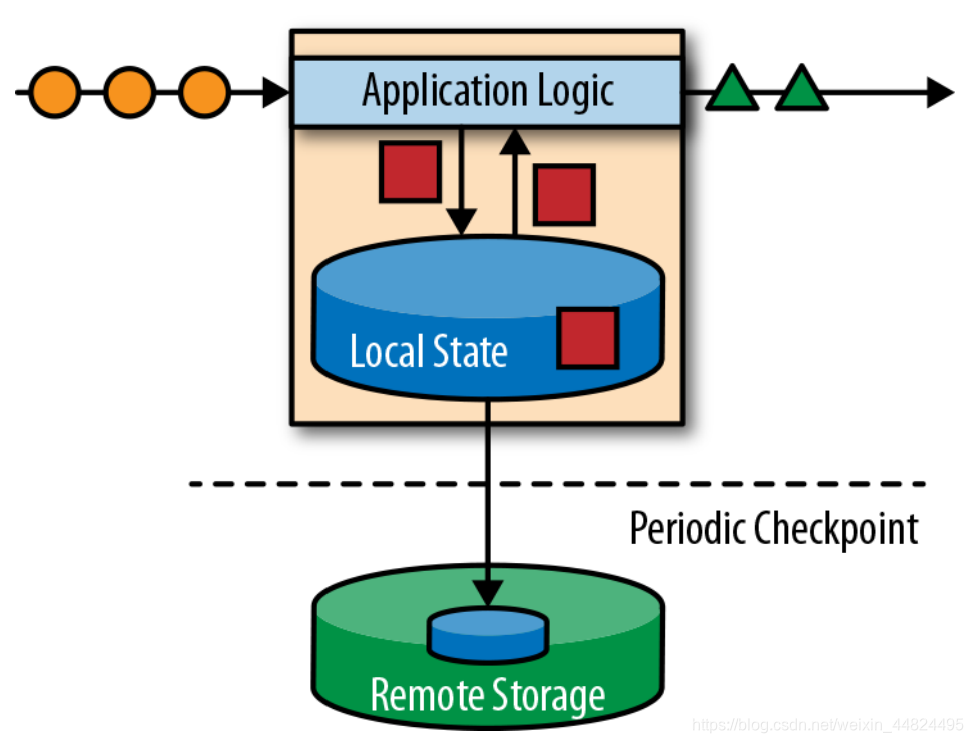
2.2 有状态的流式处理
-
有状态的流式处理:通过计数器对操作进行状态保存,对状态进行存取,需要在阶段性checkpoint进行落盘操作,基于数据传入的顺序问题,所以进行了小批处理
-
⽆状态的流式处理:Apache Kafka,不保存状态,FIFO
开窗⼝操作,缓存⼀段时间的数据的offset
web app的session,状态 -
函数式编程,要求尽量⽆状态,纯函数(没有副作⽤)
全局变量其实就是状态
纯函数:输⼊不变,⽆论运⾏多少次,输出都不变
相当于幂等性
x => x + 1
2.3 流处理的演变
批处理:保证结果的准确性
流处理:保证低延迟
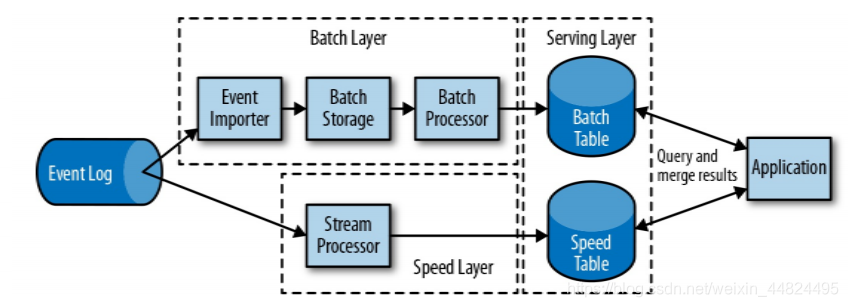
2.3.1 lambda 架构(批处理 + 流处理)
➢ ⽤两套系统,同时保证低延迟和结果准确
2.3.2 Flink
3.Flink 的主要特点
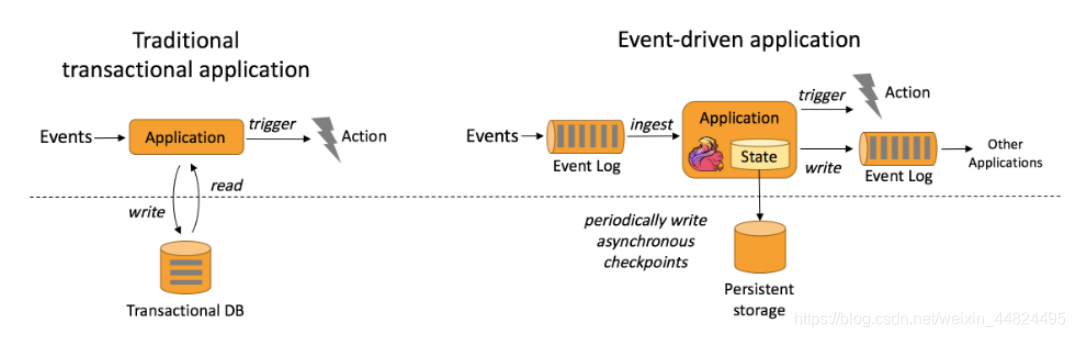
3.1 事件驱动(Event-driven)
-
来⼀条数据(事件),触发⼀次算⼦的计算,事件驱动
-
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作
-
后端的事件驱动的代表:netty,akka,goroutine,协程,。。。
前端的事件驱动代表:RxJs -
Spark SQL
Spark RDD
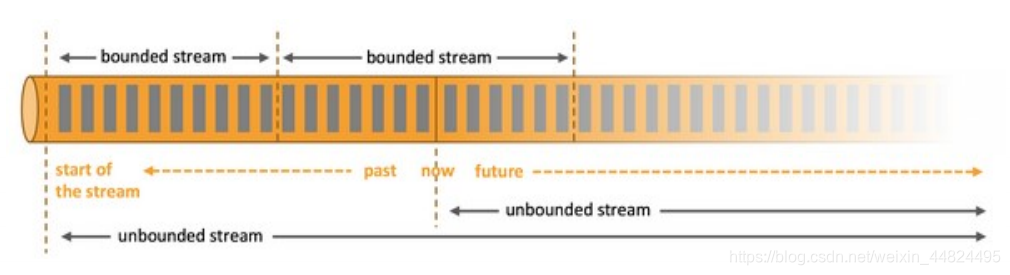
3.2 基于流的世界观
➢ 在 Flink 的世界观中,⼀切都是由流组成的,离线数据是有界的
流;实时数据是⼀个没有界限的流:这就是所谓的有界流和⽆界流
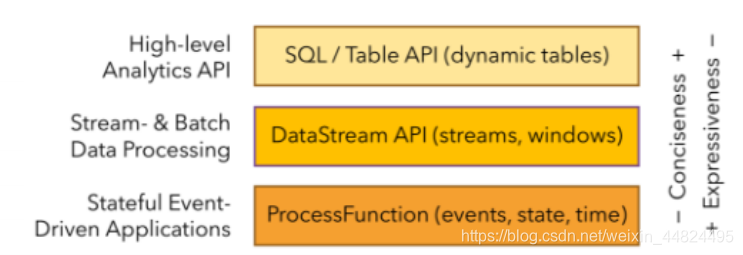
3.3 分层API
➢ 越顶层越抽象,表达含义越简明,使⽤越⽅便
➢ 越底层越具体,表达能⼒越丰富,使⽤越灵活
3.4 其它特点
-
⽀持事件时间(event-time)和处理时间(processing-time)语
义 -
精确⼀次(exactly-once)的状态⼀致性保证
-
低延迟,每秒处理数百万个事件,毫秒级延迟
-
与众多常⽤存储系统的连接(ES,HBase,MySQL,Redis…)
-
⾼可⽤(zookeeper),动态扩展,实现7*24⼩时全天候运⾏
-
事件时间:事件真实发⽣的时间,要求数据中包含时间戳
处理时间:事件到达节点时当前节点的机器时间
spark streaming只⽀持处理时间(机
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









