






【Lambda】集合的Lambda表达式
- 【一】Stream的方法介绍
- 【二】常用案例总结
- 【三】其他案例分析
- 【四】List使用stream流转成map的几种方式
- 【1】List 转成Map<String,Object>
- 【2】List 转成Map<String,String>
- 【3】List 转成Map<String,List>
- 【4】List 转成Map<String,List>
- 【5】List<Map<String,Object>> 转成Map<String,Map<String,Object>>
- 【6】List<Map<String,Object>> 转成Map<String,Object>
- 【7】List<Map<String,String>> 转成Map<String,Map<String,String>>
- 【8】List<Map<String,String>> 转成Map<String,String>
- 【五】Map转成List
- 【六】查找重复的值
- 【七】flatMap案例解析
【一】Stream的方法介绍
【1】Stream里常用的方法
(1)collect(toList()):通过 Stream 生成一个列表
(2)map:将流中的一个值转换成一个新的值
(3)filter:过滤 Stream 中的元素
(4)flatMap:将多个 Stream 连接成一个 Stream
(5)max:求最大值
(6)min:求最小值
(7)reduce:从一组值中生成一个新的值
(8)Collectors.joining:从一组值中取出值做拼接(可以替换String.join方法)
【2】collect(toList()) & filter
collect(toList()) 的作用是通过一个 Stream 对象生成 List 对象,案例:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = list.stream().filter((value) -> value > 2).collect(toList());
result.forEach((value) -> System.out.print(value));
上面的代码先创建了一个 List 对象并初始化,然后筛选出大于 2 的值,输出。
filter 方法的作用是过滤 Stream 中的元素,filter 方法是一个高阶函数,接收一个函数接口作为参数,此高阶函数返回一个 boolean 值,返回 true 的元素会保留下来;
collect(toList()) 方法将 filter 操作返回的 Stream 生成一个 List。
【3】map
在对集合进行操作的时候,我们经常会从某些对象中选择性的提取某些元素的值,就像编写sql一样,指定获取表 中特定的数据列
map 函数的作用是将流中的一个值转换成一个新的值,举个例子,我们要将一个 List 转换成 List ,那么就可以使用 map 方法,示例代码:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<String> result = list.stream().map(value -> String.format("String:%s", value)).collect(toList());
result.forEach(System.out::print);
map 方法将 Integer 元素转换成 String 并使用 collect(toList()) 方法生成一个新的 List。
System.out::print 是 (value) -> System.out.print(value) 的简化版写法。
代替遍历
List<IndAggregateFuncQueryResponse> collect = Arrays.stream(StatisticalCycleEnum.values())
.map(sc -> {
IndAggregateFuncQueryResponse response = new IndAggregateFuncQueryResponse();
response.setId(String.valueOf(sc.getId()));
response.setFuncName(sc.getShowDesc());
response.setFuncDesc(sc.getRemark());
response.setRemark(sc.getRemark());
response.setFuncCode(sc.getCode());
response.setFuncExpression(sc.getCode());
return response;
})
.collect(Collectors.toList());
【4】flatMap
flatMap:将多个 Stream 连接成一个 Stream,这个怎么理解呢,举个栗子:
首先定义一个 List 对象,将这个对象中的每一个 String 都分割成一个字母并生成一个新的 List 对象,代码:
List<String> list = Arrays.asList("abc", "def", "ghi");
List<Character> result = list.stream().flatMap(value -> {
char[] chars = value.toCharArray();
Character[] characters = new Character[chars.length];
for(int i = 0; i < characters.length; i++){
characters[i] = chars[i];
}
return Stream.of(characters);
}).collect(toList());
result.forEach(System.out::println);
上面代码先遍历 list ,通过 flatMap 函数将每个 String 元素都生成一个新的 Stream 并将这些 Stream 连接成一个新的 Stream。
【5】max&min
求最大值最小值
List<Integer> list = Arrays.asList(0, 1, 2, 3);
Comparator<Integer> comparator = (o1, o2) -> o1.compareTo(o2);
System.out.println(list.stream().min(comparator).get());
System.out.println(list.stream().max(comparator).get());
min 和 max 函数需要一个 Comparator 对象为参数作为比对依据。
【6】reduce
从一组值中生成一个新的值,reduce 函数其实用途非常广泛,作用也比较大,我们举一个累加的例子:
List<Integer> list = Arrays.asList(0, 1, 2, 3);
int count = list.stream().reduce(0, (acc, item) -> acc + item).intValue();
System.out.println(count);
reduce 函数的一个参数为循环的初始值,这里计算累加时初始值为 0,acc 代表已经计算的结果,item 表示循环的每个元素。
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
Integer reduce = integers.stream().reduce(0, (integer1, integer2) -> integer1 + integer2);
System.out.println(reduce);
在上述代码中,在reduce里的第一个参数声明为初始值,第二个参数接收一个lambda表达式,代表当前流中的两 个元素,它会反复相加每一个元素,直到流被归约成一个终结果
Integer reduce = integers.stream().reduce(0,Integer::sum);
优化成这样也是可以的。当然,reduce还有一个不带初始值参数的重载方法,但是要对返回结果进行判断,因为如果流中没有任何元素的话,可能就没有结果了。具体方法如下所示
【7】ifPresent
【8】findAny:查找元素
对于集合操作,有时需要从集合中查找中符合条件的元素,Stream中也提供了相关的API,findAny()和 findFirst(),他俩可以与其他流操作组合使用。findAny用于获取流中随机的某一个元素,findFirst用于获取流中的 第一个元素。至于一些特别的定制化需求,则需要自行实现。
findAny用于获取流中随机的某一个元素,并且利用短路在找到结果时,立即结束
//findAny用于获取流中随机的某一个元素,并且利用短路在找到结果时,立即结束
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1,19,"张三1","M",true));
students.add(new Student(1,18,"张三2","M",false));
students.add(new Student(1,21,"张三3","F",true));
students.add(new Student(1,20,"张三4","F",false));
students.add(new Student(1,20,"张三5","F",false));
students.add(new Student(1,20,"张三6","F",false));
Optional<Student> student1 = students.stream().filter(student -> student.getSex().equals("F")).findAny();
System.out.println(student1.toString());
【9】findFirst:
【9】anyMatch:判断条件至少匹配一个元素(判断两个列表之间是否存在交集)
anyMatch()主要用于判断流中是否至少存在一个符合条件的元素,它会返回一个boolean值,并且对于它的操作, 一般叫做短路求值
判断集合中是否有年龄小于20的学生
//判断集合中是否有年龄小于20的学生
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1,19,"张三","M",true));
students.add(new Student(1,18,"李四","M",false));
students.add(new Student(1,21,"王五","F",true));
students.add(new Student(1,20,"赵六","F",false));
if(students.stream().anyMatch(student -> student.getAge() < 20)){
System.out.println("集合中有年龄小于20的学生");
}else {
System.out.println("集合中没有年龄小于20的学生");
}
判断两个集合之间有没有交集
Optional.ofNullable(indexList).orElse(Lists.newArrayList()).stream()
.filter(it->!ObjectUtil.equals(it.getCusDefId().toString(),queryRequest.getDefinitionId()))
.forEach(index->{
boolean hasTableInter = thisTableNames.stream().anyMatch(similarTableNames::contains);
boolean hasColumnInter = thisColumnNames.stream().anyMatch(similarColumnNames::contains);
});
【10】allMatch:判断条件是否匹配所有元素
allMatch()的工作原理与anyMatch()类似,但是anyMatch执行时,只要流中有一个元素符合条件就会返回true, 而allMatch会判断流中是否所有条件都符合条件,全部符合才会返回true
判断集合所有学生的年龄是否都小于20
//判断集合所有学生的年龄是否都小于20
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1,19,"张三","M",true));
students.add(new Student(1,18,"李四","M",false));
students.add(new Student(1,21,"王五","F",true));
students.add(new Student(1,20,"赵六","F",false));
if(students.stream().allMatch(student -> student.getAge() < 20)){
System.out.println("集合所有学生的年龄都小于20");
}else {
System.out.println("集合中有年龄大于20的学生");
}
【11】skip:跳过
从集合第三个开始截取5个数据
//从集合第三个开始截取5个数据
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
List<Integer> collect = integers.stream().skip(3).limit(5).collect(Collectors.toList());
collect.forEach(integer -> System.out.print(integer+" "));
先从集合中截取5个元素,然后取后3个
//先从集合中截取5个元素,然后取后3个
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
List<Integer> collect = integers.stream().limit(5).skip(2).collect(Collectors.toList());
collect.forEach(integer -> System.out.print(integer+" "));
【12】distinct:去重
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
integers.stream().distinct().collect(Collectors.toList());
【13】limit:切片
获取数组的前五位
//获取数组的前五位
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
integers.stream().limit(5);
【14】filter:过滤
获取所有年龄20岁以下的学生
public class FilterDemo {
public static void main(String[] args) {
//获取所有年龄20岁以下的学生
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1,19,"张三","M",true));
students.add(new Student(1,18,"李四","M",false));
students.add(new Student(1,21,"王五","F",true));
students.add(new Student(1,20,"赵六","F",false));
students.stream().filter(student -> student.getAge()<20);
}
}
【二】常用案例总结
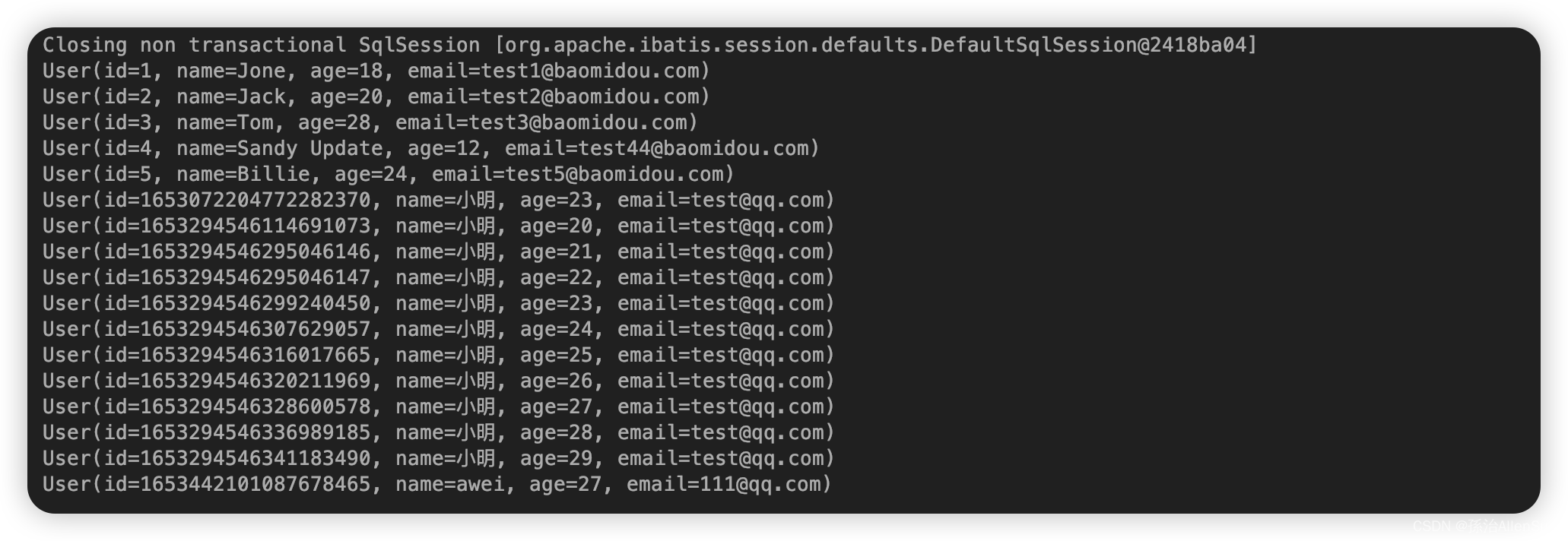
【1】准备方法查询数据库获取List结果
用的是Mybatis-plus的mapper,也可以自己自定义一个List集合
@SpringBootTest
public class LambdaTest {
@Autowired
private UserMapper userMapper;
@Test
public void selectList() {
// 通过条件构造器查询一个List集合,如果没有条件,就可以设置null为参数
List<User> list = userMapper.selectList(null);
list.forEach(System.out::println);
}
}
实体类代码为
@Data // 包含以上,除了有参构造
@TableName("user")
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
输出的结果如下
【2】取值
从list的实体类中取出某一个目标值,放进新的list结果中。例如,从List集合的User实体类中取出name,并且放进List里。
代码如下(下面这两种写法都可以的!):
List<String> nameList = list.stream().map(User::getName).collect(Collectors.toList());
List<String> nameList = list.stream().map(it->it.getName()).collect(Collectors.toList());
执行的效果如下:
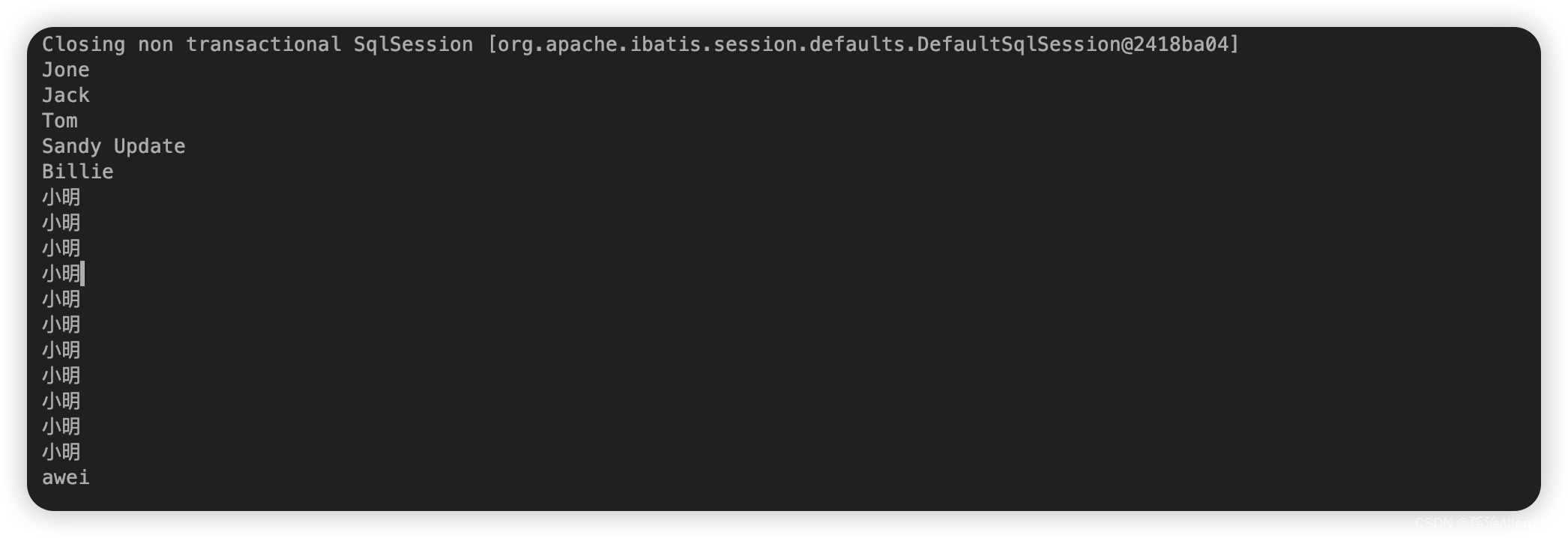
【3】分组:groupingBy
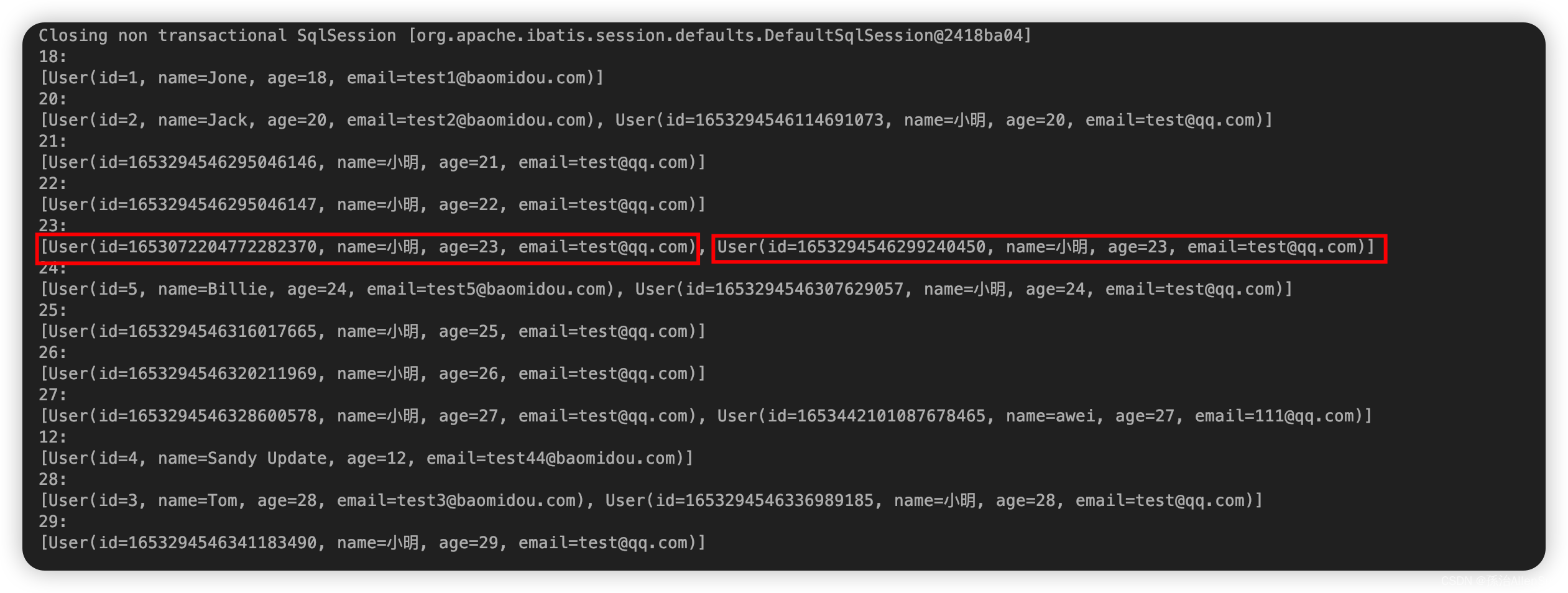
把List里的实体类,按照实体类中的某个值进行分类存放,结果使用Map接收。例如我们把List中的User按照年龄进行分类存放到不同的List里。
代码如下:
Map<Integer, List<User>> ageMap = list.stream().collect(Collectors.groupingBy(User::getAge));
ageMap.forEach((k,v)->{
System.out.println(k+":\n"+String.join("\n",v.toString()));
});
执行的结果如下:
(1)groupBy后,取某个字段值为字符串
List<User> userList = new ArrayList();
Map<String,String> collect = userList.stream().collect(Collectors.groupingBy(
User::getRealname, Collectors.mapping(User::getUsername, Collectors.joining(","))));
(2)groupBy后,取某个字段值为list
List<User> userList = new ArrayList();
Map<String,List<String>> collect = userList.stream().collect(Collectors.groupingBy(
User::getRealname, Collectors.mapping(User::getUsername, Collectors.toList())));
(3)groupBy后,按字段分组统计数量
假设我们有一个Person类,包含id和name字段,需要按name分组统计人数:
import java.util.*;
import java.util.stream.Collectors;
class Person {
private Integer id;
private String name;
public Person(Integer id, String name) {
this.id = id;
this.name = name;
}
public String getName() {
return name;
}
// 重写 toString() 以便打印
@Override
public String toString() {
return "Person{name='" + name + "'}";
}
}
public class GroupingByCountExample {
public static void main(String[] args) {
List<Person> people = Arrays.asList(
new Person(1, "Alice"),
new Person(2, "Bob"),
new Person(3, "Alice"),
new Person(4, "Charlie")
);
// 按 name 分组并统计数量
Map<String, Long> nameCountMap = people.stream()
.collect(Collectors.groupingBy(Person::getName, Collectors.counting()));
// 输出结果
System.out.println("按姓名分组统计人数:");
nameCountMap.forEach((name, count) -> System.out.println(name + ": " + count + " 人"));
}
}
如果需要对结果进行排序(例如按数量降序),或指定默认值,可以进一步处理:
import java.util.*;
import java.util.stream.Collectors;
public class AdvancedCountExample {
public static void main(String[] args) {
List<String> words = Arrays.asList("apple", "banana", "apple", "cherry");
// 按出现次数降序排序
LinkedHashMap<String, Long> sortedMap = words.stream()
.collect(Collectors.groupingBy(
word -> word,
Collectors.counting()
))
.entrySet().stream()
.sorted(Map.Entry.<String, Long>comparingByValue().reversed())
.collect(Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(e1, e2) -> e1,
LinkedHashMap::new
));
// 输出排序结果
System.out.println("按出现次数降序排序:");
sortedMap.forEach((word, count) -> System.out.println(word + ": " + count));
}
}
【4】!!!去重
(1)单值去重
代码如下:
@Test
public void distinctTield() {
List<String> numList = Arrays.asList("1","2","2","3","3","4","4","5","6","7","8");
List<User> userList = userMapper.selectList(null);
System.out.println(LambdaTest.distinctElements(numList));
System.out.println(LambdaTest.getNoDuplicateElements(numList));
System.out.println(LambdaTest.getDuplicateElements(numList));
System.out.println(LambdaTest.getDuplicateElementsForObject(userList));
System.out.println(LambdaTest.getNoDuplicateElementsForObject(userList));
System.out.println(LambdaTest.getElementsAfterDuplicate(userList));
System.out.println(LambdaTest.getDuplicateObject(userList));
System.out.println(LambdaTest.getNoDuplicateObject(userList));
System.out.println(LambdaTest.distinctObject(userList));
}
//(1)把重复的数据删除,只留下一个
//去重后的集合 [1, 2, 3, 4, 5, 6, 7, 8]
public static <T> List<T> distinctElements(List<T> list) {
return list.stream().distinct().collect(Collectors.toList());
}
//(2)把所有出现重复的数据都删除
//lambda表达式 去除集合重复的值 [1, 5, 6, 7, 8]
public static <T> List<T> getNoDuplicateElements(List<T> list) {
// 获得元素出现频率的 Map,键为元素,值为元素出现的次数
Map<T, Long> map = list.stream().collect(Collectors.groupingBy(p -> p,Collectors.counting()));
System.out.println("getDuplicateElements2: "+map);
return map.entrySet().stream() // Set<Entry>转换为Stream<Entry>
.filter(entry -> entry.getValue() == 1) // 过滤出元素出现次数等于 1 的 entry
.map(entry -> entry.getKey()) // 获得 entry 的键(重复元素)对应的 Stream
.collect(Collectors.toList()); // 转化为 List
}
//(3)把出现重复的数据查出来
//lambda表达式 查找出重复的集合 [2, 3, 4]
public static <T> List<T> getDuplicateElements(List<T> list) {
return list.stream().collect(Collectors.collectingAndThen(Collectors
.groupingBy(p -> p, Collectors.counting()), map->{
map.values().removeIf(size -> size ==1); // >1 查找不重复的集合;== 1 查找重复的集合
List<T> tempList = new ArrayList<>(map.keySet());
return tempList;
}));
}
//利用set集合
public static <T> Set<T> getDuplicateElements2(List<T> list) {
Set<T> set = new HashSet<>();
Set<T> exist = new HashSet<>();
for (T s : list) {
if (set.contains(s)) {
exist.add(s);
} else {
set.add(s);
}
}
return exist;
}
/**-----------对象List做处理--------------*/
//查找对象中某个原属重复的 属性集合
public static List<String> getDuplicateElementsForObject(List<User> list) {
return list.stream().collect(Collectors.groupingBy(p -> p.getName(),Collectors.counting())).entrySet().stream()// 根据name分类,并且统计每个name出现的次数
.filter(entry -> entry.getValue() > 1) // >1 查找重复的集合;== 查找不重复的集合
.map(entry -> entry.getKey())
.collect(Collectors.toList());
}
//查找对象中某个原属未重复的 属性集合
public static List<String> getNoDuplicateElementsForObject(List<User> list){
Map<String,List<User>> map = list.stream().collect(Collectors.groupingBy(User::getName));
return map.entrySet().stream().filter(entry -> entry.getValue().size() == 1)
.map(entry -> entry.getKey()) // 获得 entry 的键(重复元素)对应的 Stream
.collect(Collectors.toList()); // 转化为 List
}
//查找对象中某个原属去重后的集合
public static List<String> getElementsAfterDuplicate(List<User> list) {
return list.stream().map(o->o.getName()).distinct().collect(Collectors.toList());
}
//对象中某个原属重复的 对象集合
public static List<List<User>> getDuplicateObject(List<User> list) {
return list.stream().collect(Collectors.groupingBy(User::getName)).entrySet().stream()
.filter(entry -> entry.getValue().size() > 1) // >1 查找重复的集合;== 查找不重复的集合
.map(entry -> entry.getValue())
.collect(Collectors.toList());
}
//对象中某个原属未重复 对象集合
public static List<User> getNoDuplicateObject(List<User> list) {
List<User> cities = new ArrayList<>();
list.stream().collect(Collectors.groupingBy(User::getName)).entrySet().stream()
.filter(entry -> entry.getValue().size() ==1) //>1 查找重复的集合;== 查找不重复的集合;
.map(entry -> entry.getValue())
.forEach(p -> cities.addAll(p));
return cities;
}
//根据对象的某个原属去重后的 对象集合
public static List<User> distinctObject(List<User> list) {
return list.stream().filter(distinctByKey(User::getName)).collect(Collectors.toList());
}
public static <T> Predicate<T> distinctByKey(Function<? super T, Object> keyExtractor) {
Map<Object, Boolean> seen = new ConcurrentHashMap<>();
return object -> seen.putIfAbsent(keyExtractor.apply(object), Boolean.TRUE) == null;
}
(2)对象去重
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.function.Function;
import java.util.function.Predicate;
import java.util.stream.Collectors;
public class Test {
private static final List<User> list = Arrays.asList(
new User("张三", "男", 2, "2019-1-1", "身份证", "350781196403077840"),
new User("李四", "男", 2, "2019-1-1", "港澳证", "350781196403077840"),
new User("王五", "男", 9, "2019-1-1", "身份证", "350781196403077840"),
new User("赵六", "男", 8, "2019-1-1", "身份证", "350781196403077840"),
new User("赵六", "男", 8, "2019-1-1", "身份证", "350781196403077840"));
/**
* 对所有属性一样的数据进行去重
*/
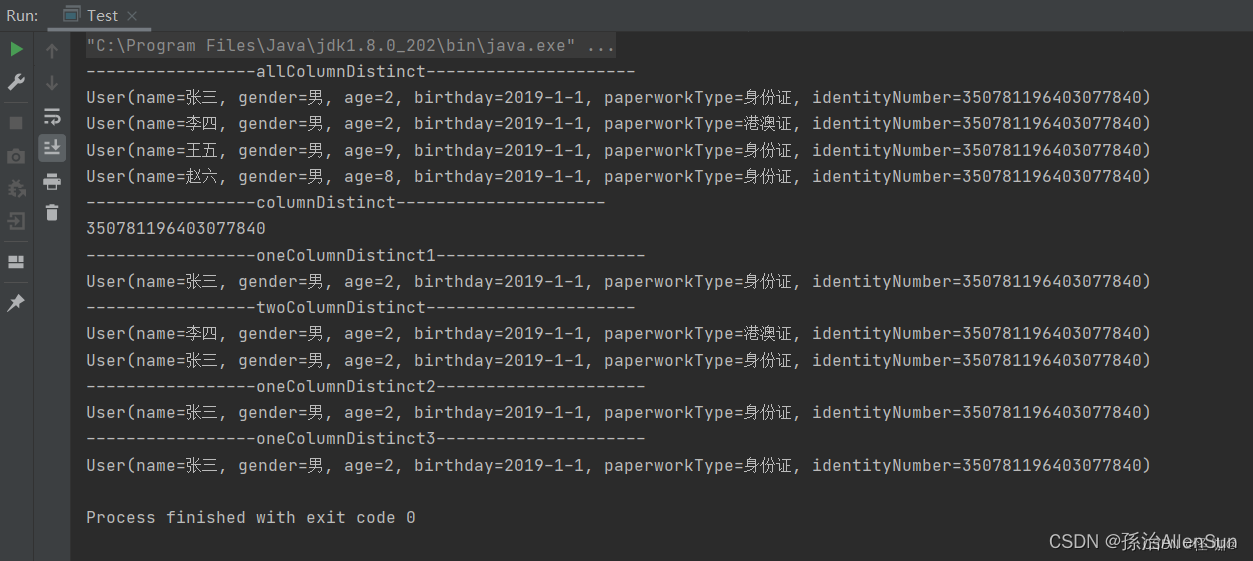
public static void allColumnDistinct() {
List<User> collect = list.stream().distinct().collect(Collectors.toList());
collect.forEach(System.out::println);
}
/**
* 对单个属性去重,只返回去重的属性
*/
public static void columnDistinct() {
List<String> identityNumberList = list.stream().map(User::getIdentityNumber).distinct().collect(Collectors.toList());
identityNumberList.forEach(System.out::println);
}
/**
* 方式一:对单个属性一样的数据进行去重,下面是对身份证去重
*/
public static void oneColumnDistinct1() {
List<User> collect = list.stream().collect(Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(
Comparator.comparing(User::getIdentityNumber))), ArrayList::new));
collect.forEach(System.out::println);
}
/**
* 多个字段条件去重
*/
public static void twoColumnDistinct() {
List<User> collect = list.stream().collect(Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(
Comparator.comparing(p -> p.getIdentityNumber() + ";" + p.getPaperworkType()))), ArrayList::new));
collect.forEach(System.out::println);
}
/**
* 自定义属性判断
*
* @param keyExtractor
* @param <T>
* @return
*/
public static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {
Map<Object, Boolean> seen = new ConcurrentHashMap<>(1);
return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null;
}
/**
* 方式二:对单个属性一样的数据进行去重,下面是对身份证去重
*/
public static void oneColumnDistinct2() {
List<User> collect = list.stream().filter(distinctByKey(b -> b.getIdentityNumber())).collect(Collectors.toList());
collect.forEach(System.out::println);
}
/**
* 方式三:对单个属性一样的数据进行去重,下面是对身份证去重
* 利用TreeSet进行去重
*/
public static void oneColumnDistinct3() {
TreeSet<User> collect = new TreeSet<>(Comparator.comparing(s -> s.getIdentityNumber()));
list.forEach(a -> collect.add(a));
collect.forEach(System.out::println);
}
public static void main(String[] args) {
System.out.println("-----------------allColumnDistinct---------------------");
allColumnDistinct();
System.out.println("-----------------columnDistinct---------------------");
columnDistinct();
System.out.println("-----------------oneColumnDistinct1---------------------");
oneColumnDistinct1();
System.out.println("-----------------twoColumnDistinct---------------------");
twoColumnDistinct();
System.out.println("-----------------oneColumnDistinct2---------------------");
oneColumnDistinct2();
System.out.println("-----------------oneColumnDistinct3---------------------");
oneColumnDistinct3();
}
}
输出结果:
【5】!!!排序
代码如下:
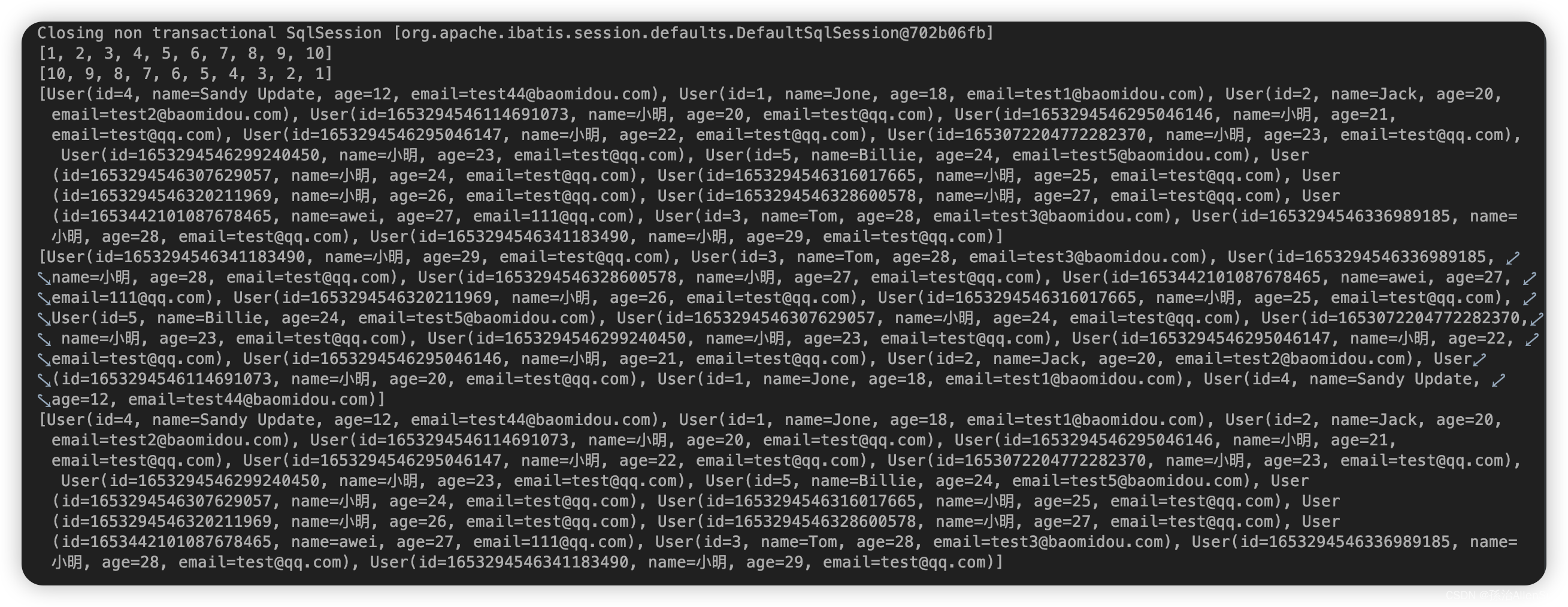
@Test
public void sortField() {
List<Integer> list = Arrays.asList(10,1,6,4,8,7,9,3,2,5);
List<User> userList = userMapper.selectList(null);
System.out.println(sort(list));
System.out.println(reversed(list));
System.out.println(sortForObject(userList));
System.out.println(reversedForObject(userList));
System.out.println(sortForObject2(userList));
}
//list排序 正序
public static <T> List<T> sort(List<T> list){
return list.stream().sorted().collect(Collectors.toList());
}
//list排序 倒序
public static List<Integer> reversed(List<Integer> list){
return list.stream().sorted(Comparator.reverseOrder()).collect(Collectors.toList());
}
//根据对象某个属性排序 正序
public static List<User> sortForObject(List<User> list){
return list.stream().sorted(Comparator.comparing(User::getAge)).collect(Collectors.toList());
}
//根据对象某个属性排序 倒序
public static List<User> reversedForObject(List<User> list){
return list.stream().sorted(Comparator.comparing(User::getAge).reversed()).collect(Collectors.toList());
}
//根据对象两个属性排序 正序
public static List<User> sortForObject2(List<User> list){
return list.stream().sorted(Comparator.comparing(User::getAge).thenComparing(User::getId)).collect(Collectors.toList());
}
处理数据为空的情况
如果list中的值存在空的情况,会报错,可以使用nullsFirst或nullsLast来处理
List<InvestmentVo> sortedList = list.stream()
.sorted(Comparator.comparing(InvestmentVo::getEstdate, Comparator.nullsFirst(Comparator.naturalOrder())).reversed())
.collect(Collectors.toList());
执行效果如下:
【6】list的最值、平均值、求和
代码如下:
@Test
public void getInfo() {
List<Integer> list = Arrays.asList(10,1,6,4,8,7,9,3,2,5);
List<User> userList = userMapper.selectList(null);
calculation1(list);
calculation2(userList);
}
//根据对象某个属性求各自值
///IntSummaryStatistics{count=4, sum=132, min=11, average=33.000000, max=55}
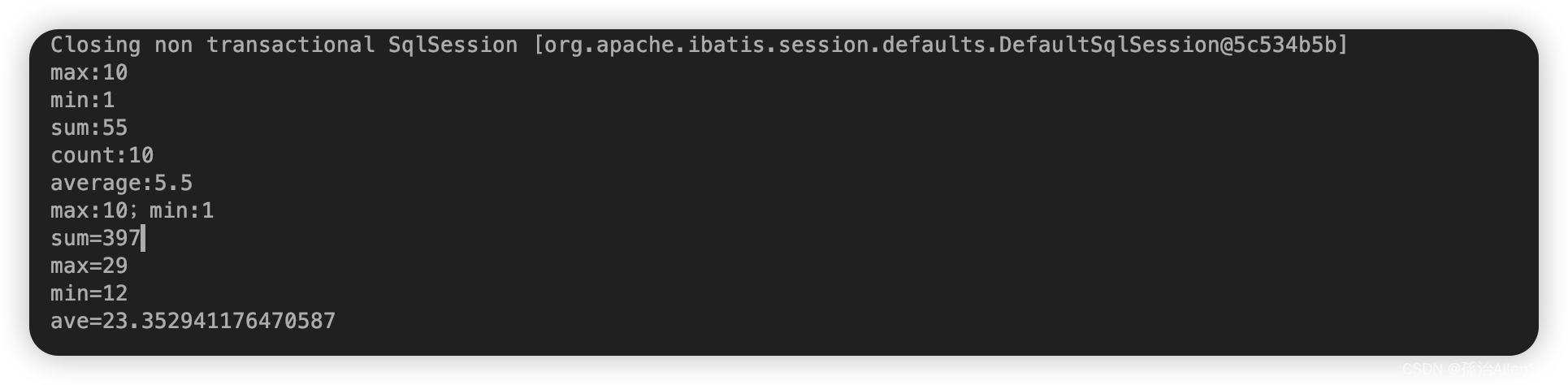
public static IntSummaryStatistics calculation1(List<Integer> list){
IntSummaryStatistics stat = list.stream().collect(Collectors.summarizingInt(p -> p));
System.out.println("max:"+stat.getMax());
System.out.println("min:"+stat.getMin());
System.out.println("sum:"+stat.getSum());
System.out.println("count:"+stat.getCount());
System.out.println("average:"+stat.getAverage());
Integer max = list.stream().reduce(Integer::max).get();//得到最大值
Integer min = list.stream().reduce(Integer::min).get();//得到最小值
System.out.println("max:"+max+";min:"+min);
return stat;
}
//根据对象某个属性求各自值
// sum=397,max=29,min=12,ave=23.352941176470587
public static void calculation2(List<User> list){
System.out.println("sum="+ list.stream().mapToInt(User::getAge).sum());
System.out.println("max="+ list.stream().mapToInt(User::getAge).max().getAsInt());
System.out.println("min="+ list.stream().mapToInt(User::getAge).min().getAsInt());
System.out.println("ave="+ list.stream().mapToInt(User::getAge).average().getAsDouble());
}
代码运行效果如下:
【7】List集合求和
public static void main(String[] args) {
List<BigDecimal> list = new ArrayList<>();
list.add(BigDecimal.valueOf(1.1));
list.add(BigDecimal.valueOf(1.2));
list.add(BigDecimal.valueOf(1.3));
list.add(BigDecimal.valueOf(1.4));
BigDecimal decimal = list.stream().reduce(BigDecimal.ZERO, BigDecimal::add);
System.out.println(decimal);
}
【8】过滤(得到所有满足条件的对象,结果为list)
(1)案例一
//功能描述 过滤
public static List<City> filter(List<City> list){
return list.stream().filter(a -> a.getTotal()>44).collect(Collectors.toList());
}
(2)案例二
例如有两个List,分别为notFinishList和finalList,我们想将finalList中的所有notFinishList的值都过滤掉,就可以用filter来实现
List<Long> taskIds = Array.asList(1,2,3,4);
// 从List<DevelopTask>中取出实体类的id值生成一个List<Long>,假设结果是{1,2}
List<Long> notFinishTaskids = notFinishList.stream().map(DevelopTask::getId).collect(Collectors.toList());
// 从{1,2,3,4}取出除了{1,2}以外的值,也就是{3,4}
taskIds = taskIds.stream().filter(it -> !notFinishTaskids.contains(it)).collect(Collectors.toList());
(3)案例三
判断当前集合中是否存在某值,返回的结果是boolean值
Boolean overallReviewRst = details.stream().filter(it->it.getReviewRst().equals(ReviewStatEnum.NO_PASS.getName())).findAny().isPresent();
(4)案例四
判断当前集合中是否存在某值
audits.stream().anyMatch(a -> po.getIdCard().equals(a.getIdCard()))
(5)案例五
判断当前集合中是否存在某值,存在的话就过滤出来放进新的集合
List<TaskXReviewProjRescResponse> details = detailById.stream()
.filter(d -> String.valueOf(d.getTaskId()).equals(dto.getId()))
.collect(Collectors.toList());
【8】过滤(得到第一个满足条件的对象,结果为单个对象)
使用findFirst()方法返回的是符合条件的第一个元素,使用findAny()方法在多线程并发访问下是符合条件的任意元素
public static void main(String[] args) {
List<UserInfo> list = new ArrayList<>();
UserInfo info1 = new UserInfo("a","11");
UserInfo info2 = new UserInfo("b","22");
UserInfo info3 = new UserInfo("c","33");
list.add(info1);
list.add(info2);
list.add(info3);
list.forEach(System.out::println);
System.out.println("------------");
//筛选出符合条件的数据
UserInfo userInfo = list.stream().filter(s -> s.getUserName().equals("a")).findFirst().orElse(null);
System.out.println(userInfo);
}
【9】map遍历
(1)stream遍历key和value
map.forEach((k, v) -> System.out.println("key:value = " + k + ":" + v));
【10】!!!map转list,list转map
(1)map和list的互相转换
//功能描述 List转map
public static void listToMap(List<User> list){
//用 (k1,k2)->k1 来设置,如果有重复的key,则保留key1,舍弃key2
Map<String,User> map = list.stream().collect(Collectors.toMap(User::getName,user -> user, (k1, k2) -> k1));
map.forEach((k,v) -> System.out.println("k=" + k + ",v=" + v));
}
//功能描述 map转list
public static void mapToList(Map<String,User> map){
List<User> list =
map.entrySet().stream().map(key -> key.getValue()).collect(Collectors.toList());
System.out.println(list);
list.forEach(bean -> System.out.println(bean.getName() + "," + bean.getEmail()));
}
(2)map转list
map.entrySet().stream().map(e -> new Person(e.getKey(),e.getValue())).collect(Collectors.toList());
map.keySet().stream().collect(Collectors.toList());
map.values().stream().collect(Collectors.toList());
(3)list转map
Map<Integer, String> result1 = list.stream().collect(
Collectors.toMap(Hosting::getId, Hosting::getName));
Map<Long, User> maps = userList.stream().collect(Collectors.toMap(User::getId,Function.identity()));
//看来还是使用JDK 1.8方便一些。另外,转换成map的时候,可能出现key一样的情况,如果不指定一个覆盖规则,上面的代码是会报错的。转成map的时候,最好使用下面的方式
Map<Long, User> maps = userList.stream().collect(Collectors.toMap(User::getId, Function.identity(), (key1, key2) -> key2));
【11】list和字符串之间的转换
//功能描述 字符串转list
public static void stringToList(String str){
//不需要处理
//<String> list = Arrays.asList(str.split(","));
//需要处理
List<String> list = Arrays.asList(str.split(",")).stream().map(string -> String.valueOf(string)).collect(Collectors.toList());
list.forEach(string -> System.out.println(string));
}
//功能描述 姓名以逗号拼接
public static void joinStringValueByList(List<User> list){
System.out.println(list.stream().map(User::getName).collect(Collectors.joining(",")));
}
//功能描述 姓名以逗号拼接
public static void joinStringValueByList2(List<String> list){
//方式一
System.out.println(String.join(",", list));
//方式二
System.out.println(list.stream().collect(Collectors.joining(",")));
}
【12】Collectors.joining做拼接
(1)场景描述
假如有个用户的列表List,想要显示所有人的名字,要把名字用逗号作为分隔符,进行拼接
(2)优化前的写法
思路就是先把所有名字取出来放进list,然后再用String.join做拼接。然后代码规范校验就提示不规范了
String packUser = String.join(",",packPlans.stream().map(it->it.getPackUser()).collect(Collectors.toList()));
(3)优化后的写法
直接用Collectors.joining实现
String packUser = list.stream().collect(Collectors.joining(","));
【13】map方法对数据做转换操作
map函数的作用就是针对管道流中的每一个数据元素进行转换操作
(1)案例一
把集合中的每一个字符串,全部转换成大写
List<String> alpha = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
//不使用Stream管道流
List<String> alphaUpper = new ArrayList<>();
for (String s : alpha) {
alphaUpper.add(s.toUpperCase());
}
System.out.println(alphaUpper); //[MONKEY, LION, GIRAFFE, LEMUR]
// 使用Stream管道流
List<String> collect = alpha.stream().map(String::toUpperCase).collect(Collectors.toList());
//上面使用了方法引用,和下面的lambda表达式语法效果是一样的
//List<String> collect = alpha.stream().map(s -> s.toUpperCase()).collect(Collectors.toList());
System.out.println(collect); //[MONKEY, LION, GIRAFFE, LEMUR]
(2)案例二
处理非字符串类型集合元素
map函数不仅可以处理数据,还可以转换数据的类型
List<Integer> lengths = alpha.stream()
.map(String::length)
.collect(Collectors.toList());
System.out.println(lengths); //[6, 4, 7, 5]
Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.mapToInt(String::length)
.forEach(System.out::println);
输出:6 4 7 5
除了mapToInt。还有maoToLong,mapToDouble等等用法
(3)案例三:peek函数
处理对象数据格式转换
将每一个Employee的年龄增加一岁,将性别中的“M”换成“male”,F换成Female。
public static void main(String[] args){
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
/*List<Employee> maped = employees.stream()
.map(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
return e;
}).collect(Collectors.toList());*/
List<Employee> maped = employees.stream()
.peek(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
}).collect(Collectors.toList());
System.out.println(maped);
}
由于map的参数e就是返回值,所以可以使用peek函数,peek函数就是一种特殊的map函数,当函数没有返回值或者参数就是返回值的时候可以使用peek函数
(4)案例四:flatMap函数
map可以对管道流中的数据进行转换操作,但是如果管道中还有管道该如何处理?就是说:如何处理二维数组及二维集合类。实现一个简单的需求:
将“hello”,“world”两个字符串组成的集合,元素的每一个字母打印出来。如果不用Stream我们怎么写?写2层for循环,第一层遍历字符串,并且将字符串拆分成char数组,第二层for循环遍历char数组。
List<String> words = Arrays.asList("hello", "word");
words.stream()
.map(w -> Arrays.stream(w.split(""))) //[[h,e,l,l,o],[w,o,r,l,d]]
.forEach(System.out::println);
用map方法是做不到的,这个需求用map方法无法实现。map只能针对一维数组进行操作,数组里面还有数组,管道里面还有管道,它是处理不了每一个元素的。
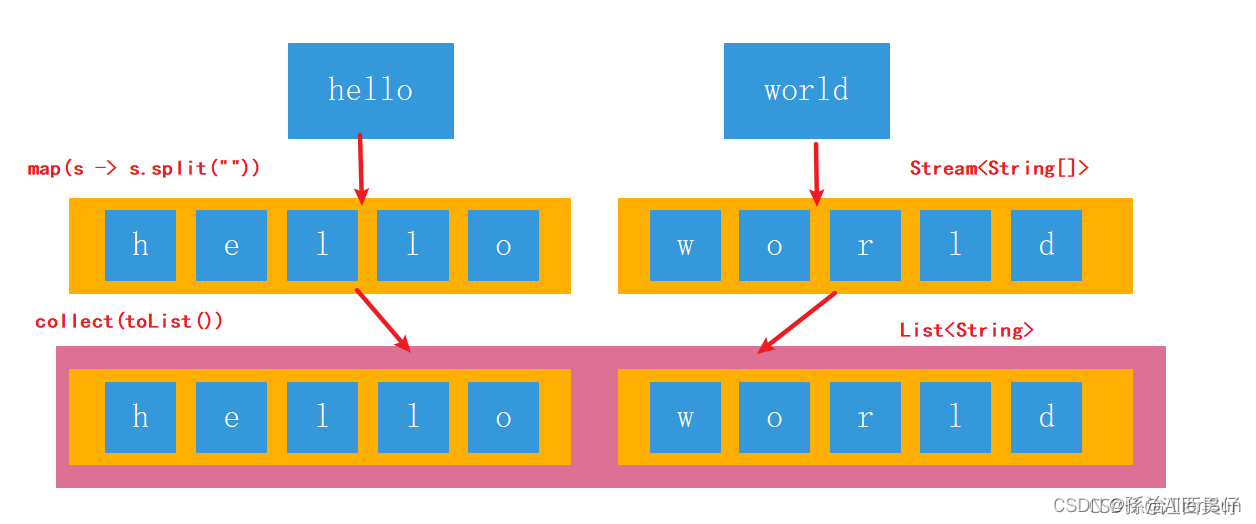
flatMap可以理解为将若干个子管道中的数据全都,平面展开到父管道中进行处理。
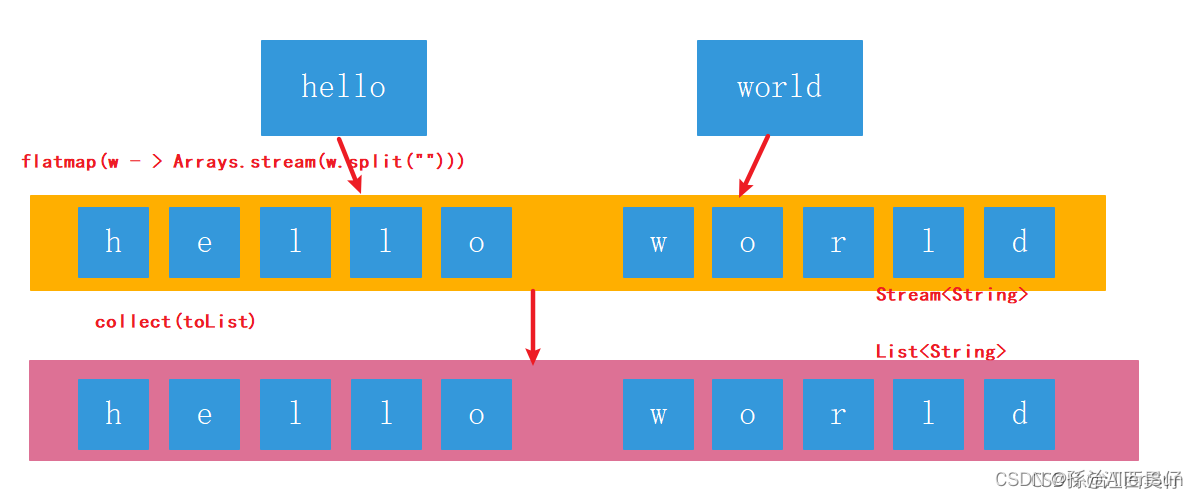
words.stream()
.flatMap(w -> Arrays.stream(w.split(""))) // [h,e,l,l,o,w,o,r,l,d]
.forEach(System.out::println);
【三】其他案例分析
【1】Optional.ofNullable:非空判断的详解
(1)简单认识
在开发过程中,碰到的最多的异常就是空指针异常NullPointerException,所以在平时编码中,经常要判断null。
public void saveCity(City city) {
if (city != null) {
String cityName = city.getCityName();
if (cityName != null) {
String code = cityDao.findCodeByName(cityName);
city.setCode(code);
cityDao.save(city);
}
}
}
上面的代码用了过多的if语句嵌套,降低代码整体的可读性,我们可以用stream进行优化
public void saveCity(City city) {
// 就一行 city不为空返回 城市名称 否则直接返回空
Optional<String> cityNameOpt = Optional.ofNullable(city).map(City::getCityName);
// 如果容器中 不为空
cityNameOpt.ifPresent(n -> {
String code = cityDao.findCodeByName(n);
city.setCode(code);
cityDao.save(city);
});
}
所以java.util.Optional类是Java8为了解决null值判断问题,而引入的一个同名Optional类。Optional类可以包含或不包含null值的容器对象。如果存在值,则isPresent方法将返回true,而get方法将返回该值。
(2)Optional源码分析和使用场景
(1)属性和构造
public final class Optional<T> {
// 这个是通用的代表NULL值的Optional实例
private static final Optional<?> EMPTY = new Optional<>();
// 泛型类型的对象实例
private final T value;
// 实例化Optional,注意是私有修饰符,value为NULL
private Optional() {
this.value = null;
}
// 直接返回内部的EMPTY实例
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
// 通过value实例化Optional,如果value为NULL则抛出NPE
private Optional(T value) {
this.value = Objects.requireNonNull(value);
}
// 通过value实例化Optional,如果value为NULL则抛出NPE,实际上就是使用Optional(T value)
public static <T> Optional<T> of(T value) {
return new Optional<>(value);
}
// 如果value为NULL则返回EMPTY实例,否则调用Optional#of(value)
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
// 暂时省略其他代码
}
实现的原理分析:
1.首先执行ofNullable()方法,如果T对象为空,执行empty()方法;不为空,执行of(value)方法;
2.empty()方法,初始化一个空对象Optional(空对象和null不是一回事哈);
3.of(value)方法,将泛型对象T用于Optional构造方法的参数上,返回一个有值的对象
4.经过上面两步,从而保证了Optional不为null,避免了空指针;
(2)基本的使用案例
可以看出,Optional类的两个构造方法都是private型的,因此类外部不能显示的使用new Optional()的方式来创建Optional对象,但是Optional类提供了三个静态方法empty()、of(T value)、ofNullable(T value)来创建Optinal对象,示例如下:
@Test
public void testConstructor() {
// 1、创建一个包装对象值为空的Optional对象
Optional<String> optStr = Optional.empty();
// 2、创建包装对象值非空的Optional对象
Optional<String> optStr1 = Optional.of("optional");
// 3、创建包装对象值允许为空的Optional对象
Optional<String> optStr2 = Optional.ofNullable(null);
System.out.println(optStr1 .get());// optional
System.out.println(optStr2 .get());//
System.out.println(optStr1 .isPresent());// true
System.out.println(optStr2 .isPresent());// false
}
(3)!搭配ifPresent方法的原理和案例!
是Java 8中Optional类的一个方法,它的作用是当Optional对象不为空时执行一个操作。如果Optional对象为空,则不执行任何操作。
ifPresent()方法接受一个Consumer对象(消费函数),如果包装对象的值非空,运行Consumer对象的accept()方法
public void ifPresent(Consumer<? super T> consumer) {
if (value != null)
consumer.accept(value);
}
使用案例
@Test
public void testIfPresent() {
Optional<String> optional = Optional.of("thinkwon");
optional.ifPresent(s -> System.out.println("the String is " + s));
}
输出结果:the String is thinkwon
(4)搭配filter方法的原理和案例
filter()方法接受参数为Predicate对象,用于对Optional对象进行过滤,如果符合Predicate的条件,返回Optional对象本身,否则返回一个空的Optional对象。
public Optional<T> filter(Predicate<? super T> predicate) {
Objects.requireNonNull(predicate);
if (!isPresent()) {
return this;
} else {
return predicate.test(value) ? this : empty();
}
}
使用案例
@Test
public void testFilter() {
Optional.of("thinkwon").filter(s -> s.length() > 2)
.ifPresent(s -> System.out.println("The length of String is greater than 2 and String is " + s));
}
输出结果:The length of String is greater than 2 and String is thinkwon
(5)搭配map方法的原理和案例
map()方法的参数为Function(函数式接口)对象,map()方法将Optional中的包装对象用Function函数进行运算,并包装成新的Optional对象(包装对象的类型可能改变)
public <U> Optional<U> map(Function<? super T, ? extends U> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent()) {
return empty();
} else {
return Optional.ofNullable(mapper.apply(value));
}
}
使用案例
@Test
public void testMap() {
Optional<String> optional = Optional.of("thinkwon").map(s -> s.toUpperCase());
System.out.println(optional.get());
}
输出结果:THINKWON
(6)搭配flatMap方法的原理和案例
跟map()方法不同的是,入参Function函数的返回值类型为Optional类型,而不是U类型,这样flatMap()能将一个二维的Optional对象映射成一个一维的对象。
public <U> Optional<U> flatMap(Function<? super T, ? extends Optional<? extends U>> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent()) {
return empty();
} else {
@SuppressWarnings("unchecked")
Optional<U> r = (Optional<U>) mapper.apply(value);
return Objects.requireNonNull(r);
}
}
使用案例
@Test
public void testFlatMap() {
Optional<String> optional = Optional.of("thinkwon").flatMap(s -> Optional.ofNullable(s.toUpperCase()));
System.out.println(optional.get());
}
输出结果:THINKWON
(7)!搭配orElse方法的原理和案例!
orElse()方法功能比较简单,即如果包装对象值非空,返回包装对象值,否则返回入参other的值(默认值)
public T orElse(T other) {
return value != null ? value : other;
}
使用案例
@Test
public void testOrElse() {
String unkown = (String) Optional.ofNullable(null).orElse("unkown");
System.out.println(unkown);
}
输出结果:unkown
optional.ofnullable().orelse() 是 Java 8 中 Optional 类的方法,用于判断 Optional 对象是否为空,如果为空则返回一个默认值。其中 ofNullable() 方法用于创建一个 Optional 对象,orElse() 方法用于返回一个默认值。如果 Optional 对象不为空,则返回 Optional 对象本身。这个方法可以用于避免 NullPointerException 异常。
List<String> lists = null;
List<String> list = new ArrayList<String>();
list.add("你好");
list.add("hello");
List<String> newList = Optional.ofNullable(list).orElse(lists);
如果list集合不为空,将list集合赋值给newList;如果list集合为空创建一个空对象集合赋值给newList,保证list集合永远不为空,也就避免了空指针异常。
public static void main(String[] args) {
List<String> list = null;
List<String> newList = Optional.ofNullable(list).orElse(Lists.newArrayList());
newList.forEach(x -> System.out.println(x));
}
(8)搭配orElseGet方法的原理和案例
orElseGet()方法与orElse()方法类似,区别在于orElseGet()方法的入参为一个Supplier对象,用Supplier对象的get()方法的返回值作为默认值
public T orElseGet(Supplier<? extends T> supplier) {
return value != null ? value : supplier.get();
}
使用案例
@Test
public void testOrElseGet() {
String unkown = (String) Optional.ofNullable(null).orElseGet(() -> "unkown");
System.out.println(unkown);
}
输出结果:unkown
(9)搭配orElseThrow方法的原理和案例
orElseThrow()方法其实与orElseGet()方法非常相似了,入参都是Supplier对象,只不过orElseThrow()的Supplier对象必须返回一个Throwable异常,并在orElseThrow()中将异常抛出,orElseThrow()方法适用于包装对象值为空时需要抛出特定异常的场景。
public <X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier) throws X {
if (value != null) {
return value;
} else {
throw exceptionSupplier.get();
}
}
使用案例
@Test
public void testOrElseThrow() {
Optional.ofNullable(null).orElseThrow(() -> new RuntimeException("unkown"));
}
输出结果:java.lang.RuntimeException: unkown
(10)常用的案例总结
(1)空判断
空判断主要是用于不知道当前对象是否为NULL的时候,需要设置对象的属性。不使用Optional时候的代码如下:
if(null != order){
order.setAmount(orderInfoVo.getAmount());
}
使用Optional时候的代码如下:
Optional.ofNullable(order).ifPresent(o -> o.setAmount(orderInfoVo.getAmount()));
使用Optional实现空判断的好处是只有一个属性设值的时候可以压缩代码为一行,这样做的话,代码会相对简洁。
(2)断言
在维护一些老旧的系统的时候,很多情况下外部的传参没有做空判断,因此需要写一些断言代码如:
if (null == orderInfoVo.getAmount()){
throw new IllegalArgumentException(String.format("%s订单的amount不能为NULL",orderInfoVo.getOrderId()));
}
if (StringUtils.isBlank(orderInfoVo.getAddress()){
throw new IllegalArgumentException(String.format("%s订单的address不能为空",orderInfoVo.getOrderId()));
}
使用Optional后的断言代码如下:
Optional.ofNullable(orderInfoVo.getAmount()).orElseThrow(()-> new IllegalArgumentException(String.format("%s订单的amount不能为NULL",orderInfoVo.getOrderId())));
Optional.ofNullable(orderInfoVo.getAddress()).orElseThrow(()-> new IllegalArgumentException(String.format("%s订单的address不能为空",orderInfoVo.getOrderId())));
(3)一些综合的使用案例
如果result不为null,就执行后面的操作,如果为null,就不执行任何操作了
Optional.ofNullable(result)
.map(ApiResponse::getData)
.ifPresent(it -> {
if (StrUtil.isNotBlank(it.getTmpScriptContent())) {
HiveSqlFieldLineageParser parser = HiveSqlFieldLineageParser.build(
it.getTmpScriptContent(), false, false);
it.setErrors(parser.getErrors());
}
});
(11)使用误区
(1)正确的使用创建方法,不确定是否为null时尽量选择ofNullable方法;
(2)通过源代码会发现,它并没有实现java.io.Serializable接口,因此应避免在类属性中使用,防止意想不到的问题;
(3)避免直接调用Optional对象的get和isPresent方法,尽量多使用map()、filter()、orElse()等方法来发挥Optional的作用。
(12)总结
Optional本质是一个对象容器,它的特征如下:
(1)Optional作为一个容器承载对象,提供方法适配部分函数式接口,结合部分函数式接口提供方法实现NULL判断、过滤操作、安全取值、映射操作等等。
(2)Optional一般使用场景是用于方法返回值的包装,当然也可以作为临时变量从而享受函数式接口的便捷功能。
(3)Optional只是一个简化操作的工具,可以解决多层嵌套代码的节点空判断问题(例如简化箭头型代码)。
(4)Optional并非银弹。
这里提到箭头型代码,下面尝试用常规方法和Optional分别解决:
// 假设VO有多个层级,每个层级都不知道父节点是否为NULL,如下
// - OrderInfoVo
// - UserInfoVo
// - AddressInfoVo
// - address(属性)
// 假设我要为address属性赋值,那么就会产生箭头型代码。
// 常规方法
String address = "xxx";
OrderInfoVo o = ...;
if(null != o){
UserInfoVo uiv = o.getUserInfoVo();
if (null != uiv){
AddressInfoVo aiv = uiv.getAddressInfoVo();
if (null != aiv){
aiv.setAddress(address);
}
}
}
// 使用Optional
String address = "xxx";
OrderInfoVo o = null;
Optional.ofNullable(o)
.map(OrderInfoVo::getUserInfoVo)
.map(UserInfoVo::getAddressInfoVo)
.ifPresent(a -> a.setAddress(address));
使用Optional解决箭头型代码,通过映射操作map()能减少大量的if和NULL判断分支,使得代码更加简洁。
【2】过滤出列表中对象的一个属性是否重复
描述:例如一个List,想要筛选出来User中姓名name相同的人。或者说我们要求某个属性不能存在重复,如果重复了就要过滤出来进行提醒。
Map<Object, Long> businessObjectMap = dataRequireInfo.stream().collect(
Collectors.groupingBy( DeinfoBusinessInfoCreateRequest::getBusinessObject , Collectors.counting()));
//筛出有重复的业务对象
List<Object> businessObjectList = businessObjectMap.keySet().stream().
filter(key -> businessObjectMap.get(key) > 1).collect(Collectors.toList());
if (businessObjectList.size()!=0) {
throw new YTRuntimeException("数据需求的业务对象"+businessObjectList.toString()+"存在重复!");
}
【3】Stream流过滤模糊字段数据
通过某个字段过滤列表的对象,但是是模糊过滤
Pattern pattern = Pattern.compile(".*" + fieldNm + ".*", Pattern.CASE_INSENSITIVE);
list.stream()
.filter(it -> pattern.matcher(it.getFieldNm()).matches() || pattern.matcher(it.getFieldChNm()).matches())
.collect(Collectors.toList());
【4】一些综合的使用案例
(1)Optional.ofNullable和ifPresent的搭配使用
Optional.ofNullable(ruleMap.get(jobName))
.ifPresent(ruleImportList -> {
for (int i = 0; i < ruleImportList.size(); i++) {
...
}
});
【四】List使用stream流转成map的几种方式
实体例子
public class Person {
private String name;
private String address;
public Person(String name, String address) {
this.name = name;
this.address = address;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
【1】List 转成Map<String,Object>
List<Person> list = new ArrayList<>();
Person person1 = new Person("熊大","森林第一个小屋");
Person person2 = new Person("熊二","森林第二个小屋");
Person person3 = new Person("光头强","森林第三个小屋");
Person person4 = new Person("熊大","森林第四个小屋");
list.add(person1);
list.add(person2);
list.add(person3);
list.add(person4);
Map<String,Person> map = list.stream().collect(Collectors.toMap(Person::getName,each->each,(value1, value2) -> value1));
System.out.println(JSON.toJSONString(map));
控制台打印日志:
{“光头强”:{“address”:“森林第三个小屋”,“name”:“光头强”},“熊大”:{“address”:“森林第一个小屋”,“name”:“熊大”},“熊二”:{“address”:“森林第二个小屋”,“name”:“熊二”}}
【2】List 转成Map<String,String>
List<Person> list = new ArrayList<>();
Person person1 = new Person("熊大","森林第一个小屋");
Person person2 = new Person("熊二","森林第二个小屋");
Person person3 = new Person("光头强","森林第三个小屋");
Person person4 = new Person("熊大","森林第四个小屋");
list.add(person1);
list.add(person2);
list.add(person3);
list.add(person4);
Map<String,String> map = list.stream().collect(Collectors.toMap(Person::getName,Person::getAddress,(value1, value2) -> value1));
System.out.println(JSON.toJSONString(map));
控制台打印日志:
{“光头强”:“森林第三个小屋”,“熊大”:“森林第一个小屋”,“熊二”:“森林第二个小屋”}
【3】List 转成Map<String,List>
(1)方法一
List<Person> list = new ArrayList<>();
Person person1 = new Person("熊大","森林第一个小屋");
Person person2 = new Person("熊二","森林第二个小屋");
Person person3 = new Person("光头强","森林第三个小屋");
Person person4 = new Person("熊大","森林第四个小屋");
list.add(person1);
list.add(person2);
list.add(person3);
list.add(person4);
Map<String, List<Person>> map = list.stream().collect(Collectors.groupingBy(Person::getName));
System.out.println(JSON.toJSONString(map));
控制台打印日志:
{“光头强”:[{“address”:“森林第三个小屋”,“name”:“光头强”}],“熊大”:[{“address”:“森林第一个小屋”,“name”:“熊大”},{“address”:“森林第四个小屋”,“name”:“熊大”}],“熊二”:[{“address”:“森林第二个小屋”,“name”:“熊二”}]}
(2)方法二
List<Person> list = new ArrayList<>();
Person person1 = new Person("熊大","森林第一个小屋");
Person person2 = new Person("熊二","森林第二个小屋");
Person person3 = new Person("光头强","森林第三个小屋");
Person person4 = new Person("熊大","森林第四个小屋");
list.add(person1);
list.add(person2);
list.add(person3);
list.add(person4);
Map<String,List<Person>> map = list.stream().collect(Collectors.toMap(Person::getName,each->Collections.singletonList(each),(value1, value2) -> {
List<Person> union = new ArrayList<>(value1);
union.addAll(value2);
return union;
}));
System.out.println(JSON.toJSONString(map));
控制台打印日志:
{“光头强”:[{“address”:“森林第三个小屋”,“name”:“光头强”}],“熊大”:[{“address”:“森林第一个小屋”,“name”:“熊大”},{“address”:“森林第四个小屋”,“name”:“熊大”}],“熊二”:[{“address”:“森林第二个小屋”,“name”:“熊二”}]}
【4】List 转成Map<String,List>
List<Person> list = new ArrayList<>();
Person person1 = new Person("熊大","森林第一个小屋");
Person person2 = new Person("熊二","森林第二个小屋");
Person person3 = new Person("光头强","森林第三个小屋");
Person person4 = new Person("熊大","森林第四个小屋");
list.add(person1);
list.add(person2);
list.add(person3);
list.add(person4);
Map<String,List<String>> map = list.stream().collect(Collectors.toMap(Person::getName,each->Collections.singletonList(each.getAddress()),(value1, value2) -> {
List<String> union = new ArrayList<>(value1);
union.addAll(value2);
return union;
}));
System.out.println(JSON.toJSONString(map));
控制台打印日志:
{“光头强”:[“森林第三个小屋”],“熊大”:[“森林第一个小屋”,“森林第四个小屋”],“熊二”:[“森林第二个小屋”]}
【5】List<Map<String,Object>> 转成Map<String,Map<String,Object>>
List<Map<String,Object>> list = new ArrayList<>();
Person person1 = new Person("熊大","森林第一个小屋");
Person person2 = new Person("熊二","森林第二个小屋");
Person person3 = new Person("光头强","森林第三个小屋");
Map<String,Object> map1 = new HashMap<>();
map1.put("id","1");
map1.put("person",person1);
Map<String,Object> map2 = new HashMap<>();
map2.put("id","2");
map2.put("person",person2);
Map<String,Object> map3 = new HashMap<>();
map3.put("id","3");
map3.put("person",person3);
list.add(map1);
list.add(map2);
list.add(map3);
Map<String,Map<String,Object>> map = list.stream().collect(Collectors.toMap(each->Objects.toString(each.get("id"),""),each->each,(key1,key2)->key1));
System.out.println(JSON.toJSONString(map));
控制台打印日志:
{“1”:{“person”:{“address”:“森林第一个小屋”,“name”:“熊大”},“id”:“1”},“2”:{“person”:{“address”:“森林第二个小屋”,“name”:“熊二”},“id”:“2”},“3”:{“person”:{“address”:“森林第三个小屋”,“name”:“光头强”},“id”:“3”}}
【6】List<Map<String,Object>> 转成Map<String,Object>
List<Map<String,Object>> list = new ArrayList<>();
Person person1 = new Person("熊大","森林第一个小屋");
Person person2 = new Person("熊二","森林第二个小屋");
Person person3 = new Person("光头强","森林第三个小屋");
Map<String,Object> map1 = new HashMap<>();
map1.put("id","1");
map1.put("person",person1);
Map<String,Object> map2 = new HashMap<>();
map2.put("id","2");
map2.put("person",person2);
Map<String,Object> map3 = new HashMap<>();
map3.put("id","3");
map3.put("person",person3);
list.add(map1);
list.add(map2);
list.add(map3);
Map<String,Object> map = list.stream().collect(Collectors.toMap(each->Objects.toString(each.get("id"),""),each->each.get("person"),(key1,key2)->key1));
System.out.println(JSON.toJSONString(map));
控制台打印日志:
{“1”:{“address”:“森林第一个小屋”,“name”:“熊大”},“2”:{“address”:“森林第二个小屋”,“name”:“熊二”},“3”:{“address”:“森林第三个小屋”,“name”:“光头强”}}
【7】List<Map<String,String>> 转成Map<String,Map<String,String>>
List<Map<String,String>> list = new ArrayList<>();
Map<String,String> map1 = new HashMap<>();
map1.put("id","1");
map1.put("name","熊大");
map1.put("address","森林第一个小屋");
Map<String,String> map2 = new HashMap<>();
map2.put("id","2");
map2.put("name","熊二");
map2.put("address","森林第二个小屋");
Map<String,String> map3 = new HashMap<>();
map3.put("id","3");
map3.put("name","光头强");
map3.put("address","森林第三个小屋");
list.add(map1);
list.add(map2);
list.add(map3);
Map<String,Map<String,String>> map = list.stream().collect(Collectors.toMap(each->each.get("id"),each->each,(key1,key2)->key1));
System.out.println(JSON.toJSONString(map));
控制台打印日志:
{“1”:{“address”:“森林第一个小屋”,“name”:“熊大”,“id”:“1”},“2”:{“address”:“森林第二个小屋”,“name”:“熊二”,“id”:“2”},“3”:{“address”:“森林第三个小屋”,“name”:“光头强”,“id”:“3”}}
【8】List<Map<String,String>> 转成Map<String,String>
List<Map<String,String>> list = new ArrayList<>();
Map<String,String> map1 = new HashMap<>();
map1.put("id","1");
map1.put("name","熊大");
map1.put("address","森林第一个小屋");
Map<String,String> map2 = new HashMap<>();
map2.put("id","2");
map2.put("name","熊二");
map2.put("address","森林第二个小屋");
Map<String,String> map3 = new HashMap<>();
map3.put("id","3");
map3.put("name","光头强");
map3.put("address","森林第三个小屋");
list.add(map1);
list.add(map2);
list.add(map3);
Map<String,String> map = list.stream().collect(Collectors.toMap(each->each.get("id"),each->each.get("name"),(key1,key2)->key1));
System.out.println(JSON.toJSONString(map));
控制台打印日志:
{“1”:“熊大”,“2”:“熊二”,“3”:“光头强”}
【五】Map转成List
【六】查找重复的值
【1】java8获取list集合中重复的元素
//单独String集合
List<String> list = Arrays.asList("a","b","a","c","d","b");
List<String> collect = list.stream().filter(i -> i != "") // list 对应的 Stream 并过滤""
.collect(Collectors.toMap(e -> e, e -> 1, Integer::sum)) // 获得元素出现频率的 Map,键为元素,值为元素出现的次数
.entrySet()
.stream() // 所有 entry 对应的 Stream
.filter(e -> e.getValue() > 1) // 过滤出元素出现次数大于 1 (重复元素)的 entry
.map(Map.Entry::getKey) // 获得 entry 的键(重复元素)对应的 Stream
.collect(Collectors.toList());
System.out.println(collect);
【2】java8根据List对象属性获取重复数据和获取去重后数据
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("张三", 8, 3000));
personList.add(new Person("李四", 18, 5000));
personList.add(new Person("王五", 28, 7000));
personList.add(new Person("孙六", 38, 9000));
personList.add(new Person("孙六", 38, 9000));
personList.add(new Person("孙六", 38, 10000));
//1.先根据得到一个属于集合 姓名
List<String> uniqueList = personList.stream().collect(Collectors.groupingBy(Person::getName, Collectors.counting()))
.entrySet().stream().filter(e -> e.getValue() > 1)
.map(Map.Entry::getKey).collect(Collectors.toList());
uniqueList.forEach(p -> System.out.println(p));
//计算两个list中的重复值 3条数据
List<Person> reduce1 = personList.stream().filter(item -> uniqueList.contains(item.getName())).collect(Collectors.toList());
System.out.println(reduce1.toString());
//2.根据多个属性获取重复数据,只能重复操作得到重复的数据 工资
List<Integer> collect1 = reduce1.stream().collect(Collectors.groupingBy(Person::getWages, Collectors.counting()))
.entrySet().stream().filter(e -> e.getValue() > 1)
.map(Map.Entry::getKey).collect(Collectors.toList());
//计算两个list中的差集
List<Person> collect2 = reduce1.stream().filter(item -> collect1.contains(item.getWages())).collect(Collectors.toList());
System.out.println(collect2.toString());
【3】获取去重后数据
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("张三", 8, 3000));
personList.add(new Person("李四", 18, 5000));
personList.add(new Person("王五", 28, 7000));
personList.add(new Person("孙六", 38, 9000));
personList.add(new Person("孙六", 38, 9000));
personList.add(new Person("孙六", 38, 10000));
//去重
List<Person> unique = personList.stream().collect(Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Person::getName))), ArrayList::new));
System.out.println("unique:"+unique.toString());
【4】List集合取交集
使用Java 8的Stream API
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class ListIntersection {
public static void main(String[] args) {
List<Integer> list1 = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> list2 = Arrays.asList(4, 5, 6, 7, 8);
List<Integer> intersection = list1.stream()
.filter(list2::contains)
.collect(Collectors.toList());
System.out.println("Intersection: " + intersection);
}
}
这段代码首先创建了两个 List 对象 list1 和 list2。然后,通过 list1.stream() 获取 list1 的Stream对象,并使用 filter 方法筛选出同时存在于 list2 中的元素。最后,使用 collect 方法将结果转换回 List 对象。
【七】flatMap案例解析
【1】map 和 flatMap 对应的源码
(1)map方法
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
(2)flatMap方法
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
可以看到,不论是 map 还是 flatMap 方法,都是对以流的形式数据的处理,返回值同样都是流形式数据的泛型。本质一样,都是 map 操作,但是不同点在于,flatMap 操作会比 map 多一个 flat 操作。
"flat"单词本意有平的、扁平的含义,在源码中,我们对于 flatMap 方法中 API Note 有这样一句话:“The flatMap() operation has the effect of applying a one-to-many transformation to the elements of the stream, and then flattening the resulting elements into a new stream.”,含义是:flatMap()操作的效果是对流的元素应用一对多转换,然后将生成的元素展平为新的流。而 map 方法的返回是:返回由将给定函数应用于此流元素的结果组成的流。
【2】代码演示
(1)两个类,一个 Library 类,一个 Book 类
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode
public class Library {
private String name;
private List<Book> book;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode
public class Book {
private String name;
private String author;
private Integer price;
}
(2)测试类
public class StreamTest {
public static void main(String[] args) {
System.out.println("---------->存储的图书信息: ");
System.out.println(initInfo());
System.out.println("---------->测试map方法:");
testMap();
System.out.println("---------->测试flatMap方法:");
testFlatMap();
}
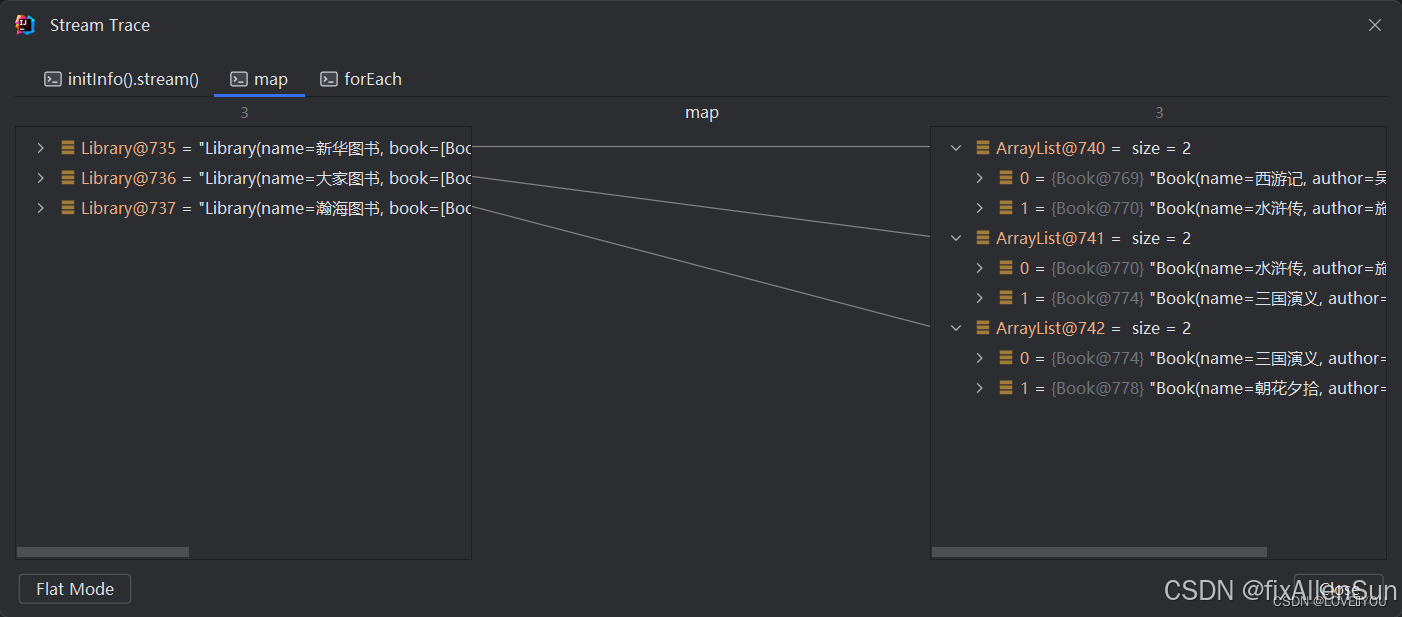
private static void testMap() {
initInfo().stream()
.map(library -> library.getBook())
.forEach(book -> System.out.println(book));
}
private static void testFlatMap() {
initInfo().stream()
.flatMap(library -> library.getBook().stream())
.forEach(book -> System.out.println(book));
}
public static List<Library> initInfo() {
Library library1 = new Library("新华图书", null);
Library library2 = new Library("大家图书", null);
Library library3 = new Library("瀚海图书", null);
Book book1 = new Book("西游记", "吴承恩", 49);
Book book2 = new Book("水浒传", "施耐庵", 57);
Book book3 = new Book("三国演义", "罗贯中", 52);
Book book4 = new Book("朝花夕拾", "鲁迅", 30);
List<Book> library1Book = new ArrayList<>();
List<Book> library2Book = new ArrayList<>();
List<Book> library3Book = new ArrayList<>();
library1Book.add(book1);
library1Book.add(book2);
library2Book.add(book2);
library2Book.add(book3);
library3Book.add(book3);
library3Book.add(book4);
library1.setBook(library1Book);
library2.setBook(library2Book);
library3.setBook(library3Book);
return new ArrayList<>(Arrays.asList(library1, library2, library3));
}
}
(3)测试结果

我们可以看到利用 flatMap 方法后,流中的数据被展平,消除了List的层级解构,但是 map 中的数据仍然存在层级结构。
map 方法流的中间过程
flatMap 方法流的中间过程
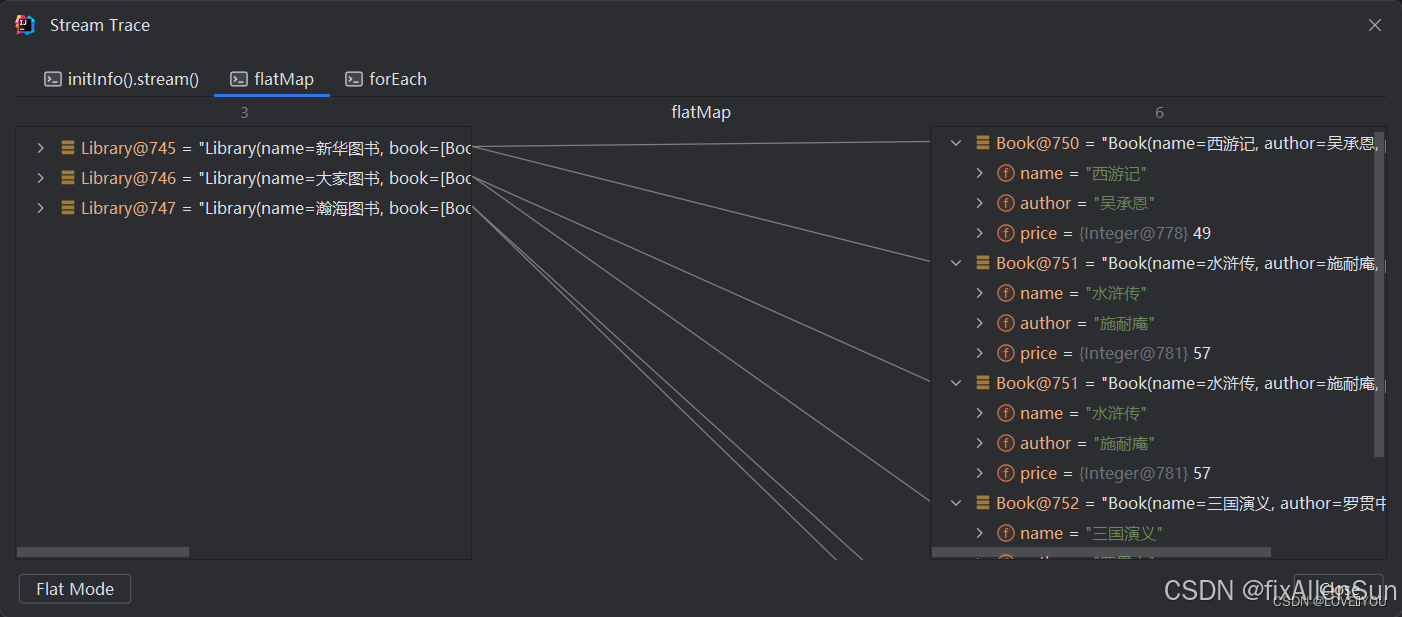
可以清楚的看到,map 方法应用后是存在层级结构的,返回的流是List组成的流,而 flatMap 中消除了List的层级结构,返回的流是 Book 组成的流。
【3】总结
当我们需要将具有层级结构的数据展平时,也就是将多层数据转换为单层数据操作时,我们可以使用 flatMap 方法。如果我们只是简单的对流中的数据计算或者转换时,可以使用 map 方法。
举例:
(1)使用 flatMap:[a,b,c,d,[e,f [g,h,i]]] 转换为 [a,b,c,d,e,f,g,h,i]
(2)使用 map: [1,2,3,4,5,6] 转换为 [11,12,13,14,15,16]
(3)使用 map: [a,b,c] 转换为 [A,B,C]


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









