







【redis-04】redis实现分布式锁
【一】使用分布式锁的场景
(1)为什么要用分布式锁?
(1)单服务器环境下超卖的情况
例如单个服务器的电商系统,一个用户调用下单接口,要先调用检查库存的接口去检查库存。在并发的时候,会预先把商品的库存存在redis中,下单的时候会更新redis的库存。如果有两个请求同时到来,请求1执行到锁定库存,更新数据库的库存为0,但是还没执行到更新redis的库存为0。而请求2刚好执行到检查redis库存,发现redis的库存还是1,这时候请求2就会继续去锁定数据库的库存并且修改数据库库存-1,就会出现超卖的情况。
(2)解决方案
加锁,把【检查redis库存】【锁定数据库库存】【更新数据库库存】【更新redis库存】的整个流程都上锁,只有当请求1这一整套流程执行完的时候,另一个线程请求2才能进行执行【检查redis库存】
(3)实现方式
使用java提供的synchronized或者ReentrantLock来锁住,然后在【更新数据库和redis库存量】执行完以后再释放锁
(4)换成分布式系统以后怎么办?
上面的加锁方案有个问题,锁是加在服务器里的业务代码上的,如果是分布式系统下有多个服务器,通过Nginx实现负载均衡,那么服务器A上的锁对服务器B上的代码是不起作用的,两个线程可以在两个不同的服务器上同时完成删减库存的操作。
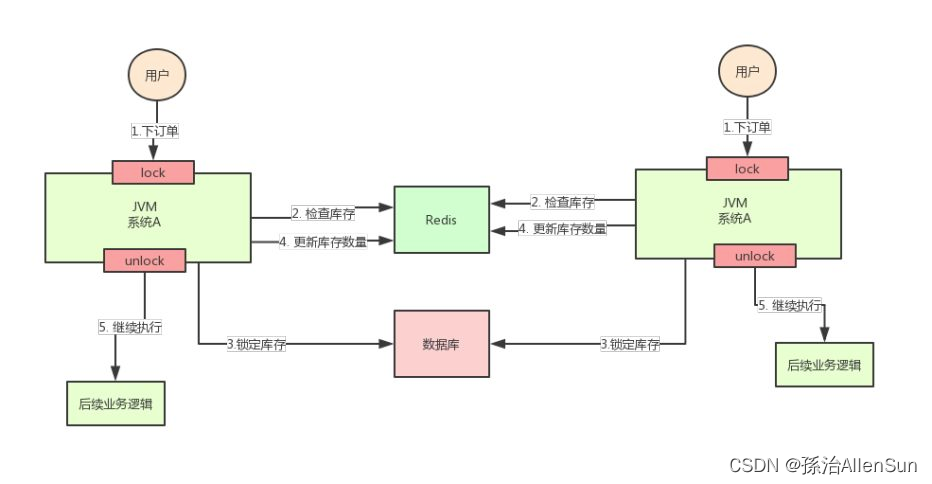 因为使用的Java的锁是只对自己JVM里面的线程才是有效的,对于其他的JVM的线程是无效的。也就是说Java提供的原生锁在集群分布的场景下就会失效。
因为使用的Java的锁是只对自己JVM里面的线程才是有效的,对于其他的JVM的线程是无效的。也就是说Java提供的原生锁在集群分布的场景下就会失效。
(5)分布式锁的方案
既然Java的原生锁在分布式场景下会失效,那就尝试保证多个服务器加的锁事同一个锁。分布式锁的思路就是:在整个系统中提供一个全局、唯一的获取锁的“东西”,然后在每个系统要加锁的时候,都去找这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁,这个“东西”可以是Redis、zookeeper或者数据库。
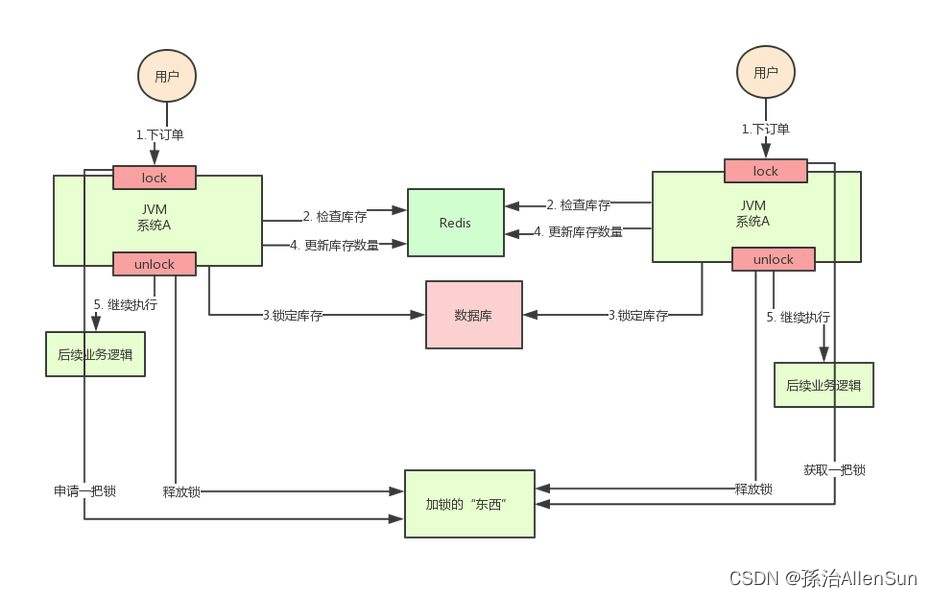
(2)为什么redis可以实现分布式锁
因为redis是一个单独的非业务服务,不会受到其他业务服务的限制,所有的业务服务都可以向redis发送写入命令,且只有一个业务服务可以写入命令成功,那么这个写入命令成功的服务即获得了锁,可以进行后续对资源的操作,其他未写入成功的服务,则进行其他处理。
(3)Redis实现分布式锁的命令介绍
(1)认识SETNX命令

(2)redis加锁命令:SET NX PX
在redis中设置一个值表示加了锁,然后释放锁的时候就把这个key删除
获取锁的时候
// 获取锁
// NX是指如果key不存在就成功,key存在返回false,PX可以指定过期时间
// 给key=anyLock设置一个值value=unique_value
SET anyLock unique_value NX PX 30000
(3)释放锁的时候
// 释放锁:通过执行一段lua脚本
// 释放锁涉及到两条指令,这两条指令不是原子性的
// 需要用到redis的lua脚本支持特性,redis执行lua脚本是原子性的
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
(4)通过Java实现的加锁代码:edisTemplate.opsForValue().setIfAbsent
// 设置一个当做锁的key值
String lockKey = "lock:product_101";
// 生成一个客户端id值,用来判断当前的锁是不是当前的线程加的,判断是否有删除锁的权限
String clientId = UUID.randomUUID().toString();
// 以固定值为key,以随机值为value,并且设置过期时间,且该命令有原子性
// setIfAbsent判断当前key值为空的时候才可以设值,并且有效时间为10s,10s以后该key值失效变为空
Boolean result = redisTemplate.opsForValue().setIfAbsent(lockKey,clientId,10, TimeUnit.SECONDS);
(5)通过Java实现的释放锁代码:redisTemplate.delete(lockKey);
(6)实现分布式锁的过程
Nginx对请求进行负载均衡,随机发到其中一个服务器上,然后去处理数据,先来到缓存redis里,两个服务器用的是同一个redis,那么就在redis里设置一个值,必须设置成功才能处理数据,否则等待,就相当于上了一把锁。
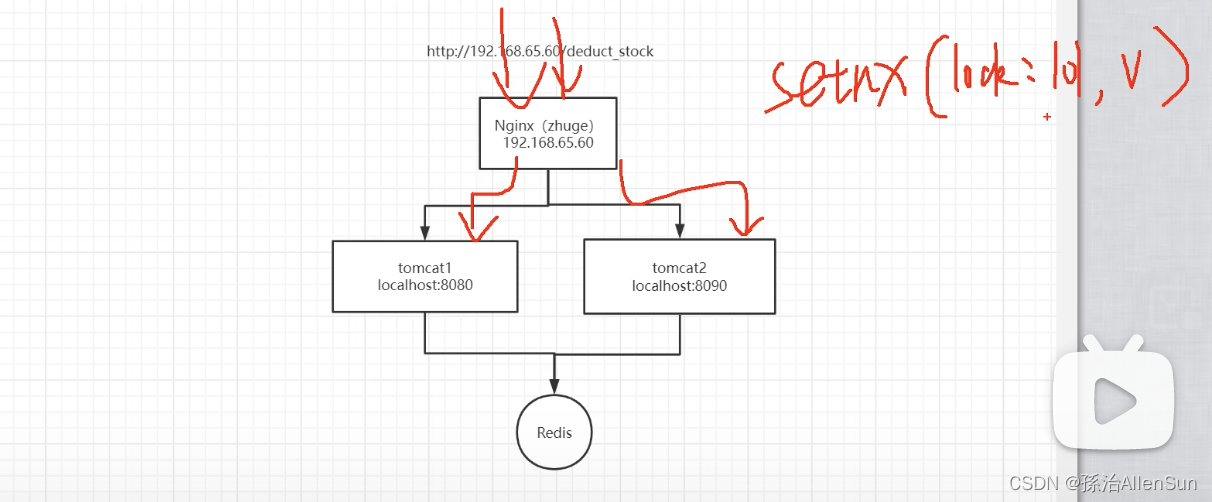
【二】redis实现分布式锁
(1)没有加锁的情况
// http://localhost:8080/redisLock/deduct_stock_01
@RequestMapping("/redisLock/deduct_stock_01")
public String deductStock_01() {
// redisTemplate.opsForValue().set("stock","1000");
// int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
synchronized (this.getClass()) {
Object stock = redisTemplate.opsForValue().get("stock");
int stockNum = Integer.parseInt(stock.toString());
if(stockNum>0){
int realStock = stockNum-1;
redisTemplate.opsForValue().set("stock",realStock+"");
System.out.println("扣减成功,剩余库存:"+realStock);
} else {
System.out.println("扣减失败,库存不足");
}
}
return "end";
}
(2)使用RedisTemplate实现加分布式锁
注意的是lock:product_101应该是动态获取的
@RequestMapping("/redisLock/deduct_stock_02")
public String deductStock_02(Product product) {
// 设置一个当做锁的key值
String lockKey = "lock:product_"+product.getId();
模拟情况下先写死,假如是对101号商品进行减库存,那么上锁之后,其他服务器对101号商品的修改操作都要先成功给lock:product_101设置值后才能操作,否则就是获取锁失败,无法进行操作
// http://localhost:8080/redisLock/deduct_stock_02
@RequestMapping("/redisLock/deduct_stock_02")
public String deductStock_02() {
// 设置一个当做锁的key值
String lockKey = "lock:product_101";
// 生成一个客户端id值,用来判断当前的锁是不是当前的线程加的,判断是否有删除锁的权限
String clientId = UUID.randomUUID().toString();
// 以固定值为key,以随机值为value,并且设置过期时间,且该命令有原子性
// setIfAbsent判断当前key值为空的时候才可以设值,并且有效时间为10s,10s以后该key值失效变为空
Boolean result = redisTemplate.opsForValue().setIfAbsent(lockKey,clientId,10, TimeUnit.SECONDS);
// 尝试给固定的key值设置value,如果设置不成功就返回错误信息
if(!result){
return "系统繁忙,请重试";
}
// 给代码执行的主体加上try-finally,这样无论执行结果如何,最终都会删除固定key值
// 避免业务代码出现异常卡顿以后锁删不掉的情况
try {
Object stock = redisTemplate.opsForValue().get("stock");
int stockNum = Integer.parseInt(stock.toString());
if(stockNum>0){
int realStock = stockNum-1;
redisTemplate.opsForValue().set("stock",realStock+"");
System.out.println("扣减成功,剩余库存:"+realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
// 为了防止时间刚好超期,当前线程还没来得及删除锁,其他线程也可以获取锁并删除锁了
// 这里在删除锁之前先判断当前线程的随机value值和之前锁的value是否相等,来判断身份
if(clientId.equals(redisTemplate.opsForValue().get(lockKey))){
redisTemplate.delete(lockKey);
}
}
return "end";
}
(3)redis实现分布式的过程
(1)设置一个当做锁的key值,可以是参数传的值,加一个前缀
(2)设置一个clientId值,可以使随机生成的UUID
(3)通过命令:redisTemplate.opsForValue().setIfAbsent(lockKey,clientId,10, TimeUnit.SECONDS) 来尝试加锁,当lockKey为空的时候才能设置成功,并且有效时间为10s,10s以后该key值失效变为空,自动失效为空可以避免宕机情况下造成锁无法释放的死锁情况
命令会返回一个result结果,如果result为true则说明设值成功
(4)在try-catch中执行业务代码,在finally里中执行value比较的判断和删除key的操作,保证有无异常都会删除锁,并且每个线程只能删除自己加的锁
(4)这个代码在高并发下可能出现的问题、解决方案
(1)为了避免业务代码出现异常卡顿导致没有删除锁,可以使用try-catch-finally,把业务代码放到try里,把redisTemplate.delete(lockKey);删除锁的命令放到finally里,这样即使抛出异常了也能成功删除锁
(2)如何避免执行到业务代码的时候宕机了,也没有抛出异常,最后没有删除锁,可以在setIfAbsent命令里加上超时的参数,指定上锁后多长时间后会锁会自动失效删除
(3)如果在有效时间内线程1的业务没有处理完,线程1加的锁已经失效了,高并发场景下线程2进来加锁成功了,然后线程1继续往下走,走到删除锁的时候,就会把刚刚线程2加的锁给删了。为了避免当前请求上的锁被其他线程删除了,就要判断当前的锁是不是当前线程上的,就要在删除锁之前加上判断,判断value值缓存里的value是否相等,相同才能删除缓存。
(4)删除锁命令加了if判断之后还是有可能出问题,加入执行到if判断并通过的时候到9.9秒了,然后卡顿,超过10s了这个锁失效,新的线程2加锁成功,线程1卡顿恢复后执行删除锁,删的就是线程2 的锁,所以还是没有保证原子性,会出现并发问题。我们可以通过Lua脚本,将这两个操作合并成一个操作,就可以保证其原子性了。怎么解决这个过期时间的问题?
(5)有效时间内业务没有处理完,怎么自动续时,也就是锁续命。当锁到时间了,开启一个守护线程,锁快到失效时间的时候,先到redis里判断key是否还存在,存在就说明还没有执行删除锁,就给锁续命。如果出现了服务器宕机,redis存的key还是会在已经设置的有效时间内自动失效,不影响原来死锁的解决方案。
(5)redis分布式锁的其他问题
(1)如果是使用单机部署模式,会存在单点问题,只要redis故障了,加锁就会失效。
(2)使用主从的模式,加锁的时候只对一个节点加锁,如果master节点故障了,发生了主从切换,此时就会有可能出现锁丢失的问题。
(3)如果使用redlock的算法,加锁的时候获取当前时间戳,然后轮流在每个master节点上创建锁,客户端计算好创建锁的时间,如果建立锁的时候小于超时时间,就算创建成功。如果超时了创建失败就得依次删除这个锁,需要这样不断的轮询去尝试获取锁。这样无法保证加锁的过程一定正确。
【三】redis锁的问题以及解决方案
(1)避免死锁
设置键过期时间,超过这个时间即给key删除掉。这样的话,就算当前服务获取到锁后宕机了,这个key也会在一定时间后被删除,其他服务照样可以继续获取锁。给serverLock键设置一个10秒的过期时间,10秒后会自动删除该键。

这样虽然解决了上面说的问题,但是又会引入新的问题。
假如服务A加锁成功,锁会在10s后自动释放,但由于业务复杂,执行时间过长,10s内还没执行完,此时锁已经被redis自动释放掉了。此时服务B就重新获取到了该锁,服务B开始执行他的业务,服务A在执行到第12s的时候执行完了,那么服务A会去释放锁,则此时释放的却是服务B刚获取到的锁。
这会有锁过期和释放其他服务锁这种严重的问题。
(2)锁过期处理
虽然可以通过增加删除key时间来处理这个问题,但是并没有从根本上解决。假设设个100s,绝大多数都是1s后就会释放锁,但是由于服务宕机,则会导致100s内其他服务都无法获取到锁,这也是灾难性的。
我们可以这样做,在锁将要过期的时候,如果服务还没有处理完业务,那么将这个锁再续一段时间。比如设置key在10s后过期,那么再开启一个守护线程,在第8s的时候检测服务是否处理完,如果没有,则将这个key再续10s后过期。
在Redisson(Redis SDK客户端)中,就已经帮我们实现了这个功能,这个自动续时的我们称其为”看门狗”。
(3)redis宕机问题
这个时候就得引入redis集群了。
但是涉及到redis集群,就会有新的问题出现,假设是主从集群,且主从数据并不是强一致性。当主节点宕机后,主节点的数据还未来得及同步到从节点,进行主从切换后,新的主节点并没有老的主节点的全部数据,这就会导致刚写入到老的主节点的锁在新的主节点并没有,其他服务来获取锁时还是会加锁成功。此时则会有2个服务都可以操作公共资源,此时的分布式锁则是不安全的。
redis的作者也想到这个问题,于是他发明了RedLock。
【四】Redisson实现分布式锁(解决上面的问题)
(1)什么是Redisson
(2)Redisson实现分布式锁的代码
使用开源框架Redission
创建redisson的对象,然后调用getLock方法设定一个唯一的值,表示一把锁lock,然后对象lock调用方法lock或者unlock来加锁和释放锁。
// http://localhost:8080/redisLock/deduct_stock_03
@RequestMapping("/redisLock/deduct_stock_03")
public String deductStock_03() {
String lockKey = "lock:product_101";
// (1)索取锁对象
RLock redissonLock = redisson.getLock(lockKey);
// (2)加锁
redissonLock.lock();
try {
Object stock = redisTemplate.opsForValue().get("stock");
int stockNum = Integer.parseInt(stock.toString());
if(stockNum>0){
int realStock = stockNum-1;
redisTemplate.opsForValue().set("stock",realStock+"");
System.out.println("扣减成功,剩余库存:"+realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
// (3)解锁
redissonLock.unlock();
}
return "end";
}
(3)Redisson实现分布式锁的原理?如何实现的锁续命?
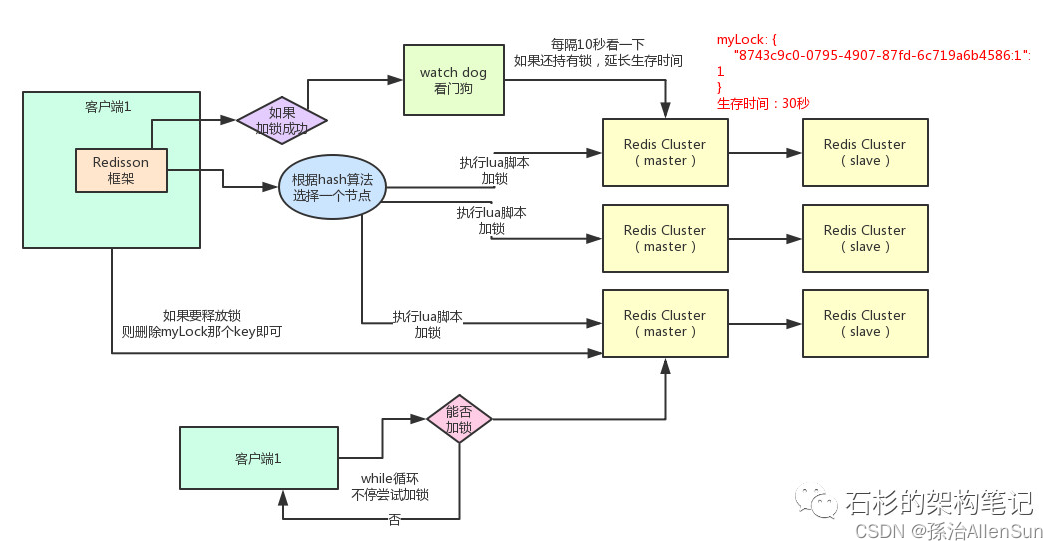
(1)加锁机制
咱们来看上面那张图,现在某个客户端要加锁。如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器。
这里注意,仅仅只是选择一台机器!这点很关键!
紧接着,就会发送一段lua脚本到redis上,那段lua脚本如下所示:
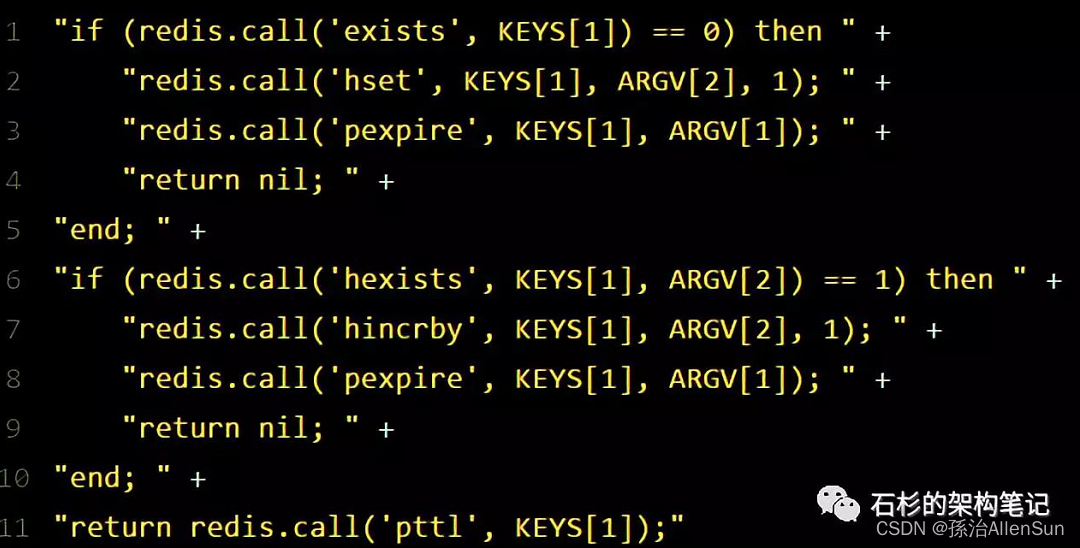 为啥要用lua脚本呢?因为一大坨复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性。
为啥要用lua脚本呢?因为一大坨复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性。
第一段if判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。
如何加锁呢?很简单,用下面的命令:
hset myLock
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
通过这个命令设置一个hash数据结构,这行命令执行后,会出现一个类似下面的数据结构:
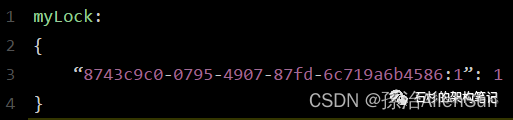 上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁key完成了加锁。
上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁key完成了加锁。
接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒。
加锁完成!
(2)锁互斥机制
那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?
很简单,第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。
接着第二个if判断,判断一下,myLock锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。
此时客户端2会进入一个while循环,不停的尝试加锁。
(3)watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
(4)可重入加锁机制
那如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?
比如下面这种代码:
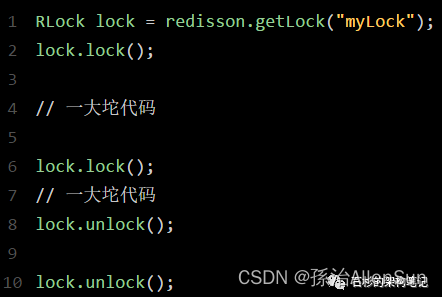 第一个if判断肯定不成立,“exists myLock”会显示锁key已经存在了。
第一个if判断肯定不成立,“exists myLock”会显示锁key已经存在了。
第二个if判断会成立,因为myLock的hash数据结构中包含的那个ID,就是客户端1的那个ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”
此时就会执行可重入加锁的逻辑,他会用:
incrby myLock 8743c9c0-0795-4907-87fd-6c71a6b4586:1 1
通过这个命令,对客户端1的加锁次数,累加1。那个myLock的hash数据结构中的那个客户端ID,就对应着加锁的次数
(5)释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。
其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:“del myLock”命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
(6)上述redis分布式锁的缺点
如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。

















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









