







 该博客介绍了在西瓜书第三章中,作者通过自制的训练集和测试集,分别使用LDA和QDA算法进行分类,并在Python中实现。LDA利用sklearn的LinearDiscriminantAnalysis,QDA则采用QuadraticDiscriminantAnalysis。实验结果显示QDA在高斯分布数据上的表现优于LDA,但LDA在降维方面更具优势。
该博客介绍了在西瓜书第三章中,作者通过自制的训练集和测试集,分别使用LDA和QDA算法进行分类,并在Python中实现。LDA利用sklearn的LinearDiscriminantAnalysis,QDA则采用QuadraticDiscriminantAnalysis。实验结果显示QDA在高斯分布数据上的表现优于LDA,但LDA在降维方面更具优势。
西瓜书第三章:LDA(及详细Fisher实现),QDA的python实现[仅代码实现]
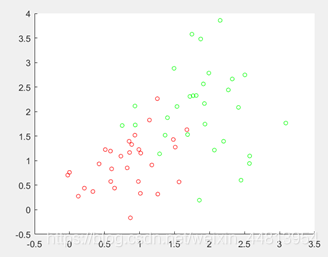
为了进行此实验,本人特地制作了一个训练集和一个测试集,这些测试集的参数如下:
- 红点
- N(1,05)
- N(1,05)
- 绿点
- N(2,0.5)
- N(2,1)
测试集具体形状如图所示:(不是训练集)
当然是用matlab生成的
如果我们采用LDA算法:
即使用python中的sklearn包LinearDiscriminantAnalysis
算法如下
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix,precision_score,accuracy_score,recall_score,f1_score
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
data=pd.read_csv("train.csv")
y_train=data['type'].tolist()
x_train=np.mat([data['x'].tolist(),data['y'].tolist()]).T
data2=pd.read_csv("new.csv")
y_test=data2['type'].tolist()
x_test=np.mat([data2['x'].tolist(),data2['y'].tolist()]).T
clf=LinearDiscriminantAnalysis()
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
con=confusion_matrix(y_test, y_pred)
print(con)
print(accuracy_score(y_test, y_pred),
precision_score(y_test, y_pred),
recall_score(y_test,y_pred),f1_score(y_test, y_pred))
for i in range(0,len(y_test)):
if y_pred[i]!=y_test[i]:
if y_test[i]==1:
plt.scatter(x_test[i,0],x_test[i,1], marker = '+', color = 'green', s = 40)#wrong1
if y_test[i]==0:
plt.scatter(x_test[i,0],x_test[i,1],marker = 'x', color = 'cyan', s = 40)#wrong0
else:
if y_test 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









