







 本文是一篇适合初学者的Python爬虫教程,讲解如何使用requests和BeautifulSoup库抓取网页内容,包括调用库、获取单一及多个网址的内容、反爬策略、异常处理和数据保存。
本文是一篇适合初学者的Python爬虫教程,讲解如何使用requests和BeautifulSoup库抓取网页内容,包括调用库、获取单一及多个网址的内容、反爬策略、异常处理和数据保存。
作者:vinyyu
声明:版权所有,转载请注明出处,谢谢。
1 调入需要使用的库
time库用于每次获取页面的时间间隔;pandas库用于DataFrame的数据格式存储;requests用于爬虫获取页面Html信息;BeautifulSoup用于去掉网页格式提取相关信息;lxml用于操作excel文件。
BeautifulSoup 目前已经被移植到 bs4 库中,也就是说在导入 BeautifulSoup 时需要先安装的是 bs4 库。
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup
import lxml2 用requests库获得已知网址的内容
网页请求的过程分为两个环节:
- Request (请求):每一个展示在用户面前的网页都必须经过这一步,也就是向服务器发送访问请求。
- Response(响应):服务器在接收到用户的请求后,会验证请求的有效性,然后向用户(客户端)发送响应的内容,客户端接收服务器响应的内容,将内容展示出来,就是我们所熟悉的网页请求,如下图所示。

对于网页请求的方式,也分为两种:
- GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
- POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息。
2.1 用requests.get()获得页面内容
例如,需要获得网易体育的页面内容,编写最简单代码:
url='http://sports.163.com'
html = requests.get(url)
print(html.text)获得结果如下:

可以看到,这里获得的是这个url的整个网页内容。然后我们需要通过所需内容的选择器(selector)和BeautifulSoup解析获得该网页中我们需要的部分内容。
2.2 获得页面中所需内容的选择器(selector)
*本文默认读者已知网页结构。网页一般由三部分组成,分别是 HTML(超文本标记语言)、CSS(层叠样式表)和JScript(活动脚本语言)。
推荐用Chrome浏览器打开网页。点击右上角“自定及管理”按钮,选择“更多工具”菜单,选择“开发人员工具”子菜单,打开网页开发平台。然后在一个网页的所需信息上,右键点击鼠标,弹出浮动菜单选择“检查”。在开发平台上选中的所需信息位置上,右键点击鼠标,弹出浮动菜单选择“Copy”,然后选择“copy selector”,复制所需页面的选择器。整个操作过程如下所示:
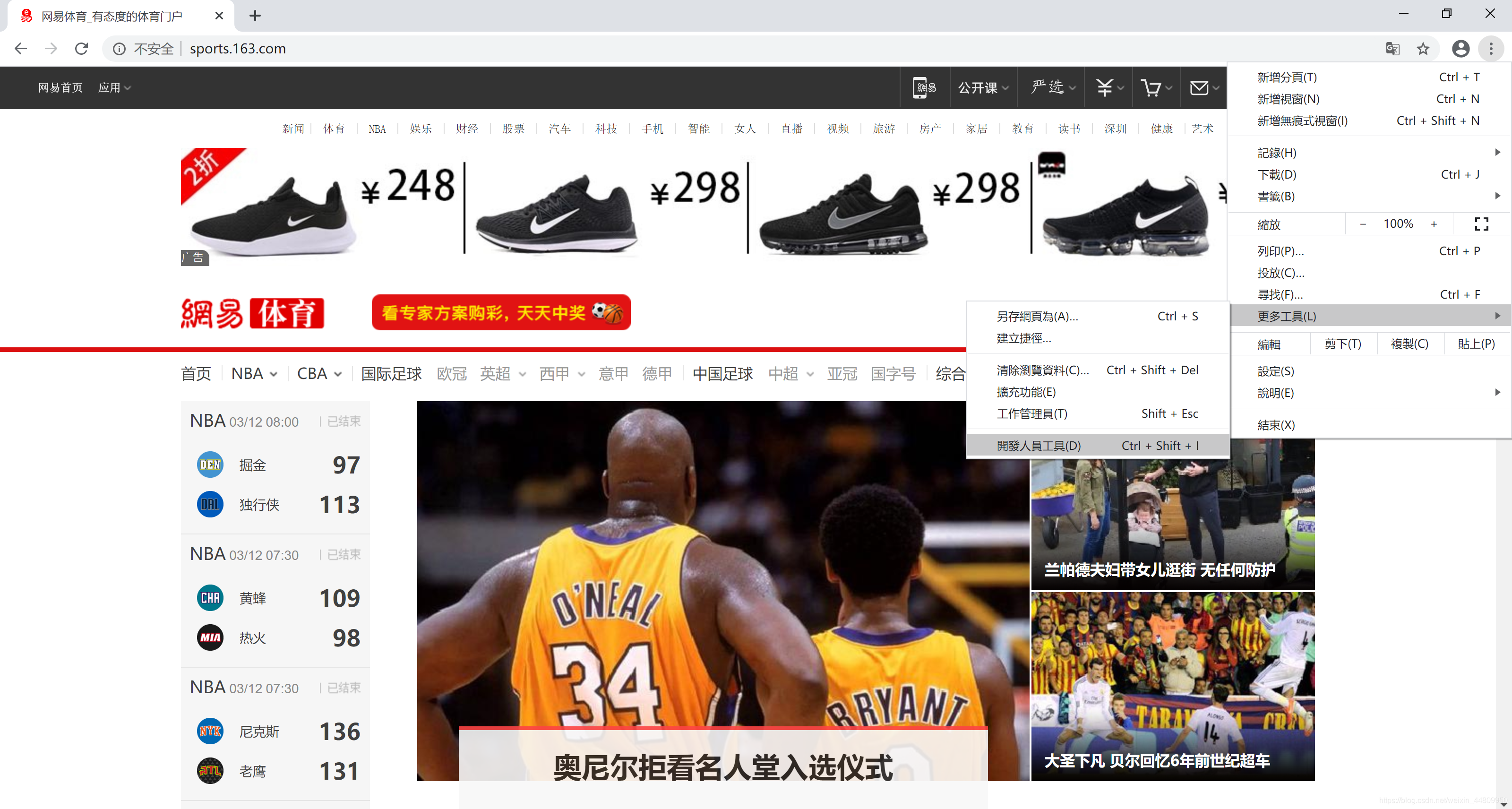
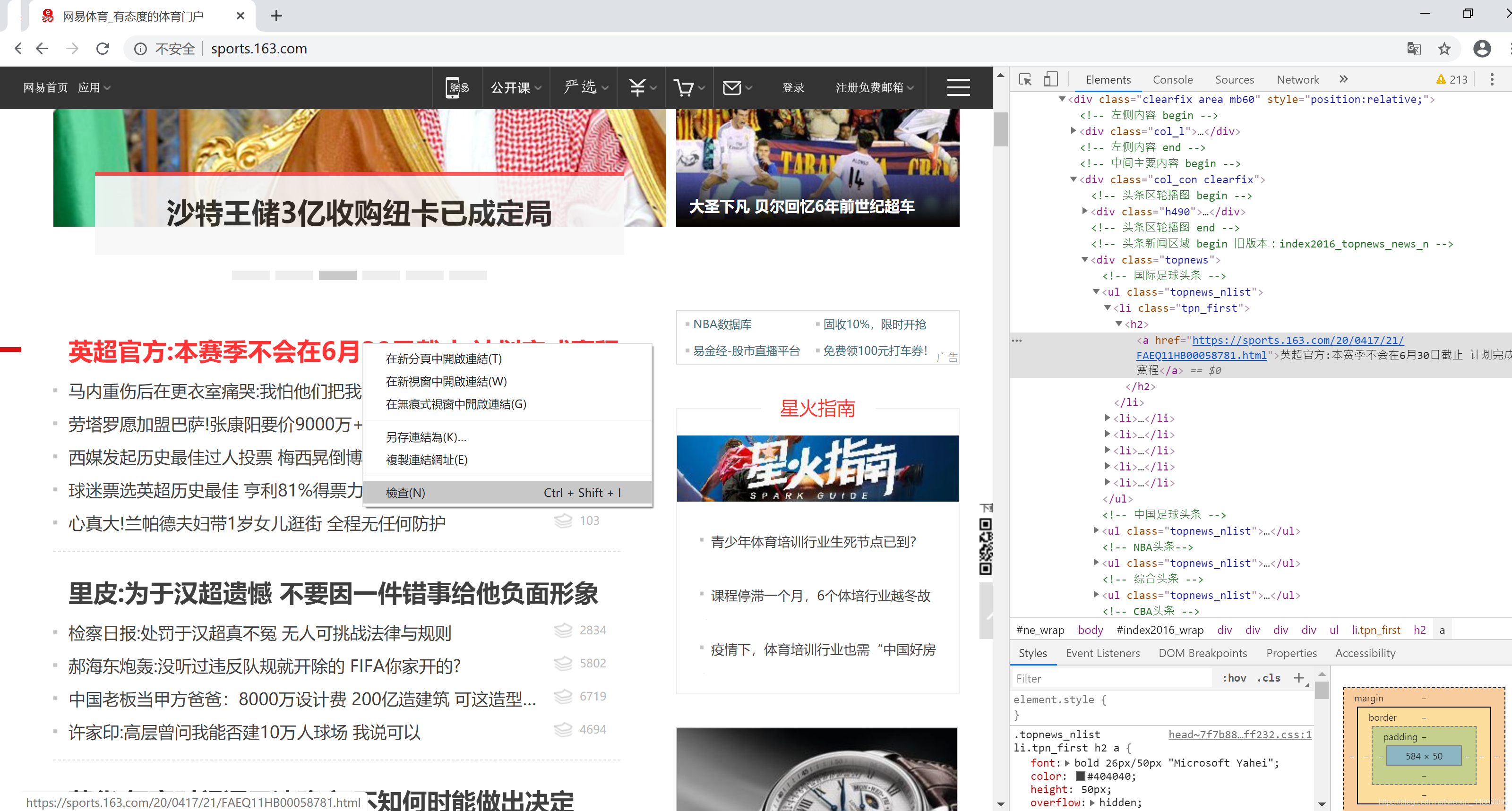
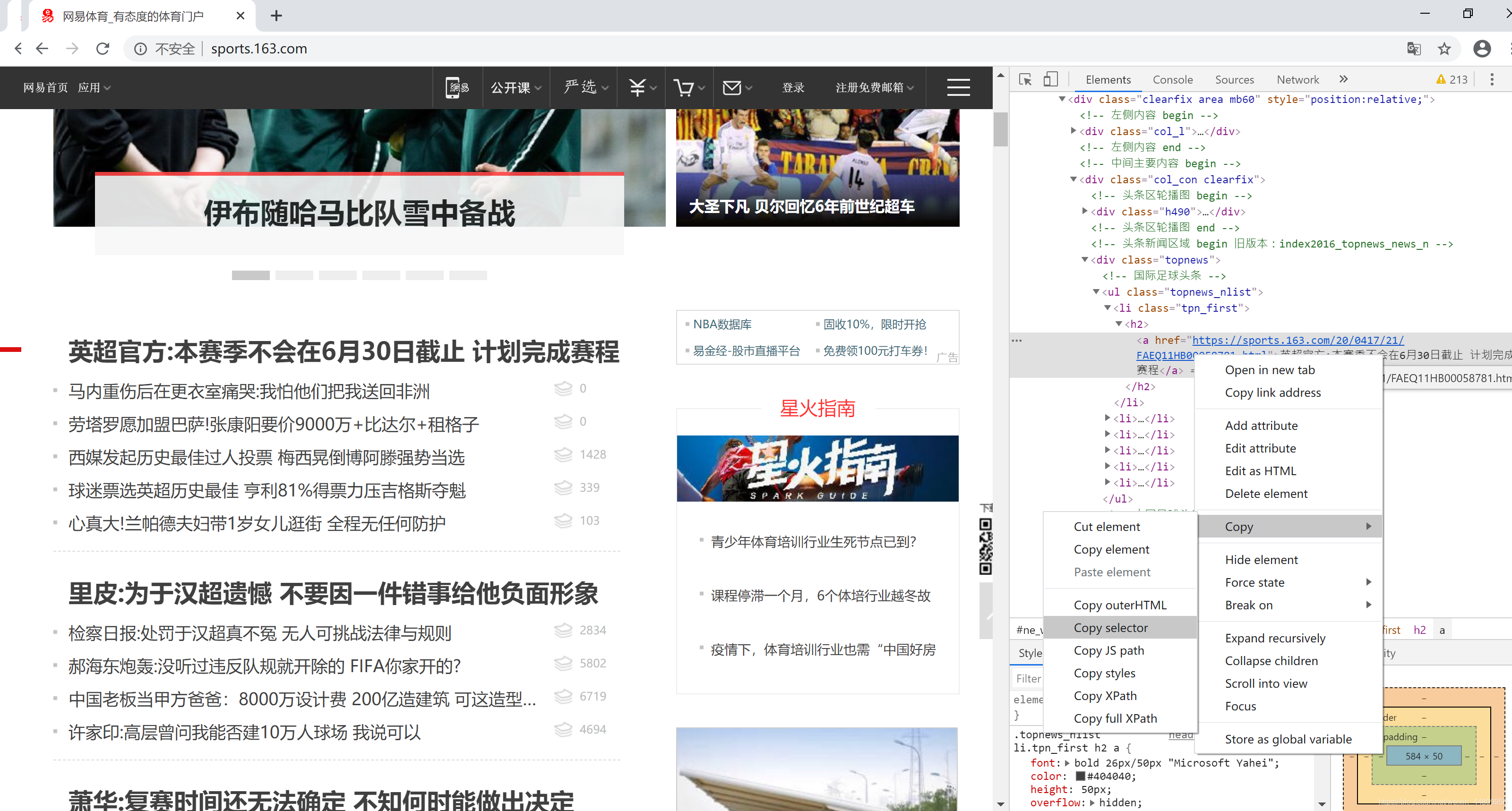
2.3 解析网页并获得选择器中的文本内容
下面代码第一句是用BeautifulSoup解析在2.1中通过requests.get()获得的html.txt。第二句是用BeautifulSoup的select()函数,参数是2.2中获得的选择器(selector),提取网页中我们需要的内容放到data变量中。for循环用于读取data中的内容并显示结果。
要明确BeautifulSoup的select()函数获得的data数据格式。提取的数据包含标题和链接,标题在<a>标签中,提取标签的正文用get_text() 方法。链接在<a>标签的 href 属性中,提取标签中的 href 属性用 get() 方法,在括号中指定要提取的属性数据,即 get(‘href’)。
soup=BeautifulSoup(html.text,'lxml')
data=soup.select('#index2016_wrap > div.index2016_content > div.clearfix.area.mb60 > div.col_con.clearfix > div.topnews > ul:nth-child(1) > li.tpn_first > h2 > a')
for item in data:
result={
'title':item.get_text(),'link':item.get('href')}
print(result)结果显示为:
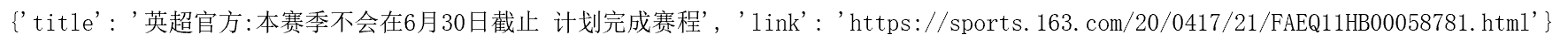 如果我们需要获取所有的头条新闻,因此将 ul:nth-child(1)…中冒号
如果我们需要获取所有的头条新闻,因此将 ul:nth-child(1)…中冒号
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









