




 本文提出了一种新的车道检测模型,该模型采用实例分割方法,能够处理任意数量的车道和车道变化,解决了传统方法中车道数量固定的问题。模型利用多任务学习和特征金字塔架构,实现了实时性能和高精度检测。实验结果在TuSimple、CULane和BDD100K数据集上验证了模型的有效性。
本文提出了一种新的车道检测模型,该模型采用实例分割方法,能够处理任意数量的车道和车道变化,解决了传统方法中车道数量固定的问题。模型利用多任务学习和特征金字塔架构,实现了实时性能和高精度检测。实验结果在TuSimple、CULane和BDD100K数据集上验证了模型的有效性。
Agnostic Lane Detection
翻译
Abstract
车道检测既重要又具有挑战性自动驾驶任务受很多因素的影响因素,例如光线条件,其他因素造成的遮挡车辆,道路上不相关的标记和固有车道的长而细的特性。传统方法通常将车道检测视为语义分割任务,该任务将类别标签分配给图像的每个像素。 这种表述在很大程度上取决于以下假设:
车道数量是预先定义和固定的,不会发生车道变化,这并不总是成立。 为了使车道检测模型适用于任意数量的车道和车道变化场景,我们采用实例分割方法,该方法首先区分车道和背景,然后将每个车道像素分类为每个车道实例。 此外,多任务学习范式是用来更好地利用结构信息,而特征金字塔架构则用于检测极细的车道。 三种流行的车道检测基准,TuSimple,CULane和BDD100K,用于验证我们提出的算法的有效性。
I. INTRODUCTION
II. RELATED WORK
车道检测通常通过使用专门的手工制作功能来获得车道路段。将这些段进一步分组以获得最终结果[2],[4]。这些方法很直观,但是有很多缺点,例如,要求复杂特征选择过程,缺乏鲁棒性,仅适用于相对简单的驾驶场景。最近,有人提出了深度学习方法[8],[11],[5],[3],以简化手工特征的选择并极大地改善模型的泛化能力。这些方法通常采用密集的预测公式,即将车道检测视为语义分割任务,其中图像中的每个像素都分配有标签以指示其是否属于车道。例如,Pan等[11]提出了SCNN,它将空间线索与CNN结合在一起,以生成多通道概率图,其中通道数等于通道数。但是,这些方法只能处理以下情况:车道的数量是预先定义和固定的,它们当车辆改变车道时通常会失败。另一个缺点是这些方法无法实现实时性能,从而阻碍了它们的使用在现实世界。为了克服这些缺点,我们遵循[10]和将模型车道检测作为实例细分任务。更具体地,车道检测任务分为两个子任务。 第一个子任务是生成一个二进制文件分割图,区分车道和背景。 第二个子任务是对每个车道进行分类像素进入车道实例。 轻量级网络,即ENet [12]被用作我们实现实时的骨干性能。 此外,利用结构和上下文信息,我们采用多任务学习可驾驶区域检测和车道点的范例回归被合并到原始车道检测模型中。 此外,功能金字塔架构用于检测极细的车道。
III. METHODOLOGY
在本节中,我们将给出详细说明,我们的框架如图1所示。
我们的模型是主要由五部分组成,即二进制分割分支(B),可驾驶区域检测分(D),车道点回归分支(P),车道像素嵌入分支(E)和聚类分支(C)。 前四个分支的编码器和解码器相同,但仅共享编码器。
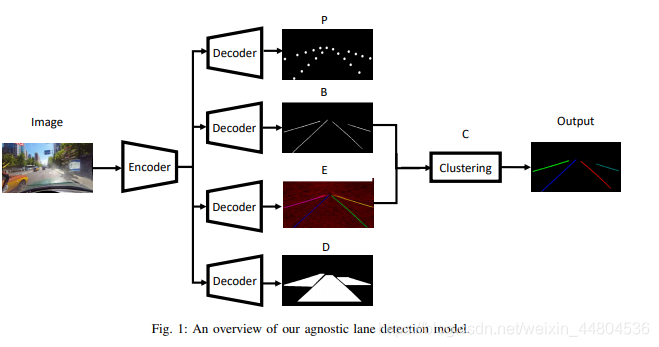
A.二进制分割分支
二进制分割分支的目的是生成一个二进制分割图,以指示原始图像中的每个像素是否属于泳道。 由于三个数据集的真实车道标签均为车道点,因此我们通过以下方式生成最终目标:将车道点连接成线(请参见图2中的最终目标)。 我们使用标准的交叉熵损失来训练该分支。 此外,为了解决车道像素和背景像素的类不平衡,将背景损失乘以0.4。 此外,采用特征金字塔架构[9]来检测极细的车道。
B.可驾驶区域检测
可驾驶区域检测分支的目标是输出分段图,指示该图的哪一部分道路是可驾驶的(我们合并了原始替代区域进入可驾驶区域以提供更密集的目标)。 采用标准交叉熵损失来训练该分支。该分支旨在利用可驾驶区域的边界通过提供精简二进制分割结果更多结构信息。
C.车道点回归
该分支机构的目标是退还职位每个车道点数 由于泳道点相对稀疏,我们使用11 x 11的内核对原始轨迹进行平滑处理车道点地图以获取该分支的最终目标。L2损失用于训练该分支。 该分支旨在完善二进制分段分支的输出。
D.车道像素嵌入
该分支的输入是提取的车道像素来自二进制分割图。 我们对待每条车道
在图像中作为实例。 该分支的目标是将车道像素分类为不同的车道实例。
核心思想是属于同一像素车道实例应该彼此靠近,而那些属于不同车道实例的地方应该远离彼此。 我们利用以下等式来计算
聚类损失[10]:
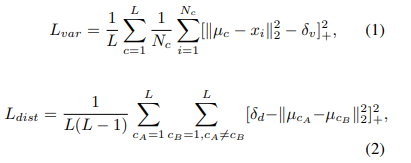
其中L表示车道数量,xi是个嵌入像素时,Nc是其中的元素数
簇c,μc是簇c和[x] + = max(0,x)**(不清楚这个式子的意思)**平均值。 第一损失项Lvar用于使属于同一车道实例的像素之间的距离保持小于2δv。 第二损失项Ldist用于使不同车道簇之间的距离保持比δd更远。
E.聚类
聚类分支用于处理输出车道像素嵌入分支。 在实验中我们设置δd>6δv。 因此,给出车道的输出像素嵌入分支,我们可以随机选择一个像素
作为起点,然后标记所有像素与所选像素的距离小于2δv同一实例。 继续此过程,直到所有车道像素分配给特定的车道实例。 注意,该分支没有任何可学习的参数。
F.训练
目前,我们采用两阶段的培训策略。 在第一阶段,我们固定分支E的参数和训练分支P,B和D。在第二阶段,我们固定分支P,B和D以及训练分支E的参数。
IV. EXPERIMENTS
在本节中,我们将首先简要介绍到用于评估的三个数据集。 然后,初步
给出了实验结果。
A. Dataset
B. Evaluation Criterion
C. Lane detection model
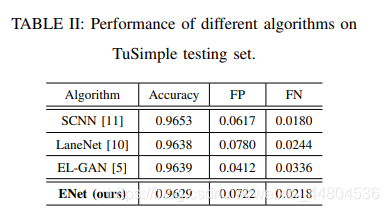
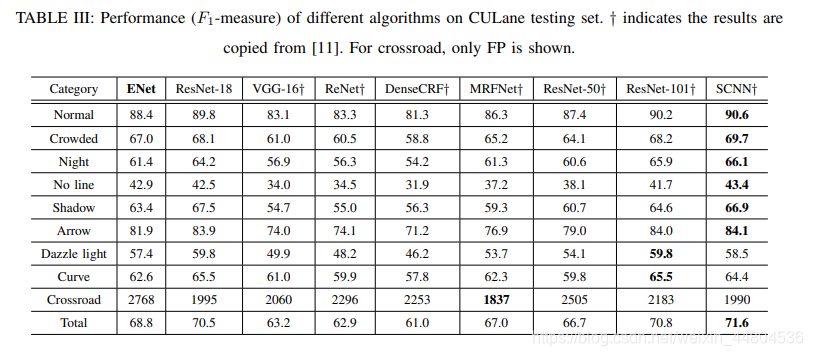
D. Preliminary results on TuSimple and CULane
 在这里插入图片描述
在这里插入图片描述
 在这项研究中,我们首先指出其价值和主要车道检测任务的挑战。 然后,优势以及传统和深度学习方法的缺点。 为了克服以前方法的缺点,我们不可知论的道提出了一种利用多任务的检测模型学习范式和要素金字塔架构
在这项研究中,我们首先指出其价值和主要车道检测任务的挑战。 然后,优势以及传统和深度学习方法的缺点。 为了克服以前方法的缺点,我们不可知论的道提出了一种利用多任务的检测模型学习范式和要素金字塔架构
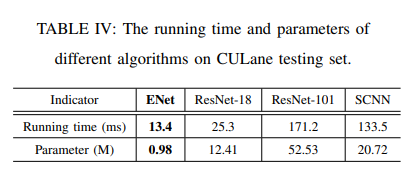
利用结构和上下文信息。 我们用三个流行的基准,即TuSimple,CULane和BDD100K,以验证提议的有效性算法。 初步实验结果表明我们的模型在性能上优于以前的方法运行时间效率和参数数量。 但是,这仍然是一个正在进行的项目,良好的性能将带来更多的性能提升部署不同的组件更合理培训策略。
这篇文章,在准确率低于SCNN,胜在时间效率和参数量少于SCNN,在第1个图中,TuSimple的对比上,没有体现出ENet的优势,不知道这里作者要说明什么???

















 2734
2734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









