






 本文详细解析了一个网站在提交验证码时所使用的后缀生成算法。通过抓包及跟栈分析,逐步揭示了从原始数据到最终后缀字符串的转换过程。涉及数组操作、位运算等关键技术。
本文详细解析了一个网站在提交验证码时所使用的后缀生成算法。通过抓包及跟栈分析,逐步揭示了从原始数据到最终后缀字符串的转换过程。涉及数组操作、位运算等关键技术。
看这篇文章的前提是:读者已经成功请求到了200页面
一、抓包分析
这个站在提交验证码的时候会将识别的内容加密放到后缀中,所以分析后缀也是无奈之举。

二、跟栈分析
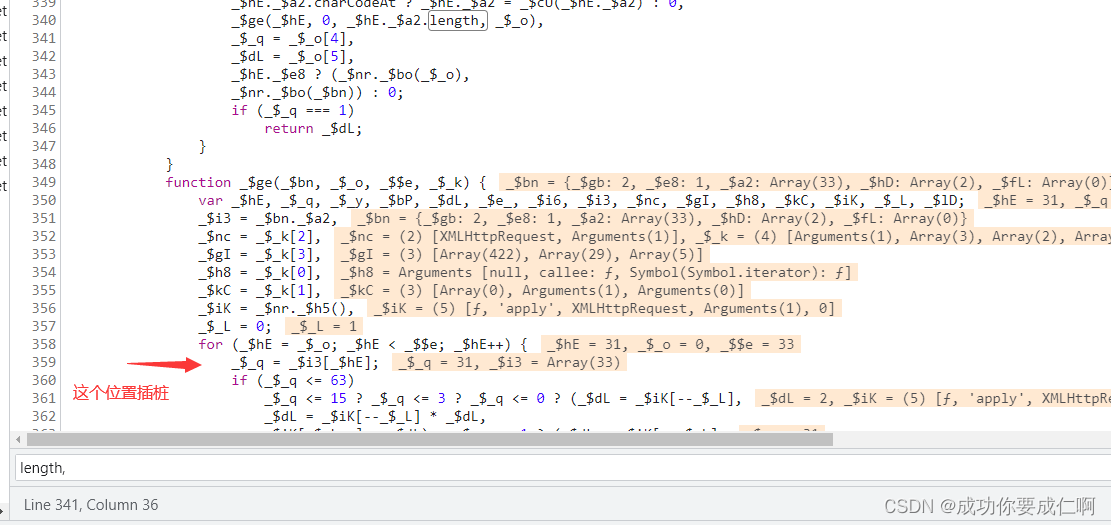
下个xhr断点,提交验证码,找到这个地方

思路:open和send都经过魔改了,所以在这两个地方下断点。再提交验证码,断到open处的时候,进到vm代码里插桩,当在send处断下来时,后缀已生成,这部分的日志就是我们需要分析的。
插桩位置:进到vm层,全局搜length,
找到结构跟这个差不多的就对了,插桩内容JSON.stringify(_$iK)
三、算法分析(从后往前推)
1、首先是一个大数组(arr_final)经过一个函数转为字符串(后缀)
function get_suffix(arr_final){
_$hv = ['q', 'r', 'c', 'k', 'l', 'm', 'D', 'o', 'E', 'x', 't', 'h', 'W', 'J', 'i', 'H', 'A', 'p', '1', 's', 'V', 'Y', 'K', 'U', '3', 'R', 'F', 'M', 'Q', 'w', '8', 'I', 'G', 'f', 'P', 'O', '9', '2', 'b', 'v', 'L', 'N', 'j', '.', '7', 'z', 'X', 'B', 'a', 'S', 'n', 'u', '0', 'T', 'C', '6', 'g', 'y', '_', '4', 'Z', 'e', '5', 'd', '{', '}', '|', '~', ' ', '!', '#', '$', '%', '(', ')', '*', '+', ',', '-', ';', '=', '?', '@', '[', ']', '^'];
_$eZ = 0;
_$aj = 0;
_$av = _$ch['length'];
_$k3 = new Array(Math["ceil"](_$av * 4 / 3));
_$av = _$ch["length"] - 2;
while (_$eZ < _$av) _$c1 = _$ch[_$eZ++], _$k3[_$aj++] = _$hv[_$c1 >> 2], _$ah = _$ch[_$eZ++], _$k3[_$aj++] = _$hv[(_$c1 & 3) << 4 | _$ah >> 4], _$c1 = _$ch[_$eZ++], _$k3[_$aj++] = _$hv[(_$ah & 15) << 2 | _$c1 >> 6], _$k3[_$aj++] = _$hv[_$c1 & 63];
if (_$eZ < _$ch["length"]) { _$c1 = _$ch[_$eZ];_$k3[_$aj++] = _$hv[_$c1 >> 2];_$ah = _$ch[++_$eZ];_$k3[_$aj++] = _$hv[(_$c1 & 3) << 4 | _$ah >> 4]};
if (_$ah !== undefined) { _$k3[_$aj++] = _$hv[(_$ah & 15) << 2];}
return _$k3.join('')
}
2、arr_final = arr_4 + arr_549
//这里的arr_549长度不一定(arr_xxx)
arr_4 = []
_$_f(arr_4, number_549)
arr_final = arr_4.concat(arr_549)
function _$_f(_$mM, _$$a) {
if (typeof _$$a !== _$lb[4]) {
_$$a = 0;
}
_$mM[_$lb[10]](_$$a >> _$mJ[31] & _$mJ[25]);
_$mM[_$lb[10]](_$$a >> _$mJ[13] & _$mJ[25]);
_$mM[_$lb[10]](_$$a >> _$mJ[3] & _$mJ[25]);
_$mM[_$lb[10]](_$$a & _$mJ[25]);
}
3、arr_549 = arr35 + arr512
//这里的arr_512长度不一定(arr_xxx)
//arr_35 = [1,0,32] + 35位数组里面第二位
arr_549 = _$b7(arr_35, arr_512);
number_549 = _$bo(arr_549) ;
function _$b7(_$mM, _$$a) {
_$eW(_$mM, _$$a[_$lb[50]]);
_$fi(_$mM, _$$a);
return _$mM
}
function _$bo(_$ch) {
var _$hv,_$k3,_$eZ,_$aj;
if (typeof _$ch === "string") {_$ch = _$g$(_$ch);}
_$hv = _$cM();
_$k3 = -1;
_$eZ = _$ch['length'];
for (_$aj = 0; _$aj < _$eZ;) {
_$k3 = _$k3 >>> _$mJ[3] ^ _$hv[(_$k3 ^ _$ch[_$aj++]) & _$mJ[25]];
}
return (_$k3 ^ -1) >>> 0;
}
4、arr_512 = arr_498 + arr_21
//这里的arr_498长度不一定(arr_xxx)
//arr_21和生成cookie中的arr_20_to_21是一致的
arr_512 = _$kW(arr_498, arr_21);
function _$kW(_$mM, _$$a) {
var _$ei;
if (typeof _$mM === _$lb[32]) {
_$mM = _$cO(_$mM);
}
_$ei = _$$O(_$$a);
return _$ei._$ee(_$mM, false);
}
5、arr_498 = arr_cookie + arr_259
//这里的arr_259长度不一定(arr_xxx)
//arr_cookie就是生成cookie的数组
arr_498 = _$b7(arr_cookie,arr_259);
function _$b7(_$mM, _$$a) {
_$eW(_$mM, _$$a[_$lb[50]]);
_$fi(_$mM, _$$a);
return _$mM
}
6、arr_259由来
//获取关于后缀的259位数组
function get_arr_259(){
_$mM = [];
_$_f(_$mM,65592)
_$dE(_$mM, 1);
_$kk(_$mM, _$dO(_$mJ[43]));//35位数组的第10位运算得来
_$_f(_$mM, _$_9[22]); //35位数组的第19位运算得来
_$li(_$mM, _$hc); //flag_10_longnum
_$_f(_$mM, _$iC); //arr_to_longnum(url1.toUpperCase())
_$hh(_$mM, _$kd); //_$kd为请求的url
return _$mM
}
至此 关于后缀的所有算法都已分析完毕
三、请求验证

最后最后,真心谢谢十一姐的指导与帮助

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









