






语言模型能解决自然语言中的图问题吗?
摘要
大型语言模型(LLM)越来越多地被用于具有隐式图形结构的各种任务,例如机器人中路径规划、多跳问题回答或知识探索、结构化常识推理等。虽然LLMS已经在这些具有结构含义的任务上取得了进展,但LLMS是否能够明确地处理graph和结构的文本描述,将它们映射到扎根的概念空间,以及执行结构化操作,仍然缺乏探索。为此,我们提出了NLGRAP(Natural Language Graph),这是一个用自然语言设计的基于图的问题解决的综合基准。NLGraph包含29,370个问题,涵盖8个复杂的图推理任务,从简单的任务(如连通性和最短路径)到复杂的问题(如最大流和模拟图神经网络)。我们在NLGraph基准测试中用不同的提示方法对LLMS(GPT-3/4)进行了评估,发现1)语言模型确实展示了初步的图形推理能力,2)高级提示和上下文学习的好处在更复杂的图问题上减弱,而3)LLM在面对图和问题设置中的虚假关联时也(不)令人惊讶地脆弱。然后,我们提出了构建图提示和算法提示这两种基于指令的方法来增强LLMS在解决自然语言图问题方面的能力。
Introduction
LLM最初是为文本数据设计的,现在越来越多地用于语言处理以外的任务。在机器人学和规划中,LLM被用来指导代理通过结构化环境。在心理理论推理中,LLM需要维护和更新反映不同角色信念的局部和全局图表。在结构化常识推理中,预计LLM将生成基于图的行动计划,以实现具有多样化先决条件的目标。在多跳问题回答中,LLM隐含地在巨大的实体和概念网络之间找到连接和路径。总之,这些工作表明,LLMS在取得初步成功的同时,也被广泛应用于具有隐式图结构的任务。然而,一个潜在但关键的问题仍然没有得到充分的探讨:LLM能否用图表进行推理?更具体地说,LLM能够将图和结构的文本描述映射到基础概念空间并求解图算法问题明确与自然语言?
为此,我们提出了自然语言图(NLGraph)基准测试,这是一个针对语言模型和自然语言设计的图形和结构化推理的综合测试平台。NLGraph总共包含29370个问题,涵盖了8个复杂度不同的图推理任务,从直观上简单的任务(如连通性,循环和最短路径)到更复杂的问题(如拓扑排序,最大流,二分图匹配,汉密尔顿路径和模拟图神经网络)。我们通过生成的图大小、网络稀疏度、数值范围等来控制问题难度,在每个不同的图推理任务中呈现容易、中等和困难的子集,以实现细粒度分析。除了使用精确匹配精度作为标准度量外,我们还为各种图推理任务设计了几种部分信用解决方案。
通过NLGraph基准测试,我们评估了各种大型语言模型可以执行基于图形的推理以及不同的提示技术提高大型语言模型的图推理能力。在NLGraph基准测试上进行的大量实验表明:
1. LLM具备初步的图形推理能力。具体来说,大型语言模型在简单的图形推理任务(如连接性、循环和最短路径)上表现出令人印象深刻的性能水平,比随机基线高出37.33%至57.82%。通过思维链提示,LLM可以生成合理准确的中间步骤,同时进一步提高任务性能。
2.高级提示方法的好处会随着问题的复杂而减弱。一方面,思维链(chain-of-thought),最小到最大(least-to-most)和自我一致性(self-consistency)成功地提高了LLM在循环和最短路径等简单任务上的图推理能力,但在拓扑排序和汉密尔顿路径等复杂图推理问题上,这些方法大多无效,甚至在某些情况下适得其反。
3.从例子中学习不会发生在复杂的图推理问题上。虽然在上下文学习被广泛认为是教学LLM从例子中学习,它对更高级的图推理任务的好处还不清楚:few-shot上下文学习无法在多个任务中改善zero-shot提示,而增加样本的数量甚至可能对汉密尔顿路径等任务产生反作用。
4.LLM对于问题设置中的虚假相关性是(不)令人惊讶的脆弱。我们发现,在连接任务中的两种特殊情况下(链和团),LLM的性能比一般数据集差得多,在各种设置中性能下降超过40%。这表明大型语言模型隐含地依赖于某些虚假的相关性(例如,使用节点提及频率来确定连接性),无法在基于图的上下文中执行鲁棒的结构化推理。
为了提高大型语言模型作为更好的图推理机,我们提出了两个基于提示的方法,以更好地引出大型语言模型的图推理能力。Builda-Graph提示鼓励LLM在通过一句话指令解决特定问题之前将图形和结构的文本描述映射到grounded conceptual spaces,而语法提示指示LLM在从上下文范例中学习之前重新审视给定任务的算法步骤。实验表明,构建图和算法提示成功地使LLM能够更好地解决图推理问题,在多个任务中获得3.07%至16.85%的性能提升,而最复杂的图推理问题仍然是一个开放的研究问题。
2 The NLGraph Benchmark
为了检验语言模型是否能够用图和结构进行推理,我们策划并提出了自然语言图(NLGraph)基准。具体来说,我们首先使用一个随机图生成器来生成图和结构,同时控制网络大小,图稀疏度等。然后,我们采用生成的图为基础,综合生成八个基于图的推理任务的问题,不同的算法难度。控制八项任务中的每一项任务的问题难度,从而在每个图推理任务中产生简单、中等和困难的子集,以实现难度缩放和细粒度分析。
2.1 Random Graph Generator
我们首先使用一个通用的随机图生成器来生成基图,同时使用节点数和图密度来控制复杂度。形式上,为了生成图G = {V,E},其中V和E表示节点和边的集合,我们指定节点的数目n,因此V = {v1,v2,...,v}。..,vn},以及|V| = n.然后我们指定边概率p,使得所有的边都根据P(eij ∈ E)= p生成,其中eij是从vi到vj的边。根据任务,边可以是有向的或无向的。我们使用变化的n和p值来控制随机图结构的复杂性。在这些生成的基础图的基础上,我们还采用了为每个任务量身定制的图编辑和其他难度控制因素。
- Zero-Shot-CoT 不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。
- Few-Shot-Cot 则在示例中详细描述了“解题步骤”,让模型照猫画虎得到推理能力。
1. Prompt 模式
Prompt 模式主要研究“向大模型输入怎样的 Prompt 可以使得大模型获得更好的推理能力”,关于 Prompt 模式的研究也可以分为两类,分别是指令生成与范例生成。
对于指令生成问题,又可以分为手动指令生成与自动指令生成,
手动指令生成模式:① “Let’s think step by step”;② Plan-and-Solve的主要思想在于让模型制定一个将任务分为更小子任务的计划,再让模型一步一步执行计划、解决问题,其 Prompt 为“Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step”。
自动指令生成:① 自动 Prompt 工程(APE);② 提示优化(OPRO);APE 与 OPRO 的核心思想都在于设计了一套机制让大模型通过观察各个候选的 Prompt 的实际任务中的表现,通过最大化表现得分来自动选择最优的 Prompt 。
范例生成也可以分为手动范例生成与自动范例生成;
手动范例生成方法:① Few-Shot-CoT;② ActivePrompt一种让大模型使用手动生成的范例多次回答问题,再从其中依据如熵、方差等的不确定性度量选择“最不确定”的问题,通过手动注释来加强范例生成的 ActivePrompt 方法,成为了一种介于手动范例生成与自动范例生成之间的范例生成方法。
自动范例:Auto-CoT ,Auto-CoT 分为两个阶段:(1)问题聚类,对任务数据集进行聚类(2)示例采样:从每个聚类中心中选择一个代表性问题使用 Zero-Shot-CoT 生成思维链作为示例。
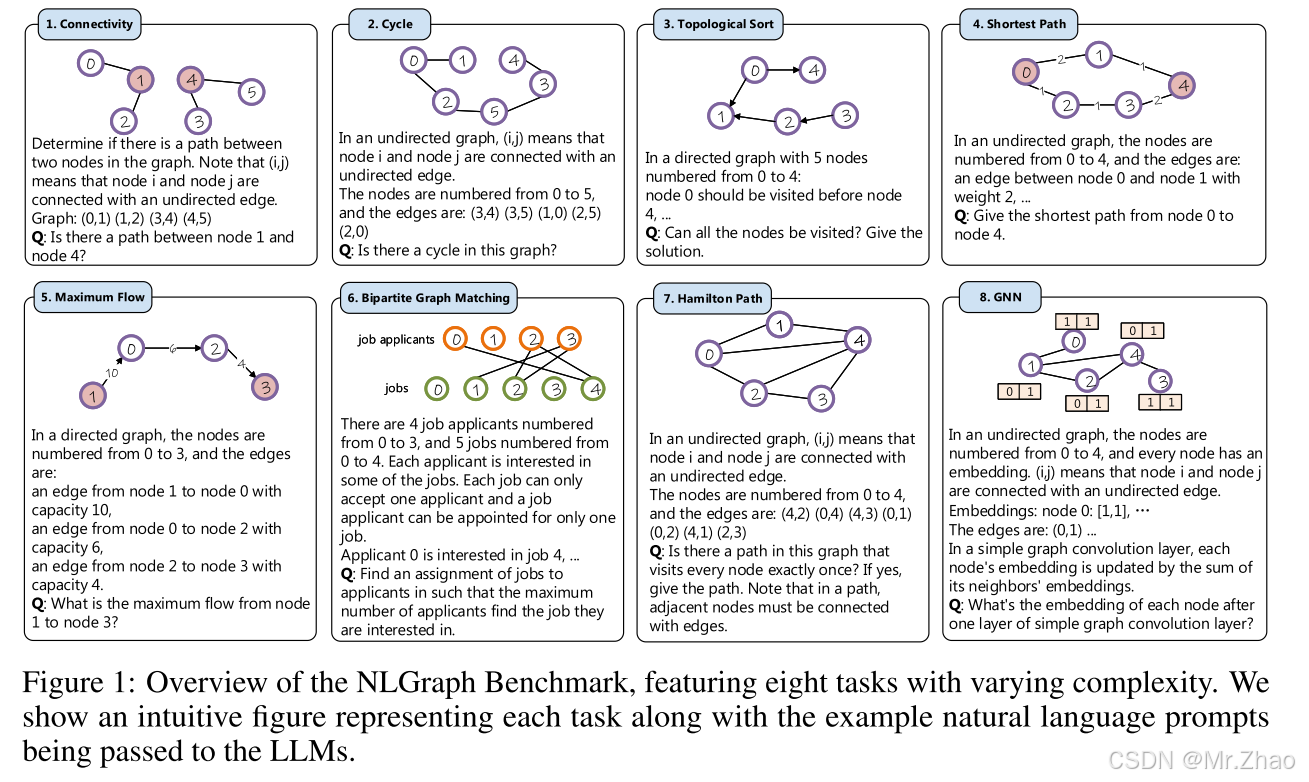
2.2 Benchmark Statistics
使用上述方法,我们生成了NLGraph基准测试,标准版本中有5902个问题,扩展版本中有29370个问题。直观上更容易的任务,包括连通性,循环和拓扑排序问题,根据图的大小,稀疏性以及其他难度控制因素进一步分为容易,中等和困难的子集。更高级的算法任务,包括最短路径,最大流,二分图匹配,汉密尔顿路径,和图神经网络问题,分为容易和困难的子集。我们在表1中提供了基准统计数据。准确性(真/假答案是否正确,建议的解决方案是否有效)是默认的评估指标,而任务4、任务5和任务8具有上述额外的部分信用指标。我们设想NLGraph作为一个全面的测试平台,图和结构化推理的大型语言模型。
4 Results
4.1 LLMs Have (Preliminary) Graph Reasoning Abilities
我们首先发现,在直观简单的图推理任务,大型语言模型取得了令人印象深刻的性能,并表现出初步的图推理能力。如表2所示,LLM在连通性、循环和最短路径任务上的性能明显优于RANDOM基线,表明LLM没有给出随机答案,并且它们确实具有初步的图形推理能力。在前两个真/假问题的任务中,LLM的绩效比COT或COT+SC提示的随机任务高37.33%~ 57.82%。
4.2 Mixed Results with Advanced Prompting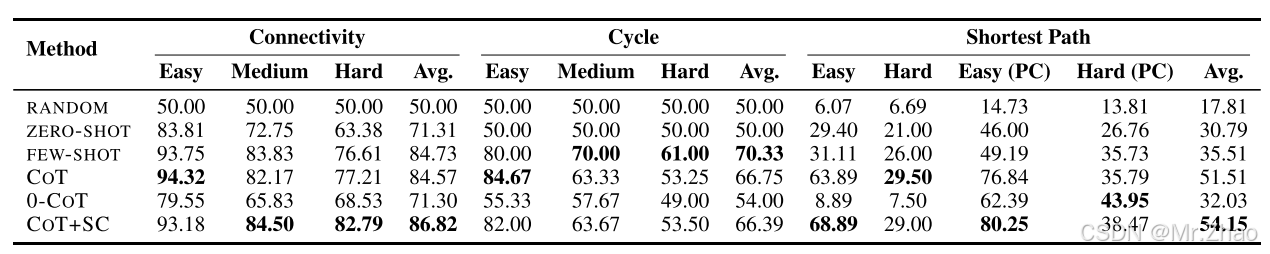
表2显示了advanced prompting技术,例如chain-of-thought和self-consistency成功地提高了简单图推理任务的性能。对于模拟图神经网络的任务(表3),思想链也显著提高了模型性能。然而,这些方法可能无效,甚至在更复杂的图推理任务中适得其反。从拓扑排序和最大流任务的结果(图2)中,我们观察到COT、COT+SC和LTM提示通常不如Few - SHOT提示。我们认为这可能是因为LLM在面对复杂的图形推理任务时无法学习生成中间步骤的正确方法。这使人们对COT、LTM和self-consistency在更高级的图推理问题中的推广性产生了怀疑。
4.3 In-Context Learning Can be Counterproductive
虽然在上下文学习被广泛归因于教学LLM从上下文范例中学习,我们观察到,few-shots上下文学习无法提高LLM在复杂图推理问题上的性能。对于诸如汉密尔顿路径和二分图匹配(图3)之类的任务,zero-shot提示通常优于具有上下文样本的few-shot学习。结果表明,当问题涉及数百个基于图的推理步骤时,LLM无法从上下文范例中学习。在上下文中的样本甚至可能分散大型语言模型的注意力,明显的是,在汉密尔顿路径和二分图匹配上,few-shot学习的性能比zero-shot学习低1.00%到10.48%。
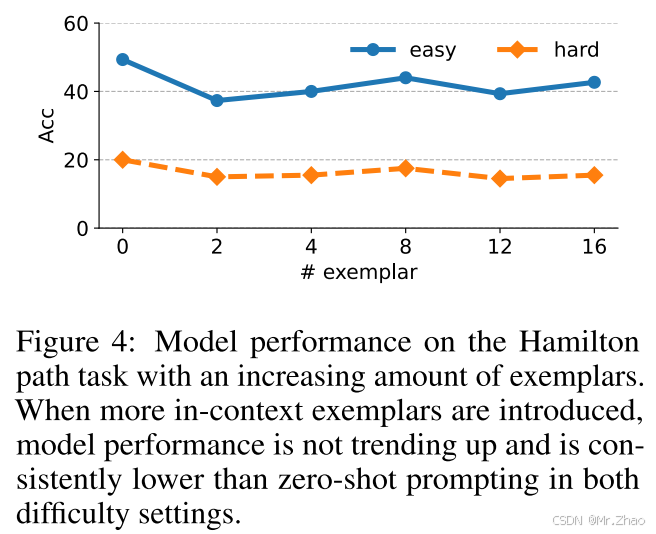
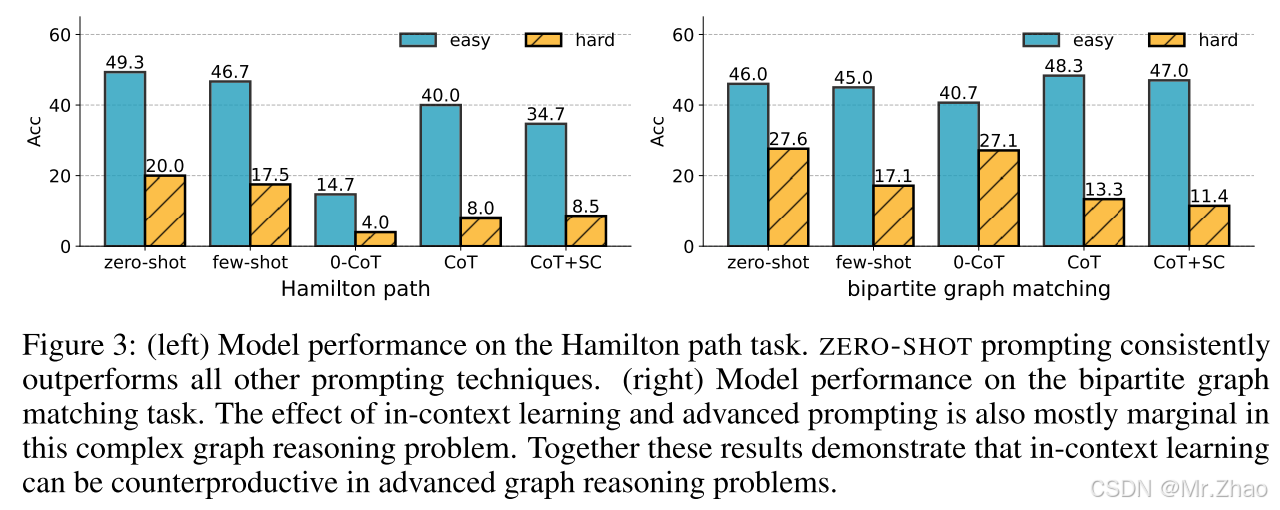
我们进一步研究了汉密尔顿路径任务中样本数量与模型性能之间的相关性。如图4所示,当样本数量增加时,模型性能并没有上升的趋势,并且性能始终低于zero-shot提示。这些结果进一步表明,在复杂的结构化推理中,情境学习可能适得其反。
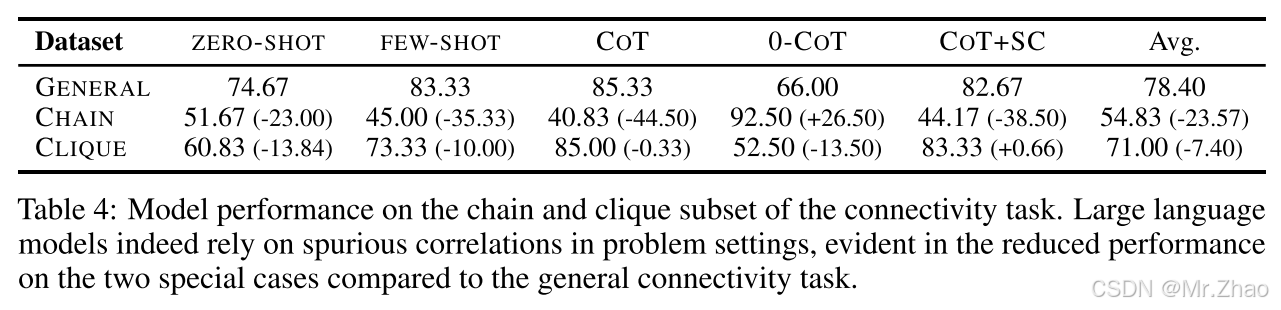
4.4 LLMs are (Un)surprisingly Brittle
虽然大型语言模型在简单的图推理任务中的性能明显优于随机(第4.1节),但我们假设LLM可能能够通过利用某些虚假相关性来获得正确答案。例如,在连通性任务中,由于具有较高度的节点被更频繁地提及,并且它们更有可能被连接,因此LLM可能只是计算节点提及次数,而不是实际查找路径。为此,我们设计了两种特殊情况(链和团)的连接任务,是完全相反的虚假相关。
Conclusion
在这项工作中,我们调查LLM是否能够显式图推理,即,用自然语言解决图算法问题,跨越各种问题类别和提示技术。为此,我们策划了NLGraph基准测试,这是一个自然语言中基于图的推理的综合测试平台,其中包含29,370个问题,涵盖了8个复杂度不同的任务。通过评估LLM和提示方法在NLGraph基准测试中,我们发现1)LLM确实具有初步的图形推理能力,2)高级提示和上下文学习的好处可能会在复杂的推理任务中减少,而3)LLM在问题设置中对虚假相关性很脆弱。然后,我们提出了构建一个图形和mammic验证,两个简单的基于验证的方法,在多个任务中带来显着的性能增益。提高LLM在复杂和细致入微的图形推理任务上的图形推理能力仍然是一个开放的研究问题,我们鼓励未来的工作在我们提出的NLGraph基准上发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









