






1, 解析解的推导
我们现在有了损失函数形式,也明确了目标就是要最小化损失函数,那么接下来问题就是 theta 什么时候可以使得损失函数最小了。
---
最小二乘形式变化个写法
我们先把损失函数变化个形式:
\[ J(\theta) = \frac{1}{2} \sum_{i=1}^{m} \left( h_\theta(x^{(i)}) - y^{(i)} \right)^2 = \frac{1}{2} (X\theta - y)^T (X\theta - y) \]
补充说明:
\[ J(\theta) = \frac{1}{2} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2 \]
\[ = \frac{1}{2} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})(h_\theta(x^{(i)}) - y^{(i)}) \]
这里就等价于一个长度为 \( m \) 向量乘以它自己,说白了就是对应位置相乘相加。
\[
\begin{bmatrix}
a_1 \\
a_2 \\
\vdots \\
a_{n-1} \\
a_n
\end{bmatrix}
\cdot
\begin{bmatrix}
b_1 \\
b_2 \\
\vdots \\
b_{n-1} \\
b_n
\end{bmatrix}
=
a_1 b_1 + a_2 b_2 + \cdots + a_{n-1} b_{n-1} + a_n b_n
\]
用连加号写:
\[ \mathbf{a} \cdot \mathbf{b} = \sum_{i=1}^{n} a_i b_i. \]
### 推导出 \(\theta\) 的解析解形式
给定损失函数 \(J(\theta)\) 为:
\[ J(\theta) = \frac{1}{2} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2 \]
其中,\(h_\theta(x^{(i)}) = \theta^T x^{(i)}\)。
我们可以将上述表达式转换为矩阵形式:
\[ J(\theta) = \frac{1}{2} \sum_{i=1}^{m} (\theta^T x^{(i)} - y^{(i)})^2 \]
进一步展开:
\[ J(\theta) = \frac{1}{2} \sum_{i=1}^{m} (\theta^T x^{(i)} - y^{(i)})(\theta^T x^{(i)} - y^{(i)}) \]
\[ J(\theta) = \frac{1}{2} (X\theta - y)^T (X\theta - y) \]
\[ J(\theta) = \frac{1}{2} ((X\theta)^T - y^T)(X\theta - y) \]
\[ J(\theta) = \frac{1}{2} (\theta^T X^T - y^T)(X\theta - y) \]
\[ J(\theta) = \frac{1}{2} (\theta^T X^T X\theta - \theta^T X^T y - y^T X\theta + y^T y) \]
为了找到使 \(J(\theta)\) 最小化的 \(\theta\),我们需要对 \(\theta\) 求导并令其等于0:
\[ \nabla_\theta J(\theta) = 0 \]
为了方便理解,大家可以把下图的横轴看成是θ轴,纵轴看成是 loss 损失,曲线是 loss function,然后你开着小车去寻找最优解
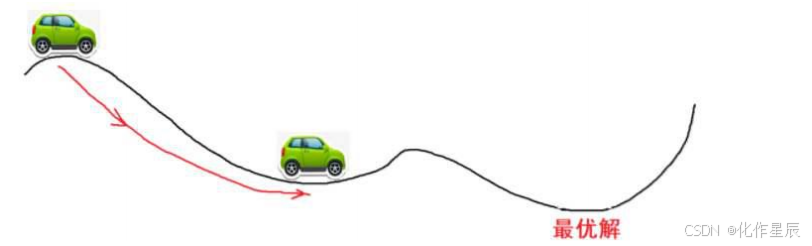
如果我们把最小二乘看成是一个函数曲线,极小值(最优解)一定是个驻点,驻点顾名思义就是可以停驻的点,而图中你可以看出驻点的特点是统统梯度为 0
梯度:函数在某点上的切线的斜率如何求?求函数在某个驻点上的一阶导数即为切线的斜率更近一步,或者反过来说,就是我们是不是可以把函数的一阶导函数形式推导出来
计算梯度:
\[ \nabla_\theta J(\theta) = \frac{1}{2} \nabla_\theta (\theta^T X^T X\theta - \theta^T X^T y - y^T X\theta + y^T y) \]
\[ \nabla_\theta J(\theta) = \frac{1}{2} (2X^T X\theta - X^T y - X^T y) \]
\[ \nabla_\theta J(\theta) = X^T X\theta - X^T y \]
令梯度等于0:
\[ X^T X\theta - X^T y = 0 \]
\[ X^T X\theta = X^T y \]
解得:
\[ \theta = (X^T X)^{-1} X^T y \]
这就是 \(\theta\) 的解析解形式。
2,判定损失函数凸函数
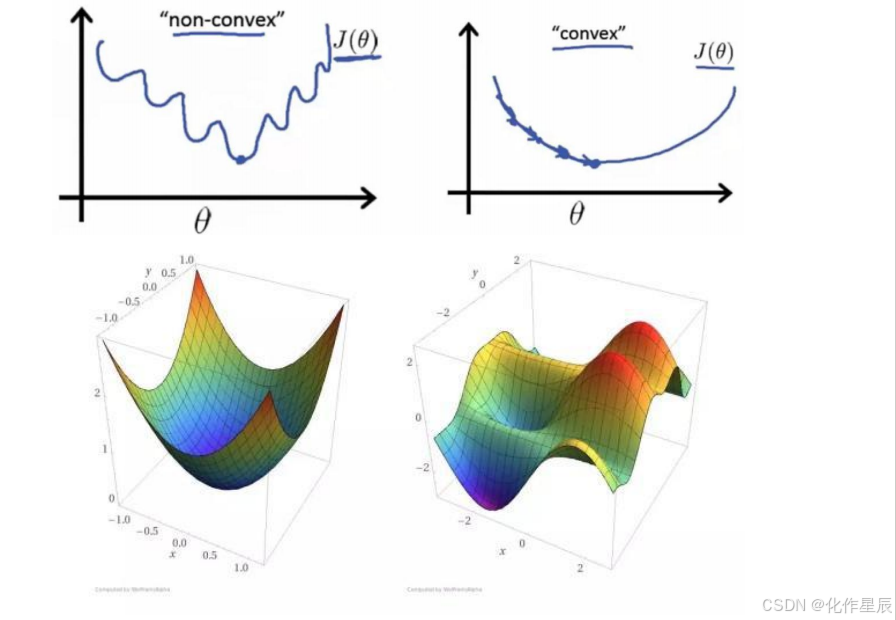
判定凸函数的方式非常多,其中一个方法是看黑塞矩阵是否是半正定的。
黑塞矩阵(hessian matrix)是由目标函数在点 X 处的二阶偏导数组成的对称矩阵对于我们的式子来说就是在导函数的基础上再次对θ来求偏导,说白了不就是 X^TX所谓正定就是 A 的特征值全为正数,那么是正定的。半正定就是 A 的特征值大于等于 0,就是半正定。
这里我们对 J 损失函数求二阶导的黑塞矩阵是 X^TX ,之后得到的一定是半正定的,自己
和自己做点乘嘛!此处不用深入去找数学推导证明这一点,还有就是机器学习中往往损失函数都是凸函数,到深度学习中损失函数往往是非凸函数,即找到的解未必是全局最优,只要模型堪用就好!
ML 学习特点,不强调模型 100% 正确,是有价值的,堪用的!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









