







 本文详细介绍了Scrapy框架的安装、使用及实战项目,包括Scrapy的架构、Shell、Item Pipeline、Spider、CrawlSpider、Request和Response、下载中间件、Settings的设置,以及Scrapy在不同场景中的应用。通过实例展示了如何创建项目、定义Item、编写Spider、处理数据和应对反爬机制,帮助读者从基础到进阶掌握Scrapy爬虫开发。
本文详细介绍了Scrapy框架的安装、使用及实战项目,包括Scrapy的架构、Shell、Item Pipeline、Spider、CrawlSpider、Request和Response、下载中间件、Settings的设置,以及Scrapy在不同场景中的应用。通过实例展示了如何创建项目、定义Item、编写Spider、处理数据和应对反爬机制,帮助读者从基础到进阶掌握Scrapy爬虫开发。
四、Scrapy 框架
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图(绿线是数据流向):
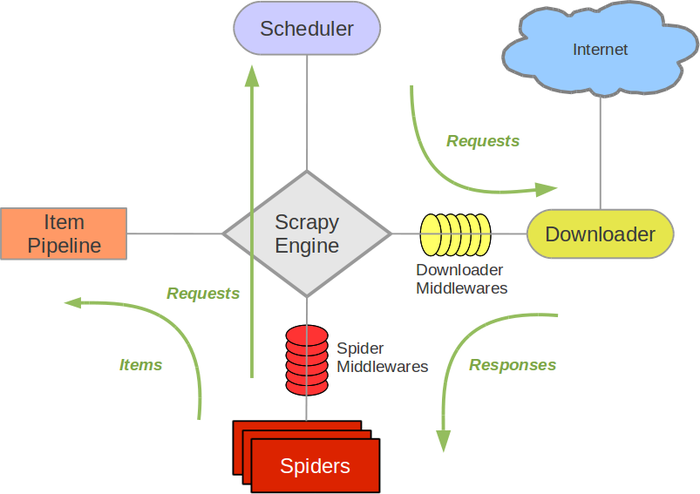
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行…
引擎:Hi!Spider, 你要处理哪一个网站?Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
4.1 Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Windows 安装方式
- Python 2 / 3
- 升级pip版本:
pip install --upgrade pip - 通过pip 安装 Scrapy 框架
pip install Scrapy
Ubuntu 需要9.10或以上版本安装方式
- Python 2 / 3
- 安装非Python的依赖
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev - 通过pip 安装 Scrapy 框架
sudo pip install scrapy
安装后,只要在命令终端输入 scrapy,提示类似以下结果,代表已经安装成功
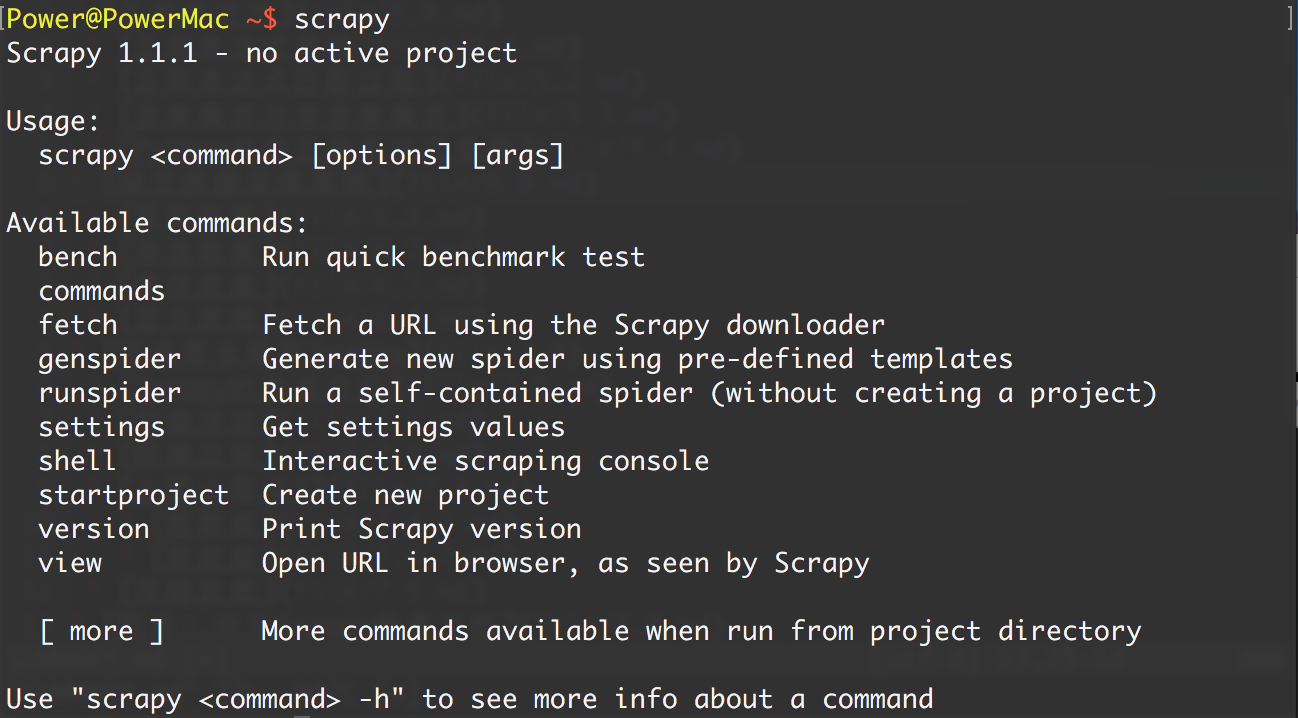
具体Scrapy安装流程参考:http://doc.scrapy.org/en/latest/intro/install.html#intro-install-platform-notes 里面有各个平台的安装方法
4.2 入门案例
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
一. 新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider
- 其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
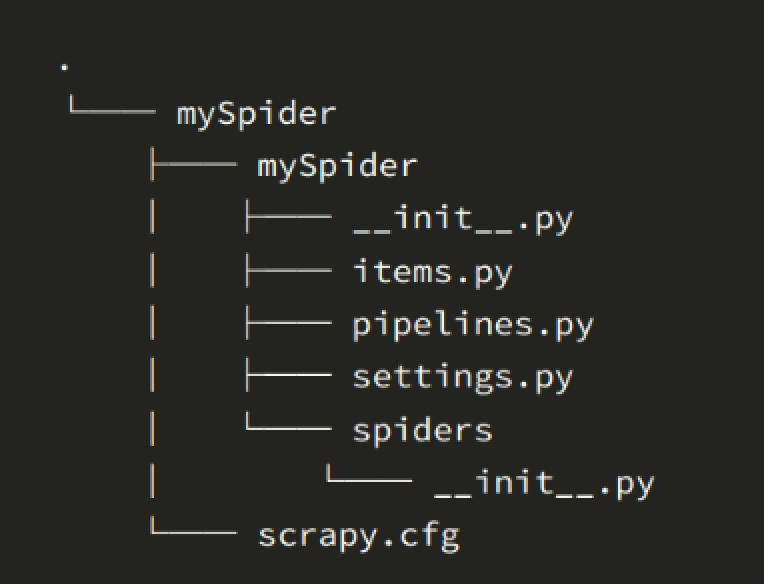
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
二、明确目标(mySpider/items.py)
我们打算抓取:http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息。
- 打开mySpider目录下的items.py
- Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
- 可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item。
- 接下来,创建一个ItcastItem 类,和构建item模型(model)。
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
三、制作爬虫 (spiders/itcastSpider.py)
爬虫功能要分两步:
- 爬数据
- 在当前目录下输入命令,将在
mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
- 打开 mySpider/spider目录里的 itcast.py,默认增加了下列代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实也可以由我们自行创建itcast.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。start_urls = ():爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
将start_urls的值修改为需要爬取的第一个url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
修改parse()方法
def parse(self, response):
with open("teacher.html", "w") as f:
f.write(response.text)
然后运行一下看看,在mySpider目录下执行:
scrapy crawl itcast
是的,就是 itcast,看上面代码,它是 ItcastSpider 类的 name 属性,也就是使用 scrapy genspider命令的爬虫名。
一个Scrapy爬虫项目里,可以存在多个爬虫。各个爬虫在执行时,就是按照 name 属性来区分。
运行之后,如果打印的日志出现 [scrapy] INFO: Spider closed (finished),代表执行完成。 之后当前文件夹中就出现了一个 teacher.html 文件,里面就是我们刚刚要爬取的网页的全部源代码信息。
- 取数据
- 爬取整个网页完毕,接下来的就是的取过程了,首先观察页面源码:
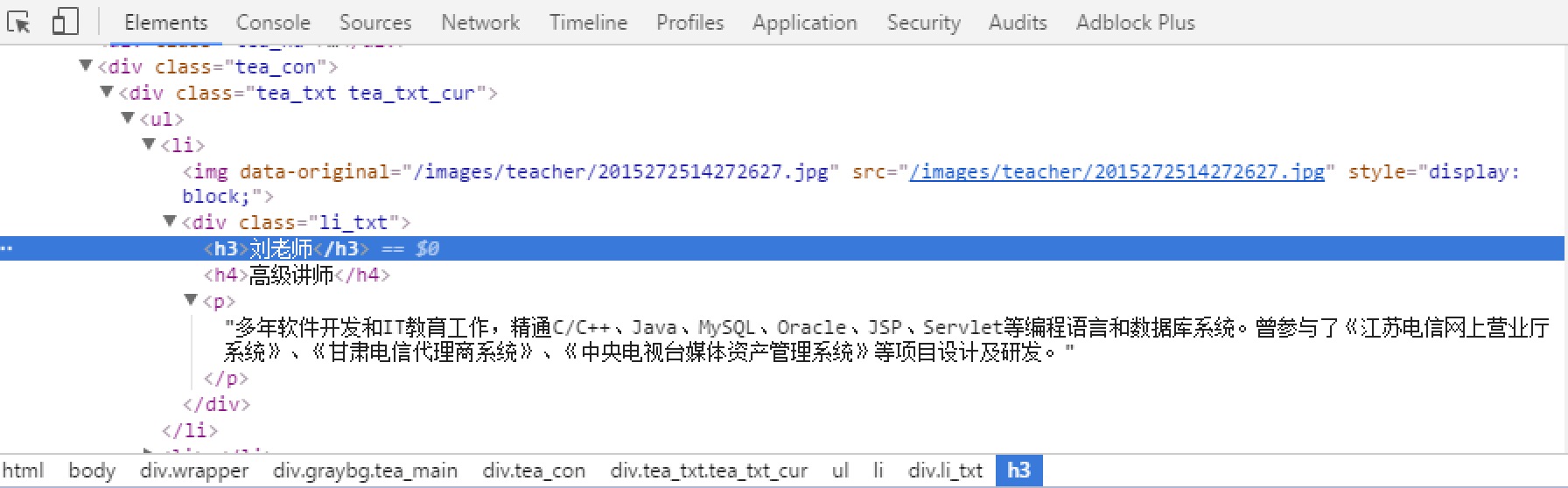
<div class="li_txt">
<h3> xxx </h3>
<h4> xxxxx </h4>
<p> xxxxxxxx </p>
是不是一目了然?直接上XPath开始提取数据吧。
- 我们之前在mySpider/items.py 里定义了一个ItcastItem类。 这里引入进来
from mySpider.items import ItcastItem
- 然后将我们得到的数据封装到一个
ItcastItem对象中,可以保存每个老师的属性:
from mySpider.items import ItcastItem
def parse(self, response):
#open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
#extract()方法返回的都是字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后数据
return items
- 我们暂时先不处理管道,后面会详细介绍。
3.保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
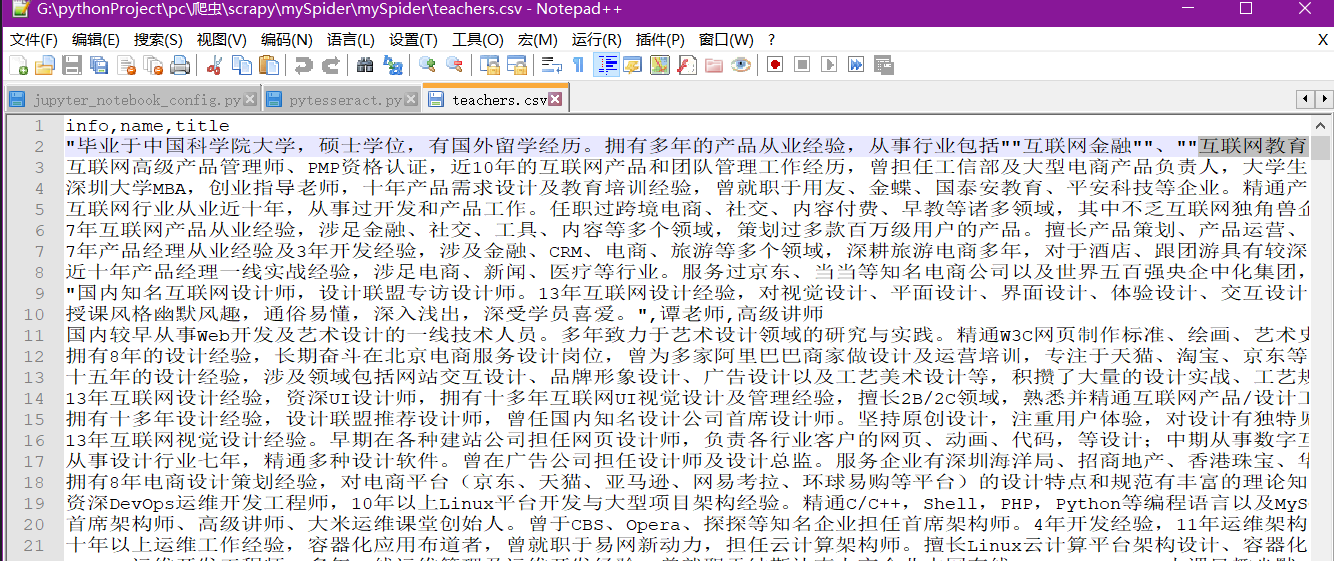
在命令行中输入我们想要保存的数据格式,这里比如说csv

运行完之后查看我们的teachers.csv
4.3 Scrapy Shell
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。
如果安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。(推荐安装IPython)
启动Scrapy Shell
进入项目的根目录,执行下列命令来启动shell:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
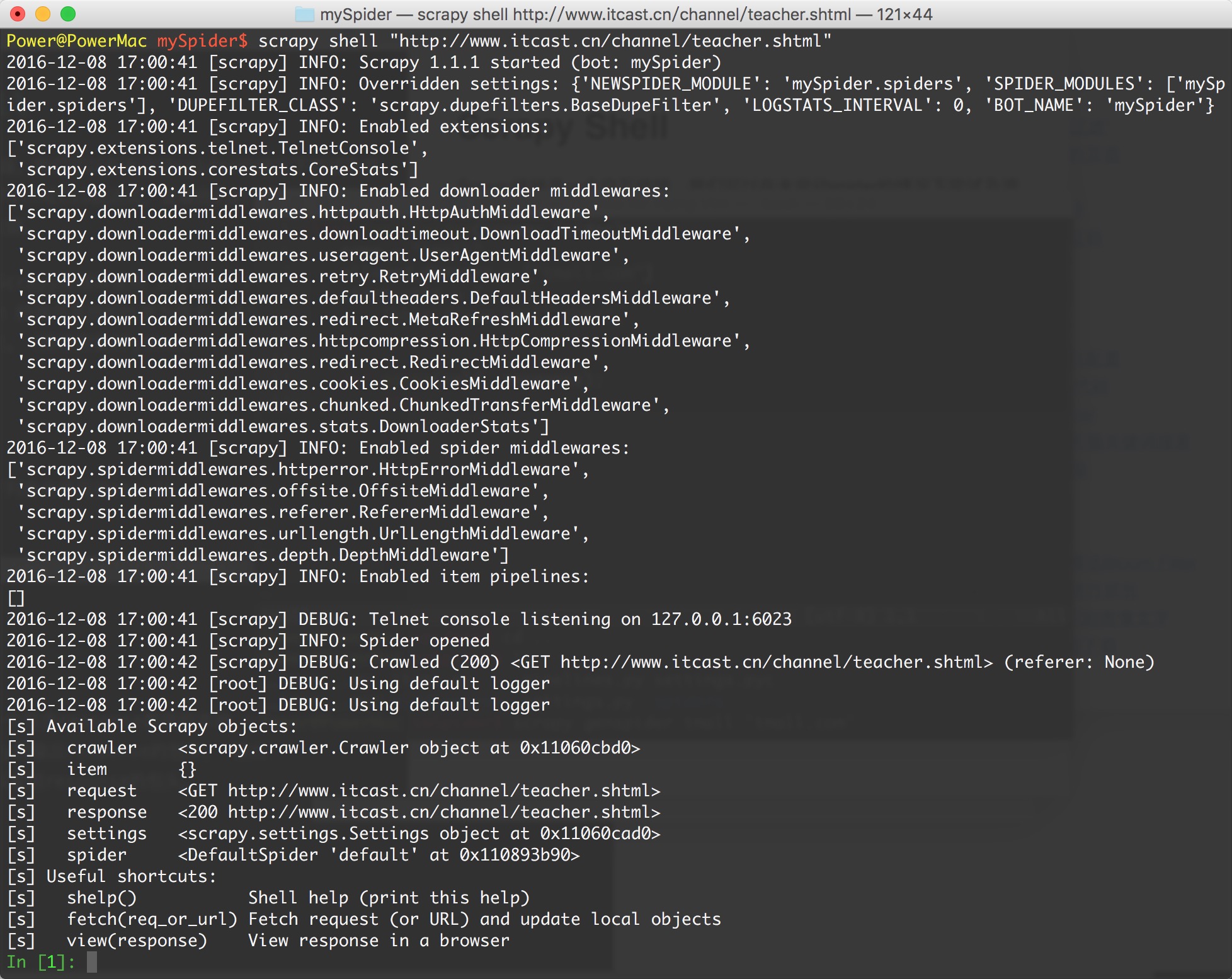
Scrapy Shell根据下载的页面会自动创建一些方便使用的对象,例如 Response 对象,以及 Selector 对象 (对HTML及XML内容)。
- 当shell载入后,将得到一个包含response数据的本地 response 变量,输入
response.body将输出response的包体,输出response.headers可以看到response的包头。 - 输入
response.selector时, 将获取到一个response 初始化的类 Selector 的对象,此时可以通过使用response.selector.xpath()或response.selector.css()来对 response 进行查询。 - Scrapy也提供了一些快捷方式, 例如
response.xpath()或response.css()同样可以生效(如之前的案例)。
Selectors选择器
Scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法,最常用的还是xpath:
- xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
- extract(): 序列化该节点为字符串并返回list
- css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
- re(): 根据传入的正则表达式对数据进行提取,返回字符串list列表
XPath表达式的例子及对应的含义:
/html/head/title: 选择<HTML>文档中 <head> 标签内的 <title> 元素
/html/head/title/text(): 选择上面提到的 <title> 元素的文字
//td: 选择所有的 <td> 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
尝试Selector
我们用腾讯社招的网站http://hr.tencent.com/position.php?&start=0#a举例:
# 启动
scrapy shell "http://hr.tencent.com/position.php?&start=0#a"
# 返回 xpath选择器对象列表
response.xpath('//title')
[<Selector xpath='//title' data='<title>职位搜索 | 社会招聘 | Tencent 腾讯招聘</title'>]
# 使用 extract()方法返回字符串列表
response.xpath('//title').extract()
['<title>职位搜索 | 社会招聘 | Tencent 腾讯招聘</title>']
# 打印列表第一个元素,没有则返回None
print response.xpath('//title').extract_first()
<title>职位搜索 | 社会招聘 | Tencent 腾讯招聘</title>
#contains的用法,or的用法,last()的含义
In [6]: response.xpath('//*[contains(@class,"odd") or contains(@class,"even")]/td[last()]/text()').extract()
Out[6]:
['2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02']
In [4]: response.xpath('//a[contains(@href,"position_detail.php?")]/text()').extract()
Out[4]:
['19407-移动游戏平台合作(上海)',
'19407-手游商业化与本地化策划(上海)',
'OMG236-腾讯视频平台高级产品经理(深圳)',
'OMG096-科技频道记者(北京)',
'18402-项目管理',
'IEG-招聘经理(深圳)',
'OMG097-视觉设计师(北京)',
'OMG097-策略产品经理/产品运营(北京)',
'OMG097-策略产品经理/产品运营(北京)',
'OMG097-数据产品经理(北京)']
In [5]: response.xpath('//*[contains(@class,"odd") or contains(@class,"even")]/td[last()-1]/text()').extract()
Out[5]: ['上海', '上海', '深圳', '北京', '深圳', '深圳', '北京', '北京', '北京', '北京']
以后做数据提取的时候,可以把现在Scrapy Shell中测试,测试通过后再应用到代码中。
当然Scrapy Shell作用不仅仅如此,但是不属于我们课程重点,不做详细介绍。
官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.html
4.4 Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:
- 验证爬取的数据(检查item包含某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取结果保存到文件或者数据库中
编写item pipeline
编写item pipeline很简单,item pipiline组件是一个独立的Python类,其中process_item()方法必须实现:
import something
class SomethingPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
# doing something
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
完善之前的案例:
item写入JSON文件
以下pipeline将所有(从所有’spider’中)爬取到的item,存储到一个独立地items.json 文件,每行包含一个序列化为’JSON’格式的’item’。
打开 pipelines.py 文件,写入下面代码:
# pipelines.py
import json
class ItcastJsonPipeline(object):
def __init__(self):
self.file = open('teacher.json', 'wb')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
启用一个Item Pipeline组件
为了启用Item Pipeline组件,必须将它的类添加到 settings.py文件ITEM_PIPELINES 配置,就像下面这个例子:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#'mySpider.pipelines.SomePipeline': 300,
"mySpider.pipelines.ItcastJsonPipeline":300
}
分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内(0-1000随意设置,数值越低,组件的优先级越高)
重新启动爬虫
将parse()方法改为的如下代码
思考如果将代码改成下面形式,结果完全一样。请思考 yield 在这里的作用:
import scrapy
from mySpider.items import ItcastItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
def parse(self, response):
# open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
# extract()方法返回的都是字符串
name = each.xpath("h3/text()").extract_first()
title = each.xpath("h4/text()").extract_first()
info = each.xpath("p/text()").extract_first()
item['name'] = name
item['title'] = title
item['info'] = info
# 将获取的数据交给pipelines
yield item
# 返回数据,不经过pipeline
# return items
然后执行下面的命令:
scrapy crawl itcast
查看当前目录是否生成teacher.json
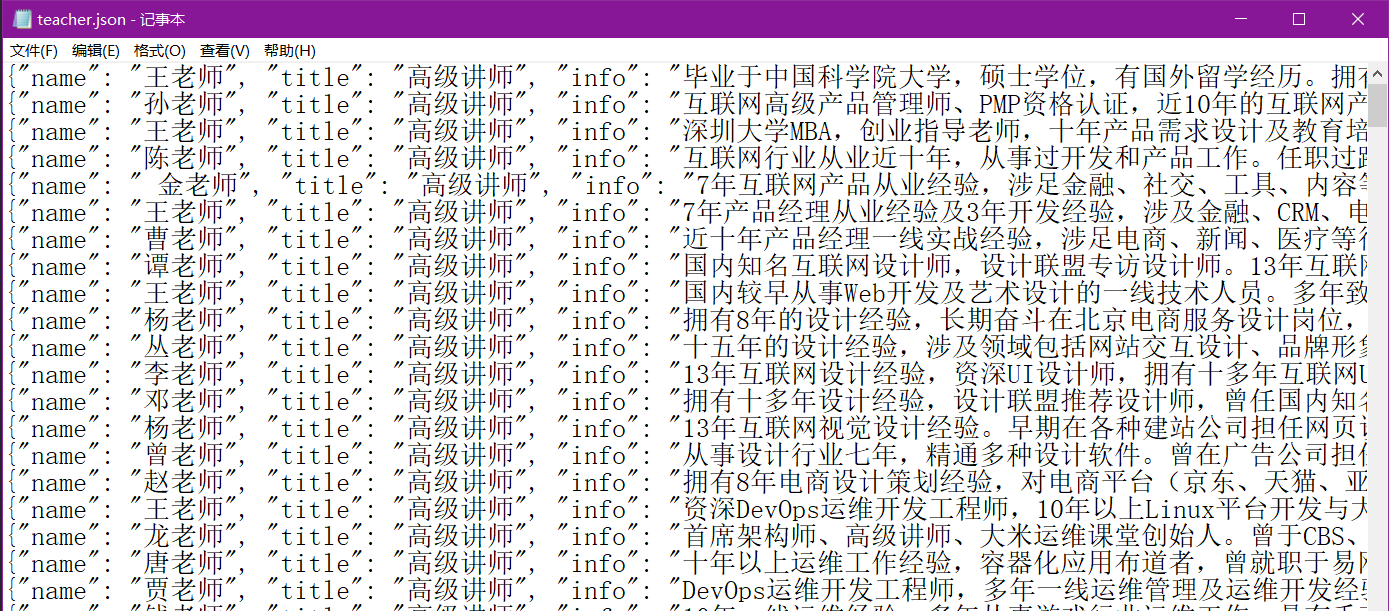
查看json数据的内容
4.5 Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
class scrapy.Spider是最基本的类,所有编写的爬虫必须继承这个类。
主要用到的函数及调用顺序为:
__init__() : 初始化爬虫名字和start_urls列表
start_requests() 调用make_requests_from url():生成Requests对象交给Scrapy下载并返回response
parse() : 解析response,并返回Item或Requests(需指定回调函数)。Item传给Item pipline持久化 , 而Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
源码参考
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
name = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6600
6600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









