







In density-based clustering, clusters are defined as areas of higher density than the remainder of the data set. Objects in sparse areas - that are required to separate clusters-are usually considered to be noise and border points. --wiki
在基于密度的聚类中,聚类定义为密度高于数据集其余部分的区域。稀疏区域中的对象(用于分隔cluster簇)通常被认为是噪声和边界点。
DBSCAN(Density-based spatial clustering of applications with noise带噪声的基于密度的空间聚类应用)与许多更新的方法相比,它具有定义明确的集群模型,称为”密度可达性“,类似于基于链接的聚类,它基于在特定距离阈值内的链接点。然而,它只连接满足密度标准的点,在原始变体中定义为该半径内其他对象的最小数量。聚类(cluster)由所有密度链接的对象加这些对象范围内所有的对象组成。DBSCAN的另一个有趣的特性是它的复杂度很低,它需要在数据库上进行线性数量的范围查询-并且每次运行都会发现基本相同的结果(它对于核心点和噪声点是确定性的,而对于边界点则不是),因此无需多次运行它,OPTICS(ordering points to identify the clustering structure用于标识聚类结构的排序点)是DBSCAN的一般化(generalization),它消除了为范围参数图片选择适当值的需要,并且产生与链接聚类相关的分层结果。
DBSCAN 和OPTICS的主要缺点是它们期望某种密度下降来检测聚类的边界。例如,在具有重叠高斯分布的数据集上,这些算法产生的聚类边界通常看来是任意的,因为聚类密度连续下降。在由高斯混合构成的数据集上,这些算法几乎总是比 诸如EM聚类这样的 能够对此类数据进行精确建模的方法 表现更好。
均值偏移(mean-shift)是一种聚类方法,其中,根据核密度估计,将每个对象移动到其活动中最密集的区域。最终,这些对象会聚到局部的密度最大值。类似于k-means聚类,这些“密度吸引子”可以用作数据集的代表,但均值-漂移可以检测类似于DBSCAN的任意形状的聚类。但是由于费时费力的迭代过程和密度估计,这导致聚类尾部过于碎片化。
在上一节中,我们介绍了高斯混合模型(Gaussian Mixture Model),它是由聚类estimator和密度estimator混合而成。回想一下密度估计器(density estimator),如果要一个算法从D维数组中产生一个D维概率分布估计,高斯混合模型算法通过将密度表示为高斯分布的加权求和来实现它。从某种意义上说,核密度估计(kernel density estimation)是一种将高斯混合思想发挥到其逻辑极限的算法:它使用由每个点的一个高斯分量组成的混合,从而产生基本上非参数的密度估计量。
密度估计是一种旨在对生成数据集的概率分布进行建模。对于一维数据,我们熟悉的一种简单的density estimator有:直方图(histogram)。直方图将数据分成离散的桶,计算掉在每个桶中的点的个数,然后直观地可视化这个结果。
例如,我们从两个正态分布(normal distribution)中创建一些数据:
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
def make_data(N, f=0.3, rseed=1):
rand = np.random.RandomState(rseed)
x = rand.randn(N)
x[int(f * N):] += 5
return x
x = make_data(1000)
可以使用plt.hist()函数创建基于标准计数的直方图。通过指定直方图的normed参数最终得到normalized直方图,其中桶的高度不反应计数,而是反应概率密度。
hist = plt.hist(x, bins=30, normed=True)

需要注意的是,对于均等分桶(equal binning),此种归一化仅改变y轴上的比例,而相对高度和使用计数的方法构建的直方图中的高度基本相同。选择此归一化,以便直方图的总面积等于1,我们可以通过下面的代码来查看直方图函数的输出来确认:
density, bins, patches = hist
widths = bins[1:] - bins[:-1]
(density * widths).sum()
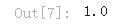
使用直方图作为密度估计器的问题之一是,桶的大小和位置的选择可能会导致表示具有本质上不同的特征。例如,如果我们仅用20个点查看数据的样子,如何绘制这些桶,会导致我们对数据有完全不同的解析!例如下面这个例子:
x = make_data(20)
bins = np.linspace(-5, 10, 10)
fig, ax = plt.subplots(1, 2, figsize=(12, 4),
sharex=True, sharey=True,
subplot_kw={
'xlim':(-4, 9),'ylim':(-0.02, 0.3)})
fig.subplots_adjust(wspace=0.05)
for i, offset in enumerate([0.0, 0.6]):
ax[i].hist(x, bins=bins + offset, normed=True)
ax[i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









