







1.基本原理
在我们日常开发中,ArrayList 是最常用的一种集合。我们都知道ArrayList的底层是基于数组来实现的,那么,
对于数组呢,我们都不陌生:数组是同一数据类型的集合,一旦创建后,大小就不可变。也就是说长度是固定的。
在ArrayList 中,若我们把数组大小设置为20,往ArrayList里面插入数据,当元素超过20之后,就会有一个数组的扩容。
会新建一个更大的数组。然后把以前的数组拷贝到新的数组里面去。这儿的数组扩容和元素拷贝,就会相对慢一些。
因此,ArrayList有以下缺点:
缺点一:频繁的往ArrayList里面插入数据,会导致它频繁的数组扩容,这样会影响性能。
缺点二:对于数组,我们都知道,当你往数组的中间插入元素的时候,会让新插入元素位置的后面的元素全部往后挪动一位。
所以,往ArrayList中间插入数据的时候,性能较差,因为会导致新增元素后面元素的移动。
再简单说一下数组,计算机会给数组分配连续的内存空间,这块内存有一个首地址,我们访问数组的某个元素的时候,会通过一个寻址公式
来计算存储的地址,公式:arr[i]_address = base_address + i * data_type_size(arr[i] 首地址 = 数组内存块首地址 + 数据类型大小 * i ,其中i为偏移量。)
baseaddress:内存块的首地址。datatype_size:数组中每个元素的大小,比如每个元素大小是4个字节。所以,数组根据下标随机访问的时间复杂度是O(1)。
了解了数组随机访问元素的机制后,ArrayList的优点就出来了:
ArrayList基于数组实现的,随机读性能很高,如:list.get(1). 数组可以直接通过内存地址访问元素,所以ArrayList也可以基于底层数组,直接根据内存地址访问元素。
2.什么时候用ArrayList呢?
当我们不会频繁的插入元素,不会导致频繁的元素的位置移动,数组扩容。比如说,有一批数据,查询出来灌入ArrayList中,后续不会频繁插入元素,主要遍历这个集合。或者通过索引随机读取某个元素,
这种情况下使用ArrayList是很合适的。
ArrayList还有一个主要的功能,就是它里面的元素是有顺序的,比如大量业务中的列表,都有排序。我们拿到整理好的排序的数据之后,可以直接按照顺序灌入ArrayList中。
3.ArrayList核心方法
我们看一下ArrayList的源码。


默认的构造函数,直接初始化一个ArrayList实例的话,内部是一个默认的空数组。并且默认的初始化数组的大小的值,为10。

在平常的开发中,一般来说,在你可以推测出数据数量的话,尽可能不要去使用这个默认的构造函数。因为你使用ArrayList的话,基本上来说就是默认它不会太平凡的往
里面插入、移除元素的操作。
所有,构造ArrayList的时候,给一个比较靠谱的初始化数组的大小的值。比如说给100,这样可以避免数组太小,导致数组不断的扩容。

4.add()源码
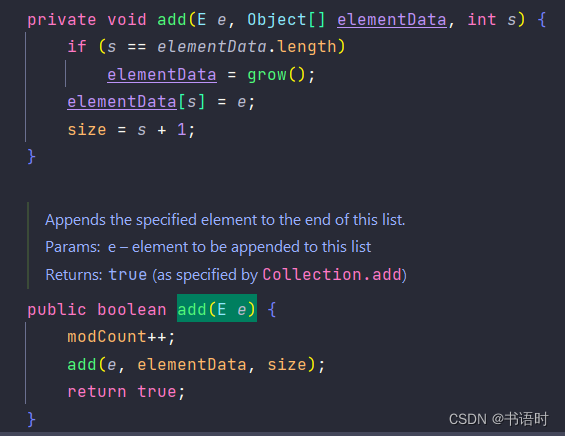
看以上源码,我们每次往ArrayList中塞入数据的时候,都会判断一下,当前数据的元素是否塞满了,如果塞满的话,此时就会扩容这个数据,让后将老数组的元素拷贝到新的数组中去。
确保数组一定是可以插入更多的元素。
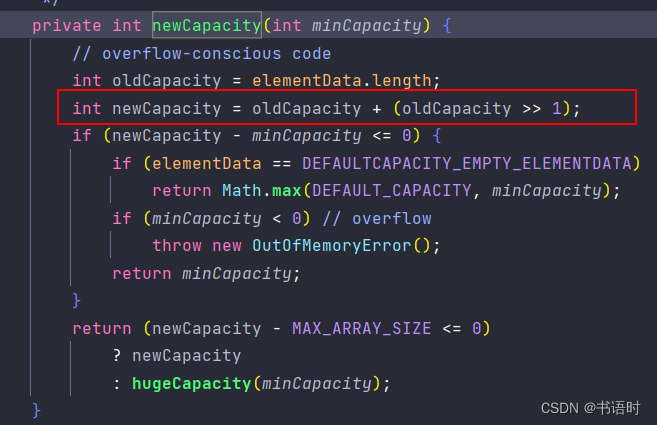
5.ArrayList数组扩容以及元素拷贝
从上面我们知道,若我们使用的是默认数组的大小,也就是10,如果我们已经往数组里面插入了10个元素了,那么现在数组的size=10 ,capacity=10,
此时调通add(),再插入一个元素,也就是插入第11个元素,那么肯定是插入不进去的。 要插入第11个元素,就会对数组进行扩容。
int newCapacity = oldCapacity + (oldCapacity >> 1);
其中,oldCapacity=10
oldCapacity + (oldCapacity >> 1 =5
newCapacity=15
数组扩容的时候,old数组的大小+old数组的大小>>1 就得到新的数组大小。
elementData = Arrays.copyOf(elementData,newCapacity(minCapacity)),
实现了数组元素的拷贝。


















 2514
2514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











