







 本文介绍了Word Mover's Distance(WMD)算法,它将文档距离表示为最小的单词迁移成本,并通过线性规划求解。文章还探讨了WMD的优化方法,包括Word Centroid Distance(WCD)、Relaxed Word Moving Distance(RWMD)和Prefetch and Prune策略,以提高计算效率。此外,文章提到了WMD的优点(无监督、无需超参数)和缺点(处理OOV问题和缺乏语序信息),并展示了Python代码实现。
本文介绍了Word Mover's Distance(WMD)算法,它将文档距离表示为最小的单词迁移成本,并通过线性规划求解。文章还探讨了WMD的优化方法,包括Word Centroid Distance(WCD)、Relaxed Word Moving Distance(RWMD)和Prefetch and Prune策略,以提高计算效率。此外,文章提到了WMD的优点(无监督、无需超参数)和缺点(处理OOV问题和缺乏语序信息),并展示了Python代码实现。
本文目录
本次讲解的论文来自J.Kusner等人2015年发表的论文,论文名字为From Word Embeddngs To Document Distances。
一、全篇概述
全篇最大的贡献是提出了WMD算法,并且为了提高计算速度,减低时间复杂度对模型进行了化简,得到WCD及RWMD算法,然后综合WCD及RWMD提出预取和修剪(Prefetch and prune),在几乎不影响算法准确率的情况下,大大提升了算法的计算效率。下面先介绍几个基本概念(预备知识),再一一讲解上面所提到的各种算法。
二、概念
1. Word2vec
Word2Vec是2013年由Mikolov等人提出的一种word emmbedding方法,简单的说就是将单词通过一个神经网络变为一个向量,用这个向量来表示这个单词,通过Word2Vec后得到的单词的向量表示在一定程度上保留了单词的语义信息,详见论文《Efficient Estimation of Word Representations in Vector Space》。
2. nBOW representation
nBOW全称normalized bag-of-words,即归一化词袋模型,就是对词袋中的词的一种向量表示,也可以从文档的角度理解,每一个文档都被表示成了一个向量。通过下面的例子可以很快理解nBOW representation。
假定数据集中只有两个文档:

经过删除停用词操作后,词袋中一共包含八个词,即上图中加粗的单词。
d i = c i ∑ j = 1 n c j d_i=\frac{c_i}{\sum_{j=1}^{n}{c_j}} di=∑j=1ncjci
我们用上式计算单词i在一个文档中的权重,其中ci表示单词i在某一文档中出现的次数,分母表示该文档的总的单词个数(除去停用词后的)。计算结果如下:

计算最后会得到一个m*n的矩阵,m为文档数量,n为词袋中单词个数。
2. Word travel cost
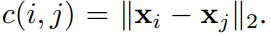
正如上式所示,单词的‘旅行成本’,就是两个单词的词向量之间的欧氏距离。
3. Document distance
D o c u m e n t d i s t a n c e 表 示 一 个 文 档 中 的 单 词 全 部 迁 移 到 另 一 个 文 档 的 总 成 本 , 可 以 表 示 为 ∑ i , j = 1 n T i j c ( i , j ) 其 中 T 是 一 个 矩 阵 , T i j > 0 表 示 单 词 i 有 多 少 迁 移 到 了 单 词 j . ∑ j = 1 n T i j = d i , ∀ i ∈ { 1 , 2 , . . . , n } , d 中 的 第 i 个 词 的 输 出 流 总 和 等 于 d i . ∑ i = 1 n T i j = d j ′ , ∀ j ∈ { 1 , 2 , . . . , n } , d 中 的 第 j 个 词 的 输 入 流 总 和 等 于 d j . Document \ distance表示一个文档中的单词全部迁移到另一个文档的总成本,可以表示为 \\ \sum_{i,j=1}^{n}{T_{ij}c(i,j)} \\ 其中T是一个矩阵,T_{ij}>0表示单词i有多少迁移到了单词j . \\ \sum_{j=1}^{n}{T_{ij}} = d_i,\forall i \in \{1,2,...,n\},d中的第i个词的输出流总和等于d_i. \\ \sum_{i=1}^{n}{T_{ij}} = d'_j,\forall j \in \{1,2,...,n\},d中的第j个词的输入流总和等于d_j. Document distance表示一个文档中的单词全部迁移到另一个文档的总成本,可以表示为i,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









