






一、重新定义数据检索:为什么需要搜索引擎?
1.1 传统数据库的局限性
-
关键词搜索困境:传统数据库的
LIKE '%keyword%'查询导致全表扫描。 -
相关性排序缺失:无法根据语义相关度智能排序。
-
多字段联合搜索:跨字段查询效率低下。
-
实时分析瓶颈:大规模数据聚合性能急剧下降。
1.2 Elasticsearch 核心价值矩阵
| 特性 | 传统 RDBMS | Elasticsearch |
|---|---|---|
| 查询模式 | 精确匹配 | 相关性搜索 |
| 数据结构 | 严格 Schema | Schema-less 动态映射 |
| 扩展方式 | 垂直扩展 | 水平扩展 |
| 写入吞吐 | 1k-5k ops/s | 10k-100k ops/s |
| 典型延迟 | 100ms-1s | 10ms-500ms |
二、底层引擎揭秘:Lucene 架构深度剖析
2.1 倒排索引的工程实现
-
分词处理:将文本分解为词条,如
"The quick brown fox"分词为["the", "quick", "brown", "fox"]。 -
词项字典:构建 Term Dictionary。
-
倒排记录表:如
"fox" → (1, [position:3])。
2.2 段 (Segment) 合并策略
-
分层合并:使用 Tiered Merge Policy。
-
日志结构合并树:LSM Tree。
-
合并触发条件:段数量达到阈值(默认10)、删除文档超过50%、单个段大小超过5GB。
2.3 评分算法演进
-
TF-IDF 经典模型:
score(q,d) = ∑( tf(t in d) * idf(t)^2 * boost(t) * norm(t,d) ) -
BM25 改进算法(Elasticsearch 5.x+ 默认):
BM25(q,d) = ∑( IDF(t) * (f(t,d) * (k1 + 1)) / (f(t,d) + k1 * (1 - b + b * |d|/avgdl)) ) -
向量空间模型:支持余弦相似度计算。
三、分布式集群架构设计
3.1 节点角色细分
| 节点类型 | 推荐配置 | 核心职责 |
|---|---|---|
| Master-eligible | 3节点(奇数) | 集群状态管理/索引元数据 |
| Data | 多可用区部署 | 分片存储/CRUD操作 |
| Ingest | CPU密集型 | Pipeline预处理(GeoIP/UserAgent解析) |
| ML | GPU加速 | 异常检测/预测分析 |
| Coordinating | 无状态横向扩展 | 请求路由/结果聚合 |
3.2 分片策略黄金法则
-
容量规划公式:
总分片数 = 节点数 × 每节点分片数 × (1 + 副本数) -
推荐值:每节点分片数 ≤ 20(SSD环境)。
-
热点分片问题:使用
index.routing_partition_size优化分布。 -
冷热架构:
PUT _ilm/policy/hot_warm_policy { "phases": { "hot": { "actions": { "rollover": { "max_size": "50GB" } } }, "warm": { "min_age": "7d", "actions": { "allocate": { "require": { "data_type": "warm" } } } } } }
四、高级查询模式解析
4.1 复合查询实战
-
场景:电商商品搜索(必须包含“手机”,排除“二手”,优先展示“5G”)。
GET /products/_search { "query": { "bool": { "must": [ { "match": { "name": "手机" } } ], "must_not": [ { "term": { "condition": "二手" } } ], "should": [ { "match": { "spec": "5G" } } ], "filter": [ { "range": { "price": { "gte": 1000, "lte": 5000 } } } ] } } }
4.2 聚合分析进阶
-
多维度分析:统计不同品牌手机的价格分布。
GET /products/_search { "size": 0, "aggs": { "brands": { "terms": { "field": "brand.keyword" }, "aggs": { "price_stats": { "stats": { "field": "price" } }, "date_histo": { "date_histogram": { "field": "release_date", "calendar_interval": "month" } } } } } }
4.3 地理位置查询
-
附近3公里内的咖啡厅:
GET /places/_search { "query": { "geo_distance": { "distance": "3km", "location": { "lat": 31.2304, "lon": 121.4737 } } }, "sort": [ { "_geo_distance": { "location": [121.4737, 31.2304], "order": "asc", "unit": "km" } } ] }
五、性能调优手册
5.1 JVM 配置最佳实践
# jvm.options
-Xms16g
-Xmx16g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:InitiatingHeapOccupancyPercent=355.2 写入优化技巧
-
批量写入:推荐 5-15MB/批次。
-
Refresh Interval:
PUT /logs/_settings { "index.refresh_interval": "30s" } -
索引缓冲区:
PUT /_cluster/settings { "indices.memory.index_buffer_size": "20%" }
5.3 查询优化策略
-
文件系统缓存:预留 50% 内存给 OS 缓存。
-
使用
forcemerge减少段数量。 -
查询短路:
"query": { "bool": { "filter": [ ... ], // 不计算评分 "must": [ ... ] // 计算评分 } } -
索引分片预分配:
curl -XPUT "host:9200/index/_shrink/target_index" \ -H 'Content-Type: application/json' -d' { "settings": { "index.number_of_shards": 5 } }'
六、安全与监控体系
6.1 安全防护三要素
-
认证:
xpack.security.authc: realms: native: native1: order: 0 saml: saml1: order: 1 -
授权:
POST /_security/role/logs_writer { "indices": [ { "names": ["logs-*"], "privileges": ["write", "create_index"] } ] } -
审计:
xpack.security.audit.enabled: true xpack.security.audit.logfile.events.include: authentication_failed,access_denied
6.2 监控指标体系
| 指标类别 | 关键指标 | 报警阈值 |
|---|---|---|
| 集群健康 | status (green/yellow/red) | yellow 持续 5 分钟 |
| 节点资源 | heap_usage | >75% 持续 10 分钟 |
| 索引性能 | index_latency | >500ms |
| 查询性能 | search_latency | >1s |
| 磁盘健康 | disk_used_percent | >85% |
七、生态集成全景图
7.1 ELK Stack 数据管道

7.2 机器学习实战
-
异常检测配置:
JSON复制
PUT _ml/anomaly_detectors/network_errors { "analysis_config": { "bucket_span": "15m", "detectors": [ { "function": "count", "over_field_name": "host.ip" } ] }, "data_description": { "time_field": "@timestamp" } }
八、面向未来的 Elasticsearch
8.1 向量搜索
JSON复制
PUT /image_search
{
"mappings": {
"properties": {
"vector": {
"type": "dense_vector",
"dims": 512,
"index": true,
"similarity": "cosine"
}
}
}
}8.2 云原生演进
-
Serverless 架构:按查询量计费。
-
Kubernetes Operator:自动化集群管理。
-
跨云联邦查询:统一查询多个云区域数据。
结语:技术选型决策树
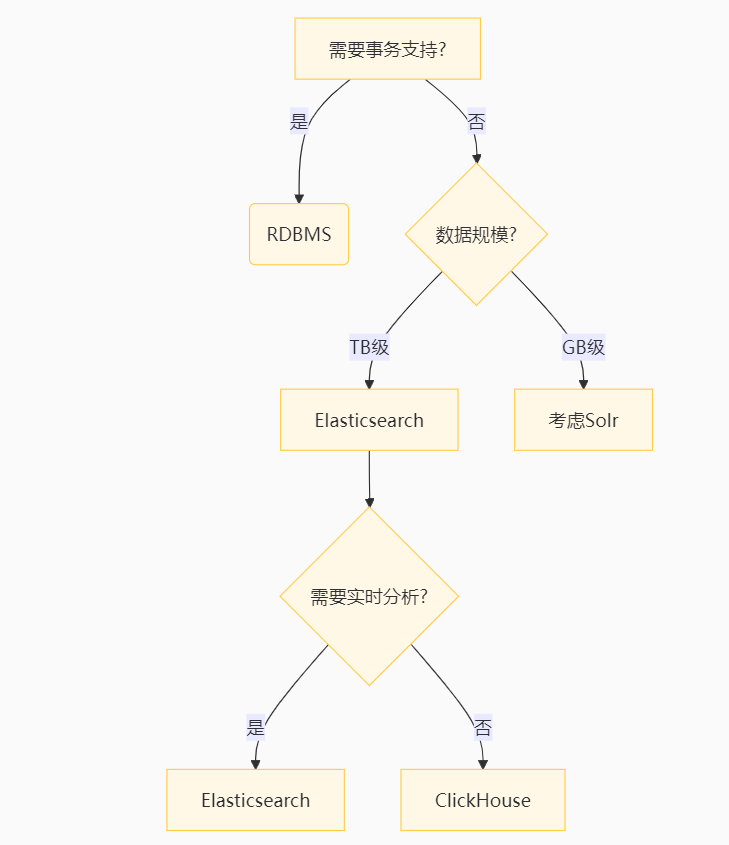
通过本文的系统性解读,您已掌握 Elasticsearch 的核心原理与高级用法。无论是构建亿级日志平台,还是实现智能推荐系统,Elasticsearch 都将成为您数据架构中的核心引擎。建议通过官方文档和真实场景不断深化理解,让搜索技术真正赋能业务创新。


















 2493
2493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











