






 本文详细介绍了DQL查询语句,包括排序、聚合函数、分组、LIMIT语句和CASE WHEN语句的使用。此外,还深入讨论了数据库备份的重要性及方法,以及数据库约束的概念,如主键、唯一约束、非空约束、默认值和外键约束,强调了外键约束在数据完整性中的作用,并探讨了级联操作的几种类型。
本文详细介绍了DQL查询语句,包括排序、聚合函数、分组、LIMIT语句和CASE WHEN语句的使用。此外,还深入讨论了数据库备份的重要性及方法,以及数据库约束的概念,如主键、唯一约束、非空约束、默认值和外键约束,强调了外键约束在数据完整性中的作用,并探讨了级联操作的几种类型。
DQL查询语句
排序
准备数据:
create database if not exists db02;
use db02;
drop table if exists student ;
CREATE TABLE student (
id int, -- 编号
`name` varchar(20), -- 姓名
age int, -- 年龄
sex char(1), -- 性别
address varchar(100), -- 地址
math int, -- 数学
english int -- 英语
);
-- 插入数据
insert into student values(1,'小明',24,'男','湖北武汉',90,100);
insert into student values(2,'小红',25,'女','湖南长沙',88,69);
insert into student values(3,'小龙',26,'男','江西南昌',78,80);
insert into student values(4,'小丽',24,'女','安徽合肥',95,80);
insert into student values(5,'张三',19,'男','福建福州',80,90);
insert into student values(6,'李四',24,'男','广东广州',100,95);
insert into student values(7,'王五',24,'男','河南郑州',90,95);排序本身不会影响到表中的记录位置,只是查询结果变成有序的。默认是升序,从小到大。 数字和字符都有大小的。
语法:
SELECT * FROM 表名 ORDER BY 字段名 [ASC/DESC]升序:asc
降序:desc
单列排序:
-- 查询所有数据,使用年龄升序排序
select * from student order by age asc;
-- 排序默认是升序(asc),因此asc也可以不写
select * from student order by age asc;
-- 查询所有数据,使用年龄降序排序
select * from student order by age desc;组合排序
语法:
SELECT * FROM 表名 ORDER BY 字段名1 [ASC/DESC],字段名2 [ASC/DESC] 先按字段名1进行排序,如果按1排序值相同,再按字段名2进行排序-- 查询所有数据大于20岁的学生,在年龄降序排序的基础上,如果年龄相同再以数学成绩升序排序
select * from student where age > 22 order by age desc, math asc;
聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。聚合函数会忽略空值。
五个聚合函数
| SQL中的聚合函数 | 作用 |
|---|---|
| count | 统计个数,如果这一列有NULL,null不会参与统计 |
| max | 找这一列中的最大值,一般是数值类型进行操作。 |
| min | 找这一列中的最小值 |
| sum | 求这一列的总和 |
| avg | 求这一列的平均,返回值小数average |
语法:
SELECT 聚合函数(字段名) FROM 表
-- 示例
-- 查询学生人数总数
select count(id) sum from student;
-- 查询年龄大于24的总数
select count(*) from student where age > 24;
-- 查询数学成绩总分
select sum(math) from student;
-- 查询学生的平均年龄
select avg(age) from student;
-- 查询数学成绩最高的分数
select max(age) from student;
-- 查询数学成绩最低分
select min(math) from student;分组
分组的用法
可以将表中的数据按照某个字段分组,分成不同的组之后再使用聚合函数进行计算;
语法:
SELECT * FROM 表名 WHERE 条件 GROUP BY 字段名 [HAVING 条件] GROUP BY 分组 HAVING 分组以后得到结果再进行过滤group by如何分组的?
将分组字段结果中相同内容作为一组,分段函数一般搭配聚合函数一起使用,因为只取一行。
例如:求每个性别的下的数学总成绩,我们通过上述图也能理解,分组之后查询全部数据是毫无意义的。
-- 求每个性别的下的数学总成绩
select sex 性别,sum(math) 数学总成绩 from student group by sex;

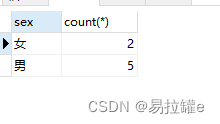
查询男女各多少人
-
查询所有数据,按性别分组。
-
统计每组人数
select sex, count(*) from student group by sex;
查询年龄大于23岁的人,按性别分组,统计每组的人数
- 先查询年龄大于23岁的人
- 再分组
- 最后统计每组的人数
select sex, count(*) from student where age>23 group by sex;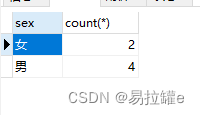
having与where的区别
1)where后面是不能再跟where语句的
2)在where后面是不可以写聚合函数的
3)分组后面不能使用where语句
having是可以当做where使用的,只是我们不介意那么做。
| 子名 | 作用 |
|---|---|
| where子句 | 先过滤掉行上的一些数据,再进行分组操作。(先过滤再分组) |
| having子句 | 先分组得到结果后再在结果上进行过滤操作。(先分组再过滤) |
limit语句
limit语句简介
作用:默认情况下查询所有行,限制查询记录的条数
语法:
select * from table limit offset,lengthoffset :跳过多少条记录,默认0
length :返回多少条记录
limit的使用场景:
分页:比如我们登录京东,淘宝,返回的商品信息可能有几万条,不是一次全部显示出来。是一页显示固定的条数。
假设我们一每页显示3条记录的方式来分页。
-- 每页显示3条
-- 第一页:跳过0条,显示3条
select * from student3 limit 0,3;
-- 如果第1个参数是0,可以省略
select * from student3 limit 3;
-- 第二页:跳过3条,显示3条
select * from student3 limit 3,3;
-- 第三页:跳过6条,显示3条(如果没有这么多记录,有多少条显示多少条)
select * from student3 limit 6,3;
-- 公式: select * from student limit (当前页-1)*页大小,页大小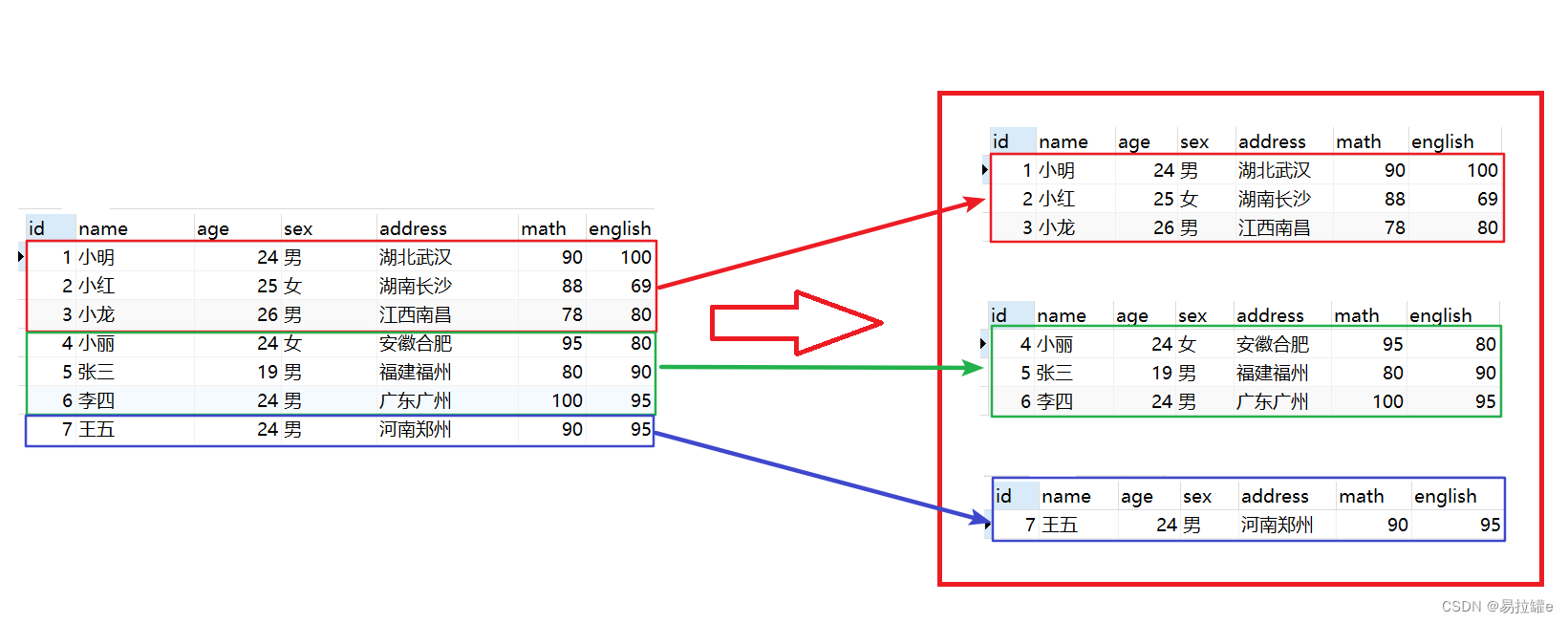
case when语句
案例一
数据准备:
DROP TABLE IF EXISTS `info`;
CREATE TABLE `info` (
`id` int(11) NOT NULL,
`province` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`population` int(255) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of info
-- ----------------------------
INSERT INTO `info` VALUES (1, '江西', 200);
INSERT INTO `info` VALUES (2, '山西', 300);
INSERT INTO `info` VALUES (3, '广西', 300);
INSERT INTO `info` VALUES (4, '湖南', 500);
INSERT INTO `info` VALUES (5, '湖北', 400);
INSERT INTO `info` VALUES (6, '广东', 800);
INSERT INTO `info` VALUES (7, '福建', 300);
INSERT INTO `info` VALUES (8, '山东', 400);
INSERT INTO `info` VALUES (9, '四川', 700);根据省份的人口数据,统计华东华南的人口数量
先统计每个省份的人数
SELECT
CASE province
WHEN '江西' THEN '华东'
WHEN '广西' THEN '华南'
WHEN '广东' THEN '华南'
WHEN '福建' THEN '华东'
WHEN '山东' THEN '华东'
ELSE '其他' END as '地区',
population as '人口'
FROM info;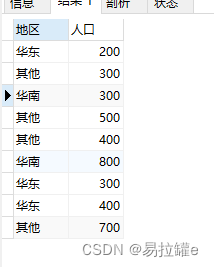
在根据地区进行分组:
SELECT
CASE province
WHEN '江西' THEN '华东'
WHEN '广西' THEN '华南'
WHEN '广东' THEN '华南'
WHEN '福建' THEN '华东'
WHEN '山东' THEN '华东'
ELSE '其他' END as '地区',
sum(population) as '总人数'
FROM info
GROUP BY 地区
order by 总人数;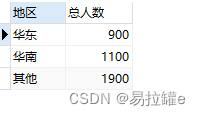
案例二
分别统计江西、山西、广西三地的男女人口
准备数据:
DROP TABLE IF EXISTS `info`;
CREATE TABLE `info` (
`id` int(11) NOT NULL,
`province` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`sex` char(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`population` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of info
-- ----------------------------
INSERT INTO `info` VALUES (1, '江西', '男', 500);
INSERT INTO `info` VALUES (2, '江西', '女', 400);
INSERT INTO `info` VALUES (3, '山西', '男', 600);
INSERT INTO `info` VALUES (4, '山西', '女', 500);
INSERT INTO `info` VALUES (5, '广西', '男', 300);
INSERT INTO `info` VALUES (6, '广西', '女', 600);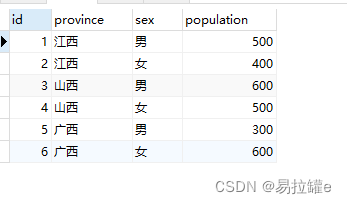
1.进行行和列的转换
2.根据省份进行分组,取每组最大值
-- 进行行和列的转换
select
province as '省份',
case when sex = '男' then population else 0 end as '男性人口',
case when sex = '女' then population else 0 end as '女性人口'
from info;
-- 根据省份进行分组,取每组最大值
select
province as '省份',
max(case when sex = '男' then population else 0 end) as '男性人口',
max(case when sex = '女' then population else 0 end) as '女性人口'
from info
group by province;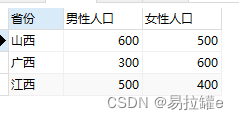
数据库备份
备份的应用场景
在服务器进行数据传输、数据存储和数据交换,就有可能产生数据故障。比如发生意外停机或存储介质损坏。这时,如果没有采取数据备份和数据恢复手段与措施,就会导致数据的丢失,造成的损失是无法弥补与估量的。
备份与还原的语句
数据备份
mysqldump命令主要用于数据库备份。
语法:
mysqldump [OPTIONS] database [tables]参数:
- options:
- -h:mysql服务器的ip
- -P:mysql服务器的端口
- -u:mysql用户名
- -p:mysql密码
- -n(--no-create-db):不包含创建数据库语句(包含建表语句和数据)
- -t(--no-create-info):不包含建表语句(只要插入语句)
- -d(--no-data):不包含数据
- -B(--database):导出数据库(也包含建库语句也包含数据)
- -A(--all-database):导出所有数据库
导出表:
mysqldump -hip地址 -P端口 -u用户名 -p密码 数据库 表1 表2... > 文件路径
mysqldump -h127.0.0.1 -P3306 -uroot -padmin db02 student > D:/test.sql如果没有写需要导出的表则默认导出库中所有的表:
mysqldump -uroot -padmin db02 > D:/test.sqlTips:-h默认值为127.0.0.1,-P默认值为3306
导出库:
mysqldump -u用户名 -p密码 --databases 库1 库2... > 文件路径
mysqldump -uroot -padmin --databases db02 > D:/test.sql
mysqldump -uroot -padmin -B test > test.sql Tips:导出库和导出表的区别在于导出库的sql语句里面加了create database db_name语句。
导出当前数据库服务器的所有数据库:
mysqldump -u用户名 -p密码 --all-databases > 文件路径
mysqldump -uroot -padmin --all-databases > D:/test.sql
mysqldump -uroot -padmin -A > D:/test.sql指定条件导出:
只导出某张表的数据(不包含建表语句):
mysqldump -uroot -padmin -t db02 student > D:/test.sql
只导出指定数据库的所有表数据(不包建库、建表语句):
mysqldump -uroot -padmin -t -n db02 > D:/test.sql
导出某张表结构(不包含表数据):
mysqldump -uroot -padmin -d db02 student > D:/test.sql
导出某个数据库的建库、建表语句(不包含表数据):
mysqldump -uroot -padmin -d -B db02> D:/test.sql
导出当前数据库服务器的所有的建库、建表语句(不包含表数据):
mysqldump -uroot -padmin -d -A> D:/test.sql
数据还原
mysql命令恢复
准备数据,将其保存到D:/test.sql中:
use db02;
drop table if exists student;
CREATE TABLE `student` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
`math` int(11) DEFAULT NULL,
`english` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `student` VALUES (1,'小明',24,'男','湖北武汉',90,100),(2,'小红',25,'女','湖南长沙',88,69),(3,'小龙',26,'男','江西南昌',78,80),(4,'小丽',24,'女','安徽合肥',95,80),(5,'张三',19,'男','福建福州',80,90),(6,'李四',24,'男','广东广州',100,95),(7,'王五',24,'男','河南郑州',90,95);保存到文本中记得以GBK编码保存,因为windows窗口默认采用GBK编码导入数据;
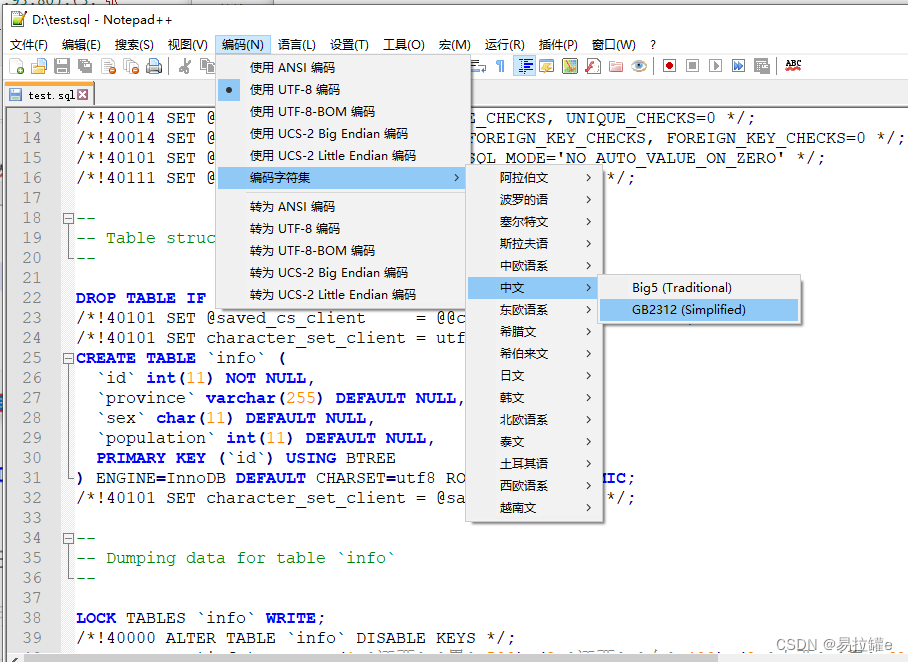
修改成GB2312编码后发现中文都变成了乱码:
没关系,这个时候再将没有乱码的内容复制到文件中即可;
执行数据导入命令(实质上就是把里面的sql执行一遍):
mysql -uroot -padmin < D:/test.sqlsource
source是属于mysql的命令,需要登录进mysql执行(实质也是把里面的sql执行一遍)。
source d:/test.sql;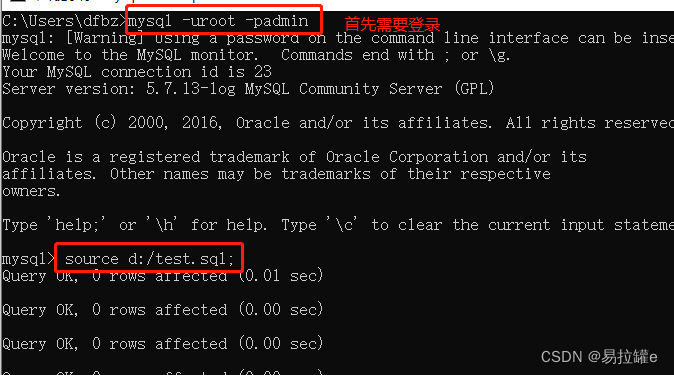
Tips:这两种类型的导入只适用于临时的数据导入(数据量不会太大),如果数据量大,导入速度会非常慢
数据库约束
数据库约束的概述
约束的作用:
一般在创建表的时候给表的字段添加各种约束,从而保证输入到表中的数据是正确的。保证数据的正确性,完整性和有效性。违反约束的数据是不能添加到表中去的。如果表已经存在,并且表中已经有数据,添加约束的时候如果表中的数据已经违反了现在要添加的约束,约束会添加失败。
约束种类:
| 约束名 | 约束关键字 |
|---|---|
| 主键 | primary key |
| 唯一 | unique |
| 默认 | default |
| 非空 | not null |
| 外键 | foreign key … references |
| 检查约束(mysql5.7不支持) | check |
主键约束
主键的作用
用来唯一标识表中的每一行记录,在创建表的时候,每张表都应该创建一个主键,每个表只能有一个主键约束。
主键的特点
1)非空:必须要有值
2)唯一:同一张表中不能出现重复数据
3)一张表最多只能有一个主键
主键列的选择
通常不建议使用与业务相关的字段做为主键,如:身份证、手机号等。往往会单独创建一个字段来做为主键,主键应该是没有含义。主键是给程序员编程使用的,不是给最终用户使用。
创建主键的方式
1)在创建表的时候添加主键:
字段名 字段类型 PRIMARY KEY
create table t1(
id int primary key, -- 指定id列为主键
city varchar(20)
);
insert into t1 values(1,'四川成都');
-- ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY' 违反主键约束
insert into t1 values(1,'浙江杭州');
2)在已有表中添加主键
ALTER TABLE 表名 ADD PRIMARY KEY(字段名);
alter table t1 add primary key(id);删除主键
-- 语法:
alter table 表名 drop primary key;
-- 删除t1表的主键约束
alter table t1 drop primary key;
-- 查看表详情
desc t1;
-- 给t1表的id列添加一个主键约束
alter table t1 add primary key (id);
-- 查看表详情
desc t1;主键自增
主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成主键字段的值,在最大值加1做为主键值。自增长必须是整数类型,而且必须是主键可以使用。
主键自增的语法:
字段名 字段类型 PRIMARY KEY AUTO_INCREMENT
create table t2(
id int primary key auto_increment, -- 主键并且自增
city varchar(20)
);
-- 查看表详情
desc t2;
-- 插入数据
-- 错误
insert into t2 values('黑龙江哈尔滨');
-- 执行几次
insert into t2 (city) values('云南昆明');
insert into t2 (city) values('甘肃兰州');
insert into t2 (city) values('青海西宁');
insert into t2 (city) values('山西太原');
insert into t2 (city) values('辽宁沈阳');
insert into t2 (city) values('内蒙古呼和浩特');
select * from t2;
修改主键自增的起始值
-- 将主键的起始值设置为100
alter table t2 auto_increment = 100;
insert into t2(city) values('山东济南');
-- 第二种写法
insert into t2 values(NULL,'吉林长春');
select * from t2;
联合主键
主键可以不只一个字段,如果有多个字段组成的主键,称为联合主键。
-- 示例
create table test(
id int,
id2 int,
city varchar(20),
primary key(id,id2) -- id和id2列组合为联合主键
);
insert into test values(1,1,'北京');
insert into test values(1,2,'天津');
insert into test values(1,1,'重庆'); -- 联合主键冲突唯一约束
概念:这一列的值不能重复
语法:
字段名 字段类型 UNIQUE
添加实现唯一约束
-- 创建学生表st3, 包含字段(id, name),name这一列设置唯一约束,不能出现同名的学生
create table t3 (
id int primary key auto_increment,
city varchar(20) unique
);
-- 添加一个同名的学生
insert into t3 (city) values('河北石家庄');
-- ERROR 1062 (23000): Duplicate entry '河北石家庄' for key 'city'
insert into t3 (city) values('河北石家庄');
desc t3;
select * from t3;非空约束
概念:这一列的值必须输入,不能为空
语法:
字段名 字段类型 NOT NULL
create table t4(
id int,
province varchar(30),
city varchar(20) not null -- 非空约束
);
insert into t4 values(1,'江苏','南京');
-- ERROR 1048 (23000): Column 'city' cannot be null city列不能为空
insert into t4 values(2,'江苏',null);
-- ERROR 1364 (HY000): Field 'city' doesn't have a default value city列没有默认值
insert into t4(id,province) values(2,'江苏');默认值
概念:如果某一列没有输入值,使用默认值。如果输入了,则使用输入的值。
语法:
字段名 字段类型 default 默认值
create table t5(
id int,
province varchar(20),
city varchar(20) default '乌鲁木齐' -- 如果该列没填,默认为乌鲁木齐
);
-- 如果填了以真实的值为准
insert into t5 values(1,'西藏','拉萨');
insert into t5 values(2,'新疆'); -- 报错,不能直接不填city列
-- 可以使用MySQL提供的default关键字
insert into t5 values(3,'新疆',default);
-- 没有填默认为'乌鲁木齐'
insert into t5(id,province) values(2,'新疆');
-- 查询表数据
select * from t5;检查约束
检查约束可以使用一定的范围条件来约束我们的列的值,例如年龄应该在0~120岁之间,性别只能有男或女等;
语法:
create table t6(
id int,
name varchar(30),
age int check(age>0 and age<120), -- 年龄只在0~120之间
sex char(1) check('男' or '女') -- 性别只能在'男' 和 '女'之间选择
);
-- 数据合格
insert into t6 values(null,'小明',20,'男');
-- 违反年龄的检查约束
insert into t6 values(null,'小黄',0,'男');
-- 违反年龄的检查约束
insert into t6 values(null,'小陈',150,'男');
-- 违反性别的检查约束
insert into t6 values(null,'小王',20,'啊');tips:在MySQL5.7版本不支持检查约束,我们了解即可;
MySQL官方文档:https://dev.mysql.com/doc/refman/5.7/en/create-table.html#create-table-indexes-keys
外键约束
单表的缺点
创建一个员工表包含如下列(id, name, age, dep_name,dep_location),id主键并自动增长,添加5条数据
CREATE TABLE employee (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(30),
age INT,
dept_name VARCHAR(30),
dept_location VARCHAR(30)
);
-- 添加数据
INSERT INTO employee (name, age, dept_name, dept_location) VALUES
('小明', 25,'研发部', '贵州贵阳');
INSERT INTO employee (name, age, dept_name, dept_location) VALUES
('小龙', 24,'研发部', '贵州贵阳');
INSERT INTO employee (name, age, dept_name, dept_location) VALUES
('小红', 20,'研发部', '贵州贵阳');
INSERT INTO employee (name, age, dept_name, dept_location) VALUES
('小兰', 26,'销售部', '宁夏银川');
INSERT INTO employee (name, age, dept_name, dept_location) VALUES
('小陈', 28,'销售部', '宁夏银川');
INSERT INTO employee (name, age, dept_name, dept_location) VALUES
('小赵', 18,'销售部', '宁夏银川');以上数据表的缺点:
-
大量冗余数据出现:研发部、销售部、地址等信息出现了多次
-
会出现删除异常,如果研发部一个人都没有那么研发部就不存在了
解决方案:
把这一张表拆分成两张表,一张表保存员工,另一张表保存部门。两个表之间通过一个外键建立联系。
-- 主表: 部门表
create table dept(
id int primary key auto_increment,
dept_name varchar(20),
dept_location varchar(20)
);
-- 添加部门信息
insert into dept (dept_name,dept_location) values ('研发部','贵州贵阳'),('销售部', '宁夏银川');
-- 如果存在就把这个表删除
drop table if exists employee;
-- 员工表
create table employee(
id int primary key auto_increment,
name varchar(20),
age int,
dept_id int -- 外键的数据类型与主表中的主键相同
);
-- 添加员工信息
INSERT INTO employee (name, age,dept_id) VALUES
('小明', 25,1),
('小龙', 24,1),
('小红', 20,1),
('小兰', 26,2),
('小陈', 28,2),
('小赵', 18,2); 当我们在employee的dept_id里面输入不存在的部门,数据依然可以添加,但是并没有对应的部门,实际应用中不能出现这种情况。employee的dept_id中的数据只能是dept表中存在的id
-- 插入3号部门的员工已经可以正常执行
INSERT INTO employee (name, age,dept_id) VALUES ('小黄',23,3);什么是外键约束
部门与员工之间是一对多的关系,一个部门对应多个员工,一个员工属于一个部门。部门是1方,员工是多方。
-
主表: 是一方,部门表
-
从表: 是多方,员工表
-
什么是外键:外键出现在从表中,被主表的主键约束的那一列外键

创建外键
新建表时增加外键-语法:
[CONSTRAINT `外键名`] FOREIGN KEY(外键字段) REFERENCES 主表(主键)
-- 删除员工表(从表)
drop table employee;
-- 创建员工表(id,name,age,dep_id)
create table employee(
id int primary key auto_increment,
name varchar(20),
age int,
dept_id int, -- 外键的数据类型与主表中的主键相同
CONSTRAINT `employee_ibfk_1` foreign key (dept_id) references dept(id) -- 本表的dept_id列依赖于dept表的id列
);
-- 添加员工信息
INSERT INTO employee (name, age,dept_id) VALUES
('小明', 25,1),
('小龙', 24,1),
('小红', 20,1),
('小兰', 26,2),
('小陈', 28,2),
('小赵', 18,2);
-- 违反外键约束
INSERT INTO employee (name, age,dept_id) VALUES ('小黄',23,3);
/*
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`db01`.`employee`, CONSTRAINT `employee_ibfk_1` FOREIGN KEY (`dept_id`) REFERENCES `dept` (`id`))
*/
-- 添加3号部门
insert into dept values(3,'行政部','陕西西安');
-- 再次添加员工并指定为三号部门
INSERT INTO employee (name, age,dept_id) VALUES ('小黄',23,3);
select * from employee;
select * from dept;已有表增加外键-语法:
# 新增:
ALTER TABLE 表名 ADD CONSTRAINT 约束名 FOREIGN KEY (外键字段) REFERENCES 主表(主键)
示例代码:
-- 添加约束
alter table employee add constraint employee_ibfk_1 foreign key(dept_id) references dept(id);
-- 查看表的建表语句
show create table employee;删除外键
语法:
ALTER TABLE 表名 DROP FOREIGN KEY 约束名;
alter table employee drop foreign key employee_ibfk_1;
-- 查看表的建表语句
show create table employee;外键的联级
测试数据:
-- 主表: 部门表
create table dept(
id int primary key auto_increment,
dept_name varchar(20),
dept_location varchar(20)
);
-- 添加部门信息
insert into dept (dept_name,dept_location) values ('研发部','贵州贵阳'),('销售部', '宁夏银川');
-- 如果存在就把这个表删除
drop table if exists employee;
-- 员工表
create table employee(
id int primary key auto_increment,
name varchar(20),
age int,
dept_id int, -- 外键的数据类型与主表中的主键相同
CONSTRAINT `employee_ibfk_1` FOREIGN KEY (`dept_id`) REFERENCES `dept` (`id`)
);
-- 添加员工信息
INSERT INTO employee (name, age,dept_id) VALUES
('小明', 25,1),
('小龙', 24,1),
('小红', 20,1),
('小兰', 26,2),
('小陈', 28,2),
('小赵', 18,2); 级联问题引入
出现新的问题:要把部门表中的id值2,改成20,能不能直接更新?
update dept set id=20 where id=2; -- ERROR 1451 (23000): Cannot delete or update a parent row当把部门的id修改为20后,原来为2号部门的员工怎么办?
要删除部门id等于1的部门, 能不能直接删除呢?
delete from dept where id=1; -- ERROR 1451 (23000): Cannot delete or update a parent row如果把id为1的部门删除后,原来在1号部门的员工怎么办?
当建立外键约束后,在修改和删除主表的主键时,从表必须设置一定的级联操作;如:随着主表修改而修改,或随着主表的删除而删除;默认情况下,建立外键约束后,MySQL不允许删除或修改主表的主键列;
级联的种类
-
删除级联:
-
on delete set null:如果主表有删除,那么从表的数据都为null -
on delete cascade:如果主表有删除,那么从表的数据也删除 -
on delete restrict:如果设置该值,主表不允许做删除操作(默认的外键行为) -
on delete no action:即如果存在从数据,不允许删除主数据(和restrict类似)。
-
-
修改级联:
-
on update set null:如果主表有更新,那么从表的数据都为null -
on update cascade:如果主表有更新,那么从表的数据也更新 -
on update restrict:如果设置该值,主表不允许做更新操作(默认的外键行为) -
on update no action:如果从表存在对应数据,不允许更新主表数据(和restrict类似)。
-
级联操作
-- 删除外键约束-- 删除外键约束
alter table employee drop FOREIGN KEY employee_ibfk_1;
-- 添加外键约束,级联更新和级联删除
alter table employee add constraint employee_ibfk_1 foreign key (dept_id) references dept(id) on update cascade on delete cascade;
select * from employee;
select * from dept;测试修改级联:
update dept set id=10 where id=1;
-- 把部门表中id等于1的部门改成id等于10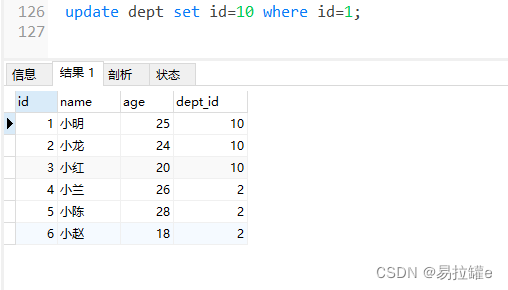
测试删除级联:
delete from dept where id=2; -- 删除部门号是2的部门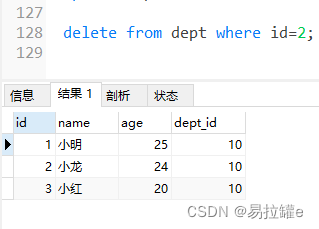
数据约束小结
| 约束名 | 关键字 | 说明 |
|---|---|---|
| 主键 | primary key | 唯一,非空 |
| 默认 | default | 没有输入值,使用默认值 |
| 非空 | not null | 必须输入 |
| 唯一 | unique | 不能重复 |
| 外键 | foregin key (外键) references 主表(主键) | 外键在从表 主表:1方 从表:多方 |


















 3342
3342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











