







Day4 - 上课练习题
一、监控日志分析
1.需求分析:找出每分钟超过100次访问的ip地址,将其加入黑名单

2.代码:
import time
point = 0
FILE_NAME = 'access.log'
while True:
ips = {}
f = open(FILE_NAME,encoding='utf-8')
f.seek(point)
if point == 0: # 判断是否为第一次读取
f.read() # 将指针移动到文件最后
else
for line in f:
line = line.strip()
if line:
ip = line.split()[0]
if ip in ips:
ips[ip] +=1
else:
ips[ip] = 1
point = f.tell()
f.close()
for ip,count in ips.items():
if count>=50:
print("加入黑名单的ip是 %s " % ip)
time.sleep(60)
二、变更文件内容的函数及调用
def op_file(filename,content=None):
with open(filename,'a+',encoding="utf-8") as f:
f.seek(0)
if content:
f.write(content)
else:
result = f.read()
return result
word = op_file("student2.json")
print(word)
[result~]:
{
"code": 0,
"msg": "操作成功",
"token": "xxxxx",
"addr": "10.101.1.1",
"phone": "182026"
}
三、判断是否为小数
使用的字符串方法:
s.count(’.’) 判断字符串中’.‘的个数
s.split(’.’) 将字符串s以’.‘进行分割
s.isdigit() 判断s是否是一个数字
s.startwith(’-’) 判断字符串s是否以‘-’开头
s.strip() 去除s字符串的左右空格符
def is_float(s):
s = str(s)
if s.count('.') == 1:
left,right = s.split('.')
if left.isdigit() and right.isdigit():
return True
elif left.startswith('-') and left.count('-')==1 and left[1:].isdigit() and right.isdigit():
return True
else:
return False
else:
print(s.count('.'))
return False
price = input("请输入价格:".strip())
#result = is_float(price)
if is_float(price):
print("这是个小数")
else:
print("这不是个小数")
四、创建一个replace功能的函数
使用split()和join()方法
list.split(‘字符串’)
‘字符串’.join(stu_list)
a="123acdd123bdbsadcd123bcdvfasd123"
def replace(src,old,new):
if old in src:
return new.join(src.split(old))
return src
print(replace(a,'123',"你好"))
[result~]:
你好acdd你好bdbsadcd你好bcdvfasd你好
五、Redis迁移练习

import redis
r = redis.Redis(host="localhost", password="123456", port=6379, db=4,decode_responses=True)
r2 = redis.Redis(host="localhost", password="123456", port=6379, db=11,decode_responses=True)
for k in r.keys():
k_type = r.type(k)
if k_type == "string":
value = r.get(k)
r2.set(k,value)
elif k_type == "hash":
dic = r.hgetall(k)
r2.hmset(k,dic)
elif k_type == "list":
length = r.llen(k)
result = r.lrange(k,0,length-1)
r2.rpush(k,*result)
六、测试环境搭建
1.第一次搭建
安装依赖软件:java、mysql、redis、mq、kafka 版本信息
2.获取代码 get 分支
3.导入基础数据(建表、导入数据)
4.修改配置文件
5.编译、打包(java需要编译,go、python、php不需要编译)
6.重启
日常部署:
1.根据提测单下载代码、更新表
七、面试题
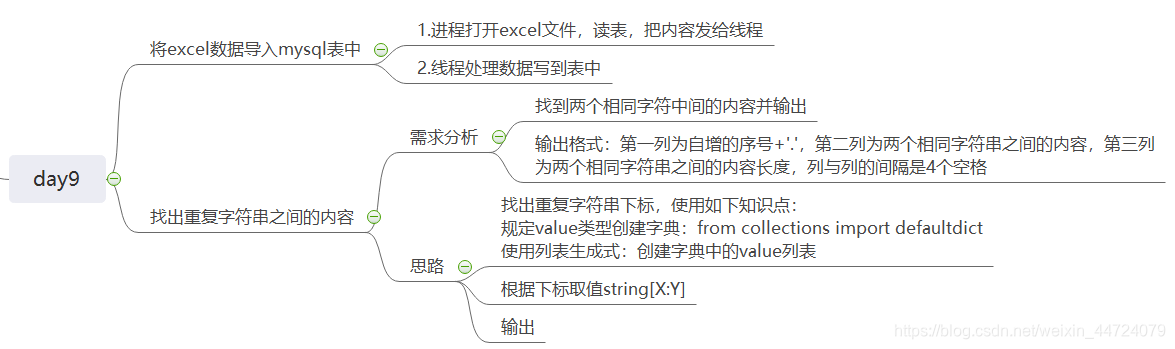
from collections import defaultdict # defaultdict也是一个字典,如果指定类型为int,则没指定值得key默认值为0
# 上课代码
# def find_str(string):
# # for s in string:
# # if string.count(s) > 1:
# # string.find(s)
# #string = 'abcsdgsf1s23f'
# str_index_map = defaultdict(list) # {s:[3,6],f:[9,12,13]}
# # for index,s in enumerate(string):
# # if string.count(s)>1:
# # print("index:%s,string:%s" % (index,s))
# # str_index_map[s].append(index)
# [str_index_map[s].append(index) for index,s in enumerate(string) if string.count(s) > 1]
# for index_list in str_index_map.values():
# start_index,end_index = index_list
# print(string[start_index:end_index+1])
# 复习代码
def find_str(string):
# 第一种方法:生成key为字符,value为相同字符的下标所组成的列表
# str_index = {}
# for index,s in enumerate(string):
# if string.count(s) > 1:
# # print("index:%s,string:%s" % (index,s))
# if s in str_index:
# str_index[s].append(index)
# else:
# str_index[s] = [index]
# print(str_index)
# defaultdict也是一个字典,需要指定value类型,如果类型为int,则没指定值得key默认值为0
# 第二种方法:使用defaultdict方法,生成key为字符,value为相同字符的下标所组成的列表
# str_index = defaultdict(list)
# for index,s in enumerate(string):
# if string.count(s) >1:
# str_index[s].append(index)
# 第三种方法:使用defaultdict方法,生成key为字符,value为相同字符的下标所组成的列表(列表采用列表生成式方法生成)
str_index_map = defaultdict(list)
[str_index_map[s].append(index) for index,s in enumerate(string) if string.count(s) > 1]
# print(str_index_map)
# 如果字符串中相同的字符只出现两次时,可以用如下方式进行输出
# for index1,index_list in enumerate(str_index_map.values(),1):
# start_index,end_index = index_list #如果list中只有两个元素,可以直接用解包的方式输出开始值和结尾值
# target_str = string[start_index:end_index+1]
# target_str_len = len(target_str) - 2
# print("%s. %s %s" % (index1,target_str,target_str_len))
# 如果字符串中相同的字符出现超过两次,需要变更输出代码
count = 1
for index_list in str_index_map.values():
for index in range(len(index_list) - 1):
start_index = index_list[index]
end_index = index_list[index+1]
target_str = string[start_index:end_index+1]
target_str_len = len(target_str) -2
print("%s. %s %s" % (count,target_str,target_str_len))
count += 1
if __name__ == '__main__':
s = 'abcsdgsf12s3df'
find_str(s)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









