






1、常用函数_dataframe
#######################################################################################################################
#######################################################################################################################
# 设计函数
例:
import pandas as pd
## 站外购买次数_每日
def offsite_buy_num(start_time, end_time, partnerid)
:
sql = """
SELECT appId `城市`,left(buyDate,10) `日期`,COUNT(deviceUserId) `购买次数`
FROM qyq_TicketSell
WHERE buyDate>='%s'
""" % (start_time, end_time, partnerid)
print(sql)
offsite_buy_num = pd.read_sql(sql, partner_conn)
return offsite_buy_num
# 函数返回值问题
def return_problem():
a = [0,1,2]
b=2
c=4
return a,b,c
aa = return_problem()
print(aa)
print(aa[0])
print(aa[1])
print(aa[2])
# 函数默认参数-调用问题
def getMailFile(email_name, file_name,
username=lbj_username, password=lbj_password, floder_input=floder
):
函数getMailFile
:username、password、floder_input,包含默认参数
调用:
file_path = getMailFile(email_name, file_name,
floder_input=floder_input1
)
调度
:若,username、password用默认参数,floder_input用调用的参数:floder_input=floder_input1
py调用mysql脚本like
args =
'%'+subtitle+'%'
#
先把需要查的字符串抽出来,再以参数方式传入
sqlquerytitle="select count(*) from tbl_peng_article where title like '%s'"%args
#######################################################################################################################
#######################################################################################################################
# 列操作
# 获取列
df1= df[['键', '日期', '展现次数', '点击次数']]
# 改列名,烈改名
df.rename(columns={'键': 'adId'}
, inplace=True)
或 circle_df = circle_df.rename(columns={'partnerId': 'id'})
批量:
df =
df.rename(columns={"Q1":"a", "Q2": "b"}) # 对表头进行修改
inplace参数的理解
:
inplace=True:不创建新的对象,直接对原始对象进行修改
# 最后一列改名,不同位置列改名
# 获取最后一列的列名
last_column_name =
pf.columns[-1]
# 修改列名
new_column_name = '其他'
pf.
rename(columns={last_column_name: new_column_name}, inplace=True)
# 改列顺序
## 整体
改顺序
letters= ['第1_2轮_点击率1', '第1_3轮_点击率', '第1_3轮_增长幅度']
df= df[letters]
# 插入列
改位置
# 先
删除
列然后
插入列
到指定位置(单独改顺序) 换位置
df_id = df['单位金币消耗']
df= df.drop('单位金币消耗', axis=1)
df.insert(5, '单位金币消耗',df_id)
# 先
删除
列然后
插入列
到指定位置-简单方式
df1= df_total.
pop('admin') # 先将需要移动的列pop出来为一个Series
df_total.insert(12, 'admin',df1) # 再将pop出来的列,添加到指定的位置,第一个参数是第几列的位置,第二个参数为列名,第三个参数为series
# 删除列
sheet2 = sheet2.drop(['userId1', 'userId2', 'userId3'], axis=1)
# 条件删除列
# 取出行=0的列,取出列,取出列名
df1= df.loc[:,
(df.loc[30, :]==0)].columns.values.tolist()
print(df1)
# 删除列
df= df.drop(
df_name, axis=1)
print(df)
# 新增列
#
主表 增加一列
:第2轮增长幅度
df['第3轮-增长幅度'] =(df['第3轮-点击率'] - df['第2轮-点击率']) / df['第2轮-点击率']
#
新增一列
:
长度
(没有的列),必须限制格式为str
df['标题长度'] = df.标题.str.len()
df1['len'] = df1.字段.str.len()
# 多列拼接 一个表中两列字符连接
clip_date['预警指标'] = clip_date['栏目名称'] + clip_date['预警指标']
注:前提数据类型相同
# 取出列中数据
现用
df1= df[(df['城市'] == 965004)]
# 列限制
clipIcon_click = clipIcon_click[
clipIcon_click['栏目名称'] != 0]
# 列限制-或关系
df1 = df1[
(df1['len'] > 5)
|
(df1['血缘上层库']=='tmp')
]
#
列值
df_values
= df.loc[:, '状态']
.values
if df_values==6:
print('列值')
# 列值:去除列表
print(df1['8小时-分钟'].values)
结果: [480]
print(df1['8小时-分钟'].values[0])
需求:480
# 行列转置
## 索引一项
click_rate_data_0911 = click_rate_data_0911.
pivot_table(index='键', columns='日期', values='点击率').sort_index(axis=1, ascending = False)
# 按首行降序
## 索引两项
AllPay_click_rate_Transpose = AllPay_click_rate_Transpose.
pivot_table(index=['键', '竞价类型'], columns='日期', values='点击单价').sort_index(axis=1, ascending=False)
# 索引前加 %
click_rate_data_0911 = click_rate_data_0911.applymap(lambda x: '%.2f%%' % (x*100))
# # 索引转换为列,
读取索引
# click_rate_data_0911 = click_rate_data_0911.
reset_index()
# 删除索引类型格式
cost_appiddaily.
reset_index(
drop=
True, inplace=True)
# 转置
# 修改其他列为索引
three_Template.
set_index('dt', inplace=True)
# 转置
three_Template = three_Template.T
print(three_Template)
# 索引转换为列,读取索引
three_Template = three_Template.
reset_index()
# 删除索引类型格式
three_Template.reset_index(drop=True, inplace=True)
print(three_Template)
# 索引改名
three_Template.rename(columns={'index': '统计指标'}, inplace=True)
print(three_Template)
# 加序号列-索引排序重置
df1 = df[['序号', '城市名称']].drop_duplicates()
df1 = df1.sort_values(['序号'], ascending=[True])
df1 = df1.drop(['序号'], axis=1)
# 索引转换为列,读取索引,删除排序后的不规则 序号
df1=df1.reset_index()
df1=df1.drop(['index'], axis=1)
# 索引转换为列,读取索引
df1=df1.reset_index()
# 删除索引类型格式
df1.reset_index(drop=True, inplace=True)
# 改名
df1.rename(columns={'index': '序号'}, inplace=True)
print(df1)
# 列转行:设置成索引,直接转集合tuple
.set_index() : 修改其他列为索引
show_contrib_adid.set_index('键', inplace=True)
print('列转行')
# 转成集合
show_contrib_adid = str(tuple(show_contrib_adid.index))
print('转成集合')
例:
# 取出以上的 userid
itemid_name_1 = itemid_name[['userid']]
car_host_userid = car_host_userid.drop_duplicates()
# 列转行:
修改其他列为索引
itemid_name_1.set_index('userid', inplace=True)
print('列转行')
print(itemid_name_1)
#
转成元组
itemid_name_1 = str(
tuple
(itemid_name_1.index))
print('
转成元组
')
print(itemid_name_1)
# 可能用到
# 表头
转成列表
clip_view_58_lastDate_id = str(
list
(clip_view_58_lastDate_id.index))
print('转成 列表')
print(clip_view_58_lastDate_id)
# 去除列表外的 ""
clip_view_58_lastDate_id=
eval
(clip_view_58_lastDate_id)
print([clip_view_58_lastDate_id])
# 列转行—2
str(tuple(
chain.from_iterable(df.values)))
chain.from_iterable表示把列中数据迭代展示为 ['', '', '', '']格式
# 去重
# drop_duplicates函数
primary_data_0821_1 = click_data_0821_1[['键', '竞价类型']]
primary_data_0821_1 = primary_data_0821_1.drop_duplicates(['键', '竞价类型'])
遍历索引
circle_df.iterrows()
# 索引
转列表-取出索引
idx = df2
.index.
tolist
()
# 索引
转集合-取出索引
df_id= str(
tuple(df.index))
# 获取第一行,列名称,
取出列名(判断-列是否存在)
# 获取最后一列 列名
df= df.
columns.
values.
tolist()
df= df[-1]
print(df)
或:
df= pf.columns[-1]
# 按上述,列名称,排序
pf=pf.
sort_values(by=
df, axis=0, ascending=False)
# 相同的列名改名,相同列后面加 .1 .2 .3 ...
cols =
pd.Series(
All_Pay.columns)
for dup in cols[cols.duplicated()].unique():
cols[cols[cols == dup].index.values.tolist()] = [dup + '.' + str(i) if i != 0 else dup for i in range(sum(cols == dup))]
All_Pay.columns = cols
#######################################################################################################################
#######################################################################################################################
# 索引
.set_index() : 修改其他列为索引
show_contrib_adid.
set_index('键', inplace=True)
# 日期设成索引
df_data.
reset_index=df_data['日期']
public_chuda.
set_index('日期', inplace=True)
# 索引
转列表
idx = df2.index.tolist()
# 读取索引,并改名
circle_df = circle_df.
reset_index()
circle_df.
rename(columns={'index': '序号'}, inplace=True)
# 对索引名进行修改
s.rename_axis("animal")
df.rename_axis("animal") # 默认是列索引
df.rename_axis("limbs",axis="columns") # 指定行索引
# 删除索引类型格式
如果我们想删除 index 列,我们可以在 reset_index() 方法中设置 drop=True。
cost_appiddaily.
reset_index(drop=True, inplace=True)
print(cost_appiddaily)
# 查询最大索引的值
df.Q1[lambdas: max(s.index)] # 值为21
# 计算最大值
max(df.Q1.index)
# 99
df.Q1[df.index==99]
#######################################################################################################################
#######################################################################################################################
# group by 分组
# 列
分组前10
# 排序,按第一列组外升序,第二列组内降序
read_push_userstartup = read_push_userstartup.
sort_values(['日期', '拉活人数'], ascending=[True, False])
print(read_push_userstartup)
# 分组前10
read_push_userstartup = read_push_userstartup.
groupby(['日期', '城市id'])
.head(10)
print(read_push_userstartup)
# 后6
a.tail(6)
【列汇总 分组汇总】
df_click = df.groupby(["城市id", "栏目id", "日期"])["用户id"].
nunique()
.reset_index(name='点击人数')
print(df_click)
df_sum= df.groupby(["城市id", "栏目id", "日期"])["点击次数"].
sum()
.reset_index(name='点击次数')
print(
df_sum
)
df_deliveryNum = df_delivery.groupby(["date", "partner_id"])["
用户id
"].
count()
.reset_index(
name='deliveryNum')
df_middle = df1.groupby(["血缘上层表"])["血缘上层库"].
max()
.reset_index(name='血缘上层库max')
nunique()
统计dataframe中每列的不同值的个数,也可用于series,但不能用于list,返回的是不同值的个数
# 所有汇总
df.loc['合计'] = df[["全部", "1小时内", "1-2小时", "2-3小时", "3-4小时", "4-5小时", "5小时以上"]].
sum
(axis=0)
# agg聚合
# 每列的最大值
df.agg('max')
# 将所有列聚合产生sum和min两行
df.agg(['sum', 'min'])
# 序列多个聚合
df.agg({'Q1' : ['sum', 'min'], 'Q2' : ['min','max']})
# 分组后聚合
df.groupby('team').agg('max')
df.Q1.agg(['sum', 'mean'])
# 条件 均值
# 第70行 添加均值(整体)
.mean(axis=0)
dau_appid_all2.loc[70] = round(dau_appid_all2[
(dau_appid_all1['日期']>='2021-08-01') & (dau_appid_all1['日期']<='2021-09-01')
]
.mean(axis=0)
, 0)
dau_appid_all2
.loc[70, '日期']
= '前1个30日均值'
【分组排序】
#创建数据集
df = pd.DataFrame({'A':[12,20,12,5,18,11,18],
'C':['A','B','A','B','B','A','A'],
'B':['d','d','e','d','e','e','d']})
#实现row_number()
df['
row_number
'] = df.
groupby
(['C','B'])['A'].
rank
(ascending=True,method='first')
例如:
# 分组排序
clip_top5_data_all['
row_number
'] = clip_top5_data_all.
groupby
(['圈类型', '周','周活跃天数'])['对应用户数'].
rank
(ascending=False,
method='first'
)
# 取出条件列
clip_top5_data_all = clip_top5_data_all[(clip_top5_data_all["row_number"] <= 5)]
print(clip_top5_data_all)
method 注释
rank(method=‘first’)
这个函数其中传入了一个参数‘first’,作用是按照值在数据中出现的次序分配排名。
rank(method = ‘max’)
这里method的参数变为了 max,意味着对整个组使用最大排名。
rank(method = ‘min’)
min 的意思为对整个组使用最小排名。
dataframe_【group分组聚合】-其他列字段-逗号分隔
类似:mysql:GROUP_CONCAT
# 前置:转字符型
# 将定时列的NaN值替换为空字符串
df['主流程'] =df['主流程'].fillna('')
# 将定时列的值转换为字符串
df['主流程'] =df['主流程'].astype(str)
# 按 工作流名称-列 进行分组,并将 主流程-列 数据,合并为逗号分隔的字符串
df1=df.groupby('工作流名称')['主流程'].
apply(lambda x: ', '.join(x)).reset_index()
#######################################################################################################################
#######################################################################################################################
列新增(条件列新增、多
条件列新增
)where
np.where
# 数值大于70
df.where(df > 70)
import numpy as np
df= df[(df['省份'] == '河南')]
df['授权率异常'] =
np.where(df["授权率(授权人数/小区户数)"] < 0.08, '授权率低于8%', 0)
# 多次嵌套
df['刷脸占比异常'] =
np.where(df["刷脸占比(刷脸人数/授权人数)"] == 0, '无人刷脸',
np.where(df["刷脸占比(刷脸人数/授权人数)"] < 0.1, '刷脸占比低于10%',0))
# 条件替换-数值替换
精度问题:需要转数据类型,然后限制精度
pf['其他支出_中间处理'] = np.where(pf['结算状态']=='已结算', pf['订单总价']-pf['商家结算']-pf['交易手续费']-pf['技术服务费'], 0)
pf['其他支出_中间处理'] = pf['其他支出_中间处理'].apply(float)
pf['其他支出_中间处理'] = pf['其他支出_中间处理'].round(2)
~np.isnan:控制不为空值
df['参培状态'] = np.where((
~np.isnan(df["入职日期"])) & (df["入职日期"]<='%s'), '已入职', df['参培状态']) % (dt)
#######################################################################################################################
#######################################################################################################################
# 行操作
# 删除首行
three_Template_click.drop(
index=0, inplace=True)
# 删除指定行
删除行
df=df[
-
df.渠道.isin(['站外浏览'])]
print(df)
# 两行
df=df[-df.日期.isin(['上5日', '上上周'])]
print(df)
# 多行
df=[ '简网4C-1', '简网6-6', '简网3B-4' ]
df1=df
[~
(df["所属提货点"].isin(not_janwang))]
# dataframe 删除最后两行
# 即:取倒数2行,以前的
pf = pf.iloc[:-2]
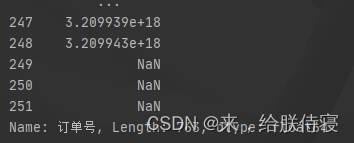
# 删除带空值行,删除空值行:
dropna()
print(data.dropna()) ### 默认axis=0,how='any',删除带有空值的行,只要有一个空值,就删除整行
例:
pf = pf.dropna(subset=['订单号'])
存在NaN:空值行删除

# 新增行 读取行 # 先行后列
# 重设索引
qilin_allappid.set_index('日期', inplace=True)
# 日增量
loc
qilin_allappid.
loc['日增量'] = qilin_allappid.
loc['2021-04-15']-qilin_allappid.
loc['2021-04-14']
或
qilin_allappid.
loc['合计',
['总小区数', '已上线小区']] = qilin_allappid.
loc['2021-04-15', ['总小区数', '已上线小区']] -qilin_allappid.
loc['2021-04-14', ['总小区数', '已上线小区']]
# 日增量
iloc
qilin_allappid.loc['日增量'] = qilin_allappid.
iloc[-1]-qilin_allappid.
iloc[-2]
# 获取索引列,
获取首行,行名
print(df1.columns.values.
tolist())
print(df1.columns.values.
tolist()[i])
:i表示:第几个位置,
i=0开始
实例:
# 第70行 添加
均值
(整体)
dau_appid_all2.loc[70] = round(dau_appid_all2[(dau_appid_all1['日期']>='2021-08-01') & (dau_appid_all1['日期']<='2021-09-01')]
.mean(axis=0)
, 0)
dau_appid_all2
.loc[70, '日期']
= '前1个30日均值'
行加%
public_chuda.loc['服务号日取关率',:] = public_chuda.loc['服务号日取关率',:]
.apply(lambda x: '%.2f%%' % (x*100))
#######################################################################################################################
#######################################################################################################################
iloc-loc(先行后列)
# 最后1列
# 获取到 最后一列 的值 (不限制类型str, int)
app_arearetention_add['上周'] = app_arearetention_add.
iloc[:,-1]
# 获取
到
第5列的值
app_arearetention_add['上上周'] = app_arearetention_add
.iloc[:,4]
print(app_arearetention_add)
# 条件取出
# 取出行=0的列,取出列
df_name =df.loc[ : ,
(df.loc[30, : ]==0)].
columns.values.tolist()
#
列值
df_values
= df.loc[:, '状态']
.values
if df_values==6:
print('列值')
# 列值:去除列表
print(df1['8小时-分钟'].values)
结果: [480]
print(df1['8小时-分钟'].values[0])
需求:480
# 条件行填充、条件列填充
main_df.loc[
(main_df['投放渠道'].isin(["click"])),
"备注"] = "一类-企微活码回传"
# 取出
dataframe
字段之前的数据:[0]
df1['血缘上层库'] = df1.iloc[:, -1].map(lambda x: x.split('.')[0])
df1['血缘上层表'] = df1.iloc[:, -2].map(lambda x: x.split('.')[1])
[1]:表示,取到 第2个字段 之前的数据
邮件正文 取前14列 后14行 前10行
# 取前14列 后14行
前10行
key_appid_commentnum_1 = key_appid_commentnum
.iloc[:, 0:14].
tail(14)
.head(10)
loc函数学习
#######################################################################################################################
#######################################################################################################################
# 表关联
merge
# #
关联
主表,连接表
# df= pd.merge(df1, df2, how='left', on=['键'])
##关联表 on on=['键', '类型']
# df= pd.merge(df1,df2, how='left', on=['键', '类型'])
merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'))
suffixes=('_x', '_y'),
•suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称
,默认为('_x','_y')
merge(data,data1,on="name",how="left",suffixes=('_a','_b'))
# 前1个不变,后一个加后缀
cost_appidWeek_all = pd.merge(cost_appidWeek1, cost_Activity1, how='left', on=['序号', '城市id', '城市名称'],
suffixes=('', '_发帖'))
# 名字不同连接键
merge(data,data3,left_on=["name","id"],right_on=["mname","mid"])
#当日发过消息且当日访问过新版相亲交友的用户
msg_view_xq = pd.merge(msg_1, view_xq, how='inner',
left_on=['dt','fromuserid'],
right_on=['dt','userid'])
concat 合并表
bid_all_data = pd.concat([bid_pay_data, bid_free_data], axis=0, ignore_index=True)
默认情况下,axis=0可以不写 纵向
ignore_index=True
如果遇到两张表的列字段本来就不一样,但又想将两个表合并,其中无效的值用nan来表示。那么可以使用ignore_index来实现
#######################################################################################################################
#######################################################################################################################
#
pysqldf 用SQL操作Python中的缓存数据
from pandasql import sqldf
# globals() 声明全局变量(一次性)
pysqldf = lambda a: sqldf(a, globals())
a = """
select `键`,(sum(点击次数)/sum(展现次数)) `第3轮-点击率`,round(avg(展现次数),0) `展现次数`,round(avg(点击次数),0) `点击次数`
from Show_click_0911
where `日期` > '09-11'
group by `键`
"""
Show_click_new_0911 = pysqldf(a)
print(Show_click_new_0911)
另一种方式:
lj_xqsf = sqldf('''
select dt,sum(uvnum) `累计认证相亲身份uv`
from xqsf_huizong
where dts >= '%s'
and dts <= '%s'
group by dt'''%(startDatest,endDate1st)
)
# py 除法-保留位数问题
#
更改数据类型—使用缓存时必须要改数据类型
【cast(~~ as float)函数】
例:
(cast(sum(点击次数_上周) AS float)/cast(sum(展现次数_上周) AS float))
#######################################################################################################################
#######################################################################################################################
# 读取Excel,导入Excel:pd.DataFrame(Python,xshell服务器)
#
导入Excel文件
# df1= pd.DataFrame(
pd.read_excel
(r"C:\Users\Administrator\Desktop\朱钇杰文件\第3轮优化64个样本_最终版_0911.xlsx", sheet_name='第3轮优化')
, dtype=object
)
#
导入上传的Excel文件
df2
= pd.DataFrame(
pd.read_excel
(r"/root/data-department/wenzilong/data/广告优化_第1轮_9.22上线-补充.xlsx", sheet_name='优化广告')
, dtype=object
)
# dtype = object,详解
将每个单元格的内容作为Python对象存储,
保持原始的数据类型和格式
。
(
使用pd.read_excel函数读取Excel文件时,Pandas会尝试自动检测列的数据类型。有时候,
它可能会将某些数据类型,错误地解释为浮点数,或其他类型
,从而导致数据的精度丢失
)
# 读取excel到dataFrame
pf = pd.read_excel(
io=file_path,
sheet_name=0,
dtype={'your_column_name': str},
skiprows=2,
)
#
sheet_name详解
整数值:
使用整数索引(从0开始)来指定要读取的工作表。例如,sheet_name=0表示读取第一个工作表,
sheet_name=2表示第2个工作表
字符串值:
使用工作表的名称作为字符串来指定要读取的工作表。例如,sheet_name="Sheet1"表示读取名为"Sheet1"的工作表
不指定sheet_name参数:
默认情况下,pd.read_excel将读取Excel文件的第1个工作表
sheet_name=None:
返回一个字典,
键是Sheet的名称,值是对应的数据框(DataFrame)对象
# dtype={'your_column_name': str},详解
当使用pd.read_excel函数读取Excel文件时,Pandas会尝试自动检测列的数据类型。有时候,它可能会将某些数据类型错误地解释为浮点数或其他类型,从而导致数据的精度丢失。
为了解决这个问题,
可以使用dtype参数来指定列的数据类型,确保读取的数据保持为字符型
# skiprows=2,详解
skiprows=2:
跳过前两行
,从第三行开始读取数据
skiprows=0:不跳过任何行,从第一行开始读取数据
# 读取单列:usecols='X'
wf_middle = pd.read_excel(io=to_path, sheet_name='考勤统计',
usecols='X'
)
# 打开excel,获取sheet_names列表
excel_file = pd.ExcelFile(file_path)
sheet_names = excel_file.sheet_names
# 实例:判断-变化的Sheet名称
path3 = 'd:\ETL\费边店铺3月账单明细\商户号费边.xlsx'
# 读取Excel文件-名称
dict_pf1 =
pd.ExcelFile(path3)
# 获取所有Sheet名称
sheet_names =
dict_pf1.sheet_names
>>
['Sheet1', '1608185580All2023-04-27_2023-05']
# 判断-变化的Sheet名称
for sheet_name in sheet_names:
if '1608185580All' in sheet_name:
print(sheet_name)
pf1 = pd.read_excel(
io=path3,
sheet_name=
sheet_name,
dtype=object,
)
通过Pandas导入CSV文件
text1 = pd.DataFrame(
pd.read_csv
(r"D:\数据\运营\数据\日活下降原因\8.18-8.19未发推送用户回执明细.csv"))
读取csv到dataFrame
参数含义网址:
pd.read_csv参数详解_愚末语的博客-优快云博客
pf = pd.read_csv(
filepath_or_buffer=file_path,
# 文件地址
sep=',',
# 指定分隔符。如果不指定参数,则会尝试使用逗号分隔
encoding="gb18030",
# 指定字符集类型,通常指定为 'utf-8'
header=0, # 设置第一行为表头
# skiprows=[1], # 跳过excel表中的第2行
# names=names_of_cols,
# 用于结果的列名列表,如果数据文件中没有列标题行,就需要执行header=None。
# usecols=use_cols,
#用usecols='A:BL', 返回一个数据子集,该列表中的值必须可以对应到文件中的位置。使用这个参数可以加快加载速度并降低内存消耗
low_memory=False,
# 分块加载到内存,再低内存消耗中解析。但是可能出现类型混淆。确保类型不被混淆需要设置为False。
skipinitialspace=True,
# 忽略分隔符后的空白(默认为False,即不忽略)
index_col=False, # 如果文件不规则,行尾有分隔符,则可以设定index_col=False
thousands=',', # 去除千分位字符
)
注:编码-乱码-问题时,'gbk','utf-8','gb18030','ansi',方式替换试下
dataFrame数据去除千分字符、千分位分隔符
方法一:表格读取的文件,直接参数修改:加 thousands=','
df = pd.read_excel('file_name.xlsx',
thousands=','
)
方法二:个别列的数据修改
df['colname'] = df['colname'].str.replace(',', '').astype(float)
方法三:通篇列的数据修改,APPLYMAP()函数的应用
df = df.applymap(lambda x: x.replace(',', ''))
DataFrame
存入excel
df.to_excel('D:/lmdesktop/相亲交友监控数据2931all.xlsx',index=False)
DataFrame
存入csv
df1.to_csv('D:/lmdesktop/df1.csv',index = 0)
excel
保存
from openpyxl import Workbook
#
文件名称
flodername = floder + send_mailname + '.xlsx'
print(flodername)
# 创建文件路径
mkdir(path=floder)
# 保存空文件夹excel
,
创建一个全新的excel
Workbookwb = Workbook()
# 将创建的Workbook进行保存,命名为“
flodername
”
Workbookwb.save(flodername)
print('保存空文件夹excel')
#######################################################################################################################
#######################################################################################################################
# 数据类型转换-修改数据类型
网址:
滑动验证页面

# 查看数据类型
DataFrame:使用dtypes查看数据类型
print(df.
dtypes)
直接type查看数据类型
print(
type(obj))
# 统一类型
pf['键'] =pf['键'].
apply(str)
# 所有 转字符型
pf= pf.
applymap(str)
# 部分列-数据格式转换
list_double = ['应结订单金额','代金券金额','退款金额','充值券退款金额','手续费','订单金额','申请退款金额']
pf[list_double] = pf[list_double].applymap(float)
# 行转float型
keymonth_appid_remain1.iloc[-1, :] = keymonth_appid_remain1.iloc[-1, :].
apply(float)
keymonth_appid_remain1.iloc[-2, :] = keymonth_appid_remain1.iloc[-2, :].apply(float)
注:
float
:浮点数,
浮点数在 Python 中对应于
双精度
数据类型
强制更改数据类型:astype
data['客户编号'] = data['客户编号'].
astype
('object')
循环强制转换
pf_type:跑mysql取出的字段数据类型
n=0
while n<=
pf.shape[1]-1:
#列数
pf[
pf_type.iloc[n,0]
] = pf[
pf_type.iloc[n,0]
].astype(
name_types
(
pf_type.iloc[n,-1]
), errors='ignore')
-->pf_type.iloc[n,0]='字段列名'='
子订单号
'
pf_type.iloc[n,-1]='字段原来的格式'='
int64
'
按数据类型查询
df.
select_dtypes(include=['float64']) # 选择float64型数据
df.select_dtypes(include='bool')
df.select_dtypes(include=['number']) # 只取数字型
df.select_dtypes(exclude=['int']) # 排除int类型
df.select_dtypes(exclude=['datetime64'])
# 自动转换合适的数据类型
df.infer_objects() # 推断后的DataFrame
df.infer_objects().dtypes
内置函数转换-
时间
# 转成数字
pd.
to_numeric
(pf['所属组'], errors='coerce').fillna(0):
未转换置空
# 转成时间(
datetime数据类型转换
)
pd.
to_datetime
(pf[['day', 'month', 'year']]
, format='%H:%M:%S'
)
例:
pf['交易时间'] = pd.
to_datetime
(pf['交易时间'])
# 转成时间差
pd.
to_timedelta
(m)
to_numeric():内置函数,直接转换int型,转成数字类型
pandas.
to_numeric
(
arg
,
errors
='raise',
downcast
=None)
arg:
需要更改的单列或Series对象
。
errors:遇到无法转换为数字的类型时的处理方式。
方式如下:
raise:遇到无法解析的类型,直接报错
coerce:遇到无法解析的类型,将其内容设置为NaN
ignore:遇到无法解析的类型,将其保持原来的内容不变
downcast:
默认是float64或int64类型。如果指定了类型,那么数据在转换时,就转换为指定的类型。
integer或signed:dtype里最小的数据类型:np.int8
unsigned:dtype里最小的无符号数据类型:np.uint8
float:最小的float型:np.float32
例:
转换类型填充
pd.to_numeric(data['所属组'], errors='coerce').fillna(0)
to_sql内部函数转换
见插入章to_sql
#######################################################################################################################
#######################################################################################################################
# 排序
## 索引降序
df.
sort_index(axis=1) #按 首行 升序排序
df.
sort_index(axis=0) #按 首列 升序排序
## 值降序
All_Pay.
sort_values('千次展现消耗贡献度',
ascending=False)
例:
付费主表点击率降序
bid_pay_data.
sort_values(['点击率'], ascending=False)
升序 : ascending=True (默认)
interact_Week_last = interact_Week_last.
sort_values(['dataDptSort'], ascending=True)
排序要设定覆盖,否则不成功
# 排序,结果显示为,
先按日期排序,后按序号排序-升序
interact_daily_2 = interact_daily_2.sort_values(['序号', '日期'], ascending=True
)
.head(10)
.
head(10),前10项
## 排序,按第一列组外升序,第二列组内降序
view_entry_data = view_entry_data.sort_values(['序号', '浏览入口次数'], ascending=[True, False])
print('排序')
先按序号升序,再在同一个序号里 按 浏览入口次数 降序
注:排序失败 原因序列里有null值
# 方向
axis:{0 or ‘index’, 1 or ‘columns’}, default 0
默认按照列排序,即纵向排序;如果为1,则是横向排序。
1表示横轴,方向从左到右;
0表示纵轴,方向从上到下。
当axis=1时,数组的变化是横向的,而体现出来的是列的增加或者减少。
其实axis的重点在于方向,而不是行和列。具体到各种用法而言也是如此。当axis=1时,如果是求平均,那么是从左到右横向求平均;如果是拼接,那么也是左右横向拼接;
如果是drop,那么也是横向发生变化,体现为列的减少。
当考虑了方向,即axis=1为横向,axis=0为纵向,而不是行和列,那么所有的例子就都统一了。
sort
排序(降序)
lc.sort(["loan_amnt","int_rate"],ascending=False)
前10项
lc.sort(["loan_amnt"],ascending=True).head(10)
# 获取第一行,列名称,
取出列名,排序
# 获取最后一列 列名
df= df.
columns.
values.
tolist()
df= df[-1]
print(df)
或:
df= pf.columns[-1]
# 按上述,列名称,排序
pf=pf.
sort_values(by=
df, axis=0, ascending=False)
#######################################################################################################################
#######################################################################################################################
# 保留位数-加%
# 保留位数
brokeDf['完成率'] = (brokeDf['爆料事审核量'] / brokeDf['爆料事进审量']).
round(4)
.
apply(lambda x: (x * 100))
share_data['成本_上周'] =
round
(share_data['成本_上周'], 0)
# 行保留位数
df.loc['月增量'] = df.loc['月增量'].apply(
lambda x: '%.2f' % (x))
# 加%-保留位数
brokeDf['完成率'] = brokeDf['完成率'].fillna(0).
apply(lambda x: ("%.2f" % x)) + "%"
# 只保留位数
df['30留'] = df['30留'].
apply(lambda x:
'%.2f' % (x * 100))
df.loc['月增量'] =df.loc['月增量'].
apply(lambda x:
'%.2f' % (x))
# 只加 %
df['DAU/MAU'] = df['DAU/MAU'].apply(str)
df['DAU/MAU'] =df['DAU/MAU'].apply(lambda x: (x + '%'))
# 全部 %
# 只加%
df= df.
applymap(lambda
x: x + '%%')
# 保留2位,全部加%
df= df.
applymap(lambda
x: '%.2f%%' % (x*100))
例:
#
percentage = ['优化前-点击率', '第1轮-点击率', '第2轮-点击率', '第2轮-增长幅度', '第3轮-点击率', '第3轮-增长幅度']
# df[percentage] = df[percentage].
applymap(lambda x: '%.2f%%' % (x * 100))
# 单独 加 %
All_Pay['展现次数占比'] = All_Pay['展现次数占比'].
apply(lambda x: '%.2f%%' % (x*100))
注释:
lambda x: '%.2f
%%
' % (x*100)
%.2f % x : 保留两位小数
%% 加%
format 加% 保留位数
df.loc[['合计'], ["3-4小时占比"]] = format((df.loc['合计', "3-4小时"] / df.loc['合计', "全部"]), '.2%')
行加%
public_chuda.loc['服务号日取关率',:] = public_chuda.loc['服务号日取关率',:]
.apply(lambda x: '%.2f%%' % (x*100))
# 需要先-转float数据类型
active_all.iloc[0:60, 14:19] = (active_all.iloc[0:60, 14:19]).apply(lambda x: '%.2f' % (x))
#######################################################################################################################
#######################################################################################################################
# 替换、填充
【
replace
(str:
nan
)
】
# 替换(注意数字类型str型)
df= df.
replace
('nan%', '')
pf['动账摘要'] = pf['动账摘要'].replace('nan', '')
# inf 替换 0
cost_cms_lastmonth = cost_cms_lastmonth.
replace
(
float
('inf'), 0)
# replace替换—str
df_total['favClip'] = df_total['favClip'].str.replace('null','0')
# 多个替换-字典
circle_daily_data["城市"].replace({965004: "燕郊", 1519662: "滕州", 1564395: "日照"}, inplace=True)
# 实例
# replace用于字符替换
df.loc[13, '30留'] =df.loc[13,'30留'].replace('%%', '%')
# 将城市中的965004替换成"燕郊"
df["城市"].replace(965004: "燕郊", inplace=True)
【填充0
(填充NaN)
】
All_Pay.
fillna(0, inplace=True)
action_data1['发帖量_近30日'].
fillna(
1, inplace=True)
例:
df['1周'].
fillna(
df['1周新'], inplace=True)
df['工作流名称'] = df['工作流名称'].fillna(df['工作流名称_新'])
# 转换类型填充-int
pd.to_numeric(data['所属组'], errors='
ignore
').fillna(0)
ignore:遇到无法解析的类型,将其保持原来的内容不变
【apply】
nan为str型,NAN为int型,要限制数字类型
#
!=
88888888填充成‘总生产分数’
Score_daily_1['栏目名称'] = Score_daily_1['栏目名称'].
apply
(lambda x: x if str(x) != '88888888' else '总生产分数')
#
nan
填充成 "其他"
(注意数字类型str型)
Score_daily_1['栏目名称'] = Score_daily_1['栏目名称'].
apply
(lambda x: x if str(x) !=
'nan'
else '其他')
【mask】
#
Python 列为空时替换成另一列的值:
列替换名称,列替换不同列的名称
df
['栏目名称'] =
df
['栏目名称'].apply(str)
# 替换前
df['栏目名称'] =
df
['栏目名称'].
mask
(
df
['栏目名称'] ==
'nan'
,
df
['名称'])
pf['动账摘要备注4'] = pf['动账摘要备注4'].mask(pf['动账摘要备注4'] ==
''
, pf['动账摘要'])
print('替换名称')
# 列替换 <0 替换成 0
add_activity[['累计激活用户数']] = add_activity[['累计激活用户数']].
mask(add_activity[['累计激活用户数']]
<= 0
, 0)
【
map
】
# 替换:电话去敏
df_resume["电话"]=df_resume["电话"].
map(lambda x:
x[:3]+'****'+x[7:] if len(x)>10 else x )
#
map 字段替换 if
pf['长度'] = pf['部门名称'].map(lambda x: (len(x)-len(x.replace('->', ''))))
pf['四级部门'] = pf['部门名称'].map(lambda x: x.split('->')[4]
if (len(x)-len(x.replace('->', ''))==10)
else '')
#######################################################################################################################
#######################################################################################################################
# dataframe
apply用法
# dataframe字段替换
log_table_view['视图sql'] = log_table_view['视图存储sql'].apply(lambda x: x.
replace
('`',''))
# 全部转换
pf = pf.
applymap
(lambda x: x.replace('`', ''))
# dataframe取字段个数
#
'->',个数
pf['长度'] = pf['部门名称'].map(lambda x:
(len(x)-len(x.replace('->', ''))
))
# 求个数:总使用表个数
pf
['总使用表个数'] =
pf
['辅助列'].apply(lambda x:
len(x)
+1) -
pf
['辅助列'].apply(lambda x: len(x.replace(',','')))
# dataframe字段前3位
log_table_view['11'] = log_table_view['视图名称'].apply(lambda x:
x[0:3]
)
# dataframe字段 if控制
# 注:if判断取之前的
,
x.split('->')[4],
否则 取 ‘’
pf['四级部门'] = pf['部门名称'].
apply
(lambda x: x.split('->')[4]
if (len(x)-len(x.replace('->', ''))==10)
else '')
# 取出
dataframe
字段之后的数据:
df1['血缘上层库'] = df1.iloc[:, -1].
apply
(lambda x: x.split('.')[0]) #第0个之后:第一条
df1['血缘上层表'] = df1.iloc[:, -2].
apply
(lambda x: x.split('.')[1])
#第1个之后
df1['血缘上层表'] = df1.iloc[:, -2].
apply
(lambda x: x.split('.')[2])
#第2个之后
df1
['日期'] =
df1
['日期'].apply(lambda x: x.split('2020-')[-1])
# 去除年
# 单元格转为集合去重:
按照‘,’分列 转成一个个元素的集合
pf['辅助列'] =
pf
['辅助列'].apply(lambda x:
set
(
str(x).split(',')
))
# 转为列表
pf
['辅助列'] =
pf
['辅助列'].apply(lambda x:
list(
x))
# 转为字符串
pf
['辅助列'] =
pf
['辅助列'].apply(lambda x:
','.join(x)
)
# 删除辅助列
pf
=
pf
.drop(['辅助列'], axis=1)
# dataframe 列里数组转为值

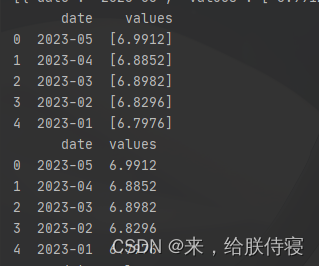
import pandas as pd
pf["values"] = pf["values"].apply(lambda x: x[0])
# errors='coerce':表示忽略:pf["values"] =
pf["values"] = pd.to_numeric(pf["values"], errors='coerce')
# apply调用函数(
列like匹配,替换
)
pf['其他支出'] = pf['其他支出'].apply(str)
def process_refund(row):
if "退款" in row["其他支出"]:
return row["其他支出_中间处理"]
else:
return 0
# 使用apply方法应用process_refund函数来处理每一行
pf["退款"] = pf.apply(process_refund, axis=1)
apply学习网址
#######################################################################################################################
#######################################################################################################################
# 条件
筛选
df.eval() df.query() 类似,用于表达式筛选
df.query('Q1 > Q2 > 90')
# 直接写类型SQL where语句
# 支持传入变量,如大于平均分40分的
a = df.Q1.mean()
df.query('Q1 >
@a
+40')
df.query('Q1 > `Q2`+
@a
')
# df.eval()用法与df.query类似
df[df.eval("Q1 > 90 > Q3 >10")]
df[df.eval("Q1 > `Q2`+@a")]
筛选df.filter()
df.filter(items=['Q1', 'Q2']) # 选择两列
df.filter(regex='Q', axis=1) # 列名包含Q的列
df.filter(regex='e$', axis=1) # 以e结尾的列
df.filter(regex='1$', axis=0) # 正则,索引名以1结尾
df.filter(like='2', axis=0) #
索引中有2的
# 索引中以2开头、列名有Q的
df.filter(regex='^2',axis=0).filter(like='Q', axis=1)
# like 取出条件列:filter方法
由于like只能索引列,先设成索引
pf_type.
set_index
('字段类型', inplace=True)
like '%
int
%',值取出
pf = pf_type.
filter
(
like='int', axis=0
)
读取索引
pf = pf.
reset_index
()
#######################################################################################################################
#######################################################################################################################
dataframe
#
dataframe是否为空-列是否为空值
if not log_data_exception_tmp_bi2.empty:
#
Empty DataFrame(
空数据帧
)
text = '测试一次' + '\n' + data
msg(text)
else:
print('今日异常-已全部完成')
# 集合转
dataframe-集合转列表(
dataframe入库
)
r_SQL = {r'日期': Today,
r'up_batch': up_batch,
}
pf = pd.DataFrame(r_SQL)
或:
r_SQL = {'事业部':
[事业部]
,
'ehr表单名称': [ehr表单名称],
}
pf = pd.DataFrame(r_SQL)
或(中文):
r_SQL = {'事业部': 事业部,
'ehr表单名称': ehr表单名称,
}
pf = pd.DataFrame(r_SQL,
index=[0]
)
#
execute结果
加表头
# conn.execute(
py_git_sql
)后加表头的
result_1 = conn.execute(py_git_sql)
res_1 = result_1.fetchall()
df_1 = pd.DataFrame(list(res_1), columns=result_1.keys())
#
pf.shape[0]
dataframe 的
行数,列数,更新行数
print('本次更新行数: ' + str(pf.shape[0]))
shape[0]读取矩阵第一维度的长度,即数组的行数
shape[1]读取矩阵第一维度的长度,即数组的列数
切片函数
df.truncate
#######################################################################################################################
#######################################################################################################################

















 1994
1994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









