






文章目录
概要
解释R中normalize.quantiles()的使用
主题内容
library(preprocessCore)
c <- matrix(c(5,2,3,
4,1,6,
3,4,6), nrow=3)
colnames(c) <- c("A", "B", "C")
rownames(c) <- c("gene1", "gene2", "gene3")
具体解释
当然可以!我们来用非常通俗、生活化的语言重新解释一下 normalize.quantiles() 到底干了什么,你一定能理解!
🎯 场景类比:学生成绩
假设我们有 3 个老师(A、B、C),分别给同一批 3 个学生打分,但每个老师评分标准不同:
| 老师A | 老师B | 老师C | |
|---|---|---|---|
| 学生1 | 5 | 4 | 3 |
| 学生2 | 2 | 1 | 4 |
| 学生3 | 3 | 6 | 6 |
可以看到:
- 老师B可能打分都很低(1~6);
- 老师C可能喜欢打高分;
- 老师A中规中矩;
❗问题:
现在我们想分析学生表现,但每个老师的打分标准不一样,直接比较会不公平。
✅ 目标:
让每个老师的打分分布“看起来一样”,以便公平对比每个学生的相对位置(排名)是否一致。
✨解决办法:normalize.quantiles()
🪄 它做了三件事:
✅ 第1步:对每列(老师)打分排序(不改变顺序,只记录名次)
| 排名 | 老师A | 老师B | 老师C |
|---|---|---|---|
| 第1名(最低分) | 2 | 1 | 3 |
| 第2名 | 3 | 4 | 4 |
| 第3名(最高分) | 5 | 6 | 6 |
✅ 第2步:对每个“名次”取所有老师平均分
| 排名 | 平均分数 |
|---|---|
| 第1名 | (2+1+3)/3 = 2 |
| 第2名 | (3+4+4)/3 = 3.67 |
| 第3名 | (5+6+6)/3 = 5.67 |
✅ 第3步:把平均值替换回原表格,但保留原来每个老师对每个学生的排名
谁是第1名就给他2分,谁是第2名就给他3.67,谁是第3名就给他5.67
✅ 最终结果(位置和原始名次一样,但分布一致)
| 老师A | 老师B | 老师C | |
|---|---|---|---|
| 学生1 | 5.67 | 3.67 | 2.00 |
| 学生2 | 2.00 | 2.00 | 3.67 |
| 学生3 | 3.67 | 5.67 | 5.67 |
✅ 数据分布比较
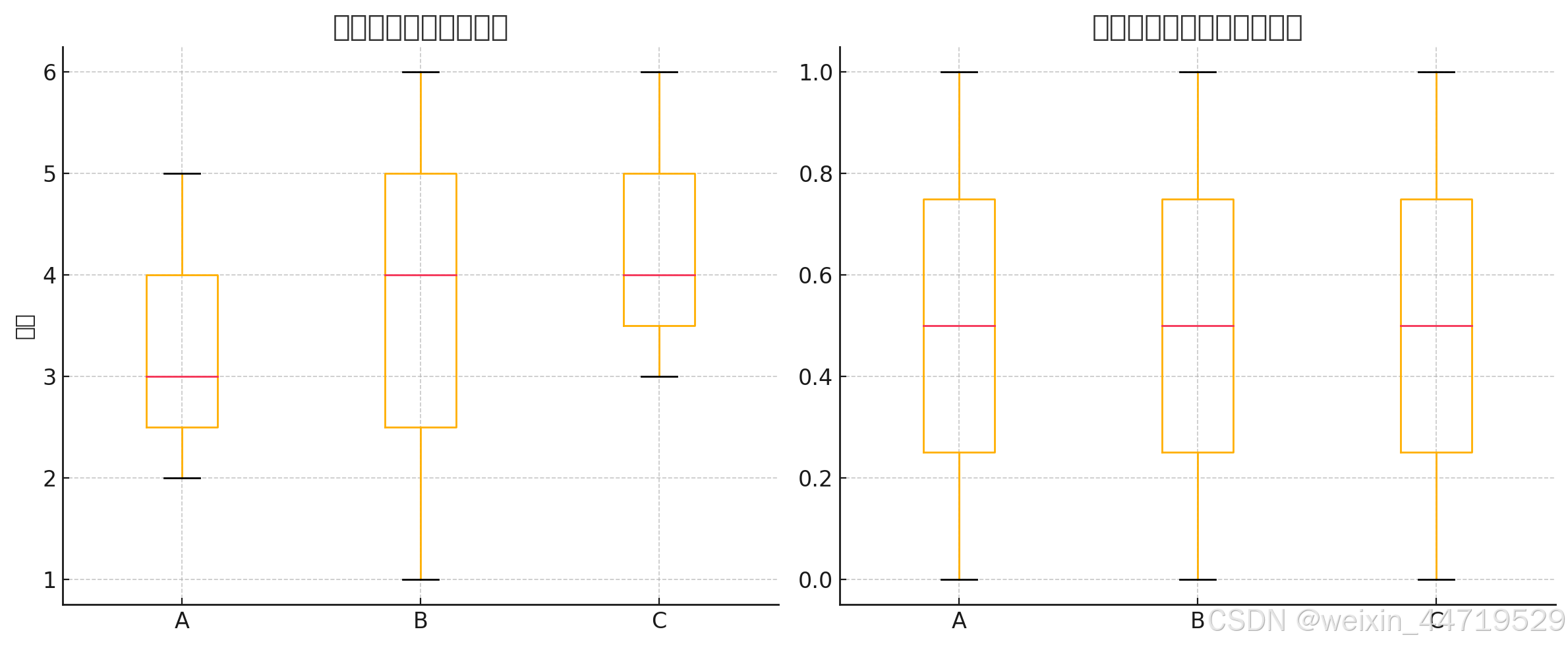
✅ 左边图:标准化前(原始数据)
- 三列(样本 A、B、C)分布明显不同;
- A 比较中等,B 分布更分散,C 偏高。
✅ 右边图:标准化后(分位数标准化)
- 所有列的分布几乎完全一致;
- 每一列的“数据分布形状”统一了;
- 可以更公平地做后续分析,比如比较每个基因在不同样本间的相对表达。
这正是 normalize.quantiles() 的作用核心:
📊 将多个样本的数值分布调整为一致的“排名形状”,以便公平比较。
如果你愿意,我可以直接画图对比标准化前后的分布差异,让你一眼看懂要不要?🎨
小结
normalize.quantiles()的核心思想是:“你保留原来的名次,但我统一你们打分的尺度”——这样就可以公平比较啦!
针对同一个基因不同处理方式,可以使用这种方式表示在不同处理方式的排名,从而比较不同的处理后的该基因的表达值。

















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









