







 本文深入探讨了Java中Lambda表达式的高级应用,包括转换集合、获取最大最小值、计算平均数、数据分块及并行处理技巧。通过具体代码示例,展示了如何使用流API进行高效的数据操作。
本文深入探讨了Java中Lambda表达式的高级应用,包括转换集合、获取最大最小值、计算平均数、数据分块及并行处理技巧。通过具体代码示例,展示了如何使用流API进行高效的数据操作。
高级集合类和收集器
第二节综合了函数表达式的其他用法,双冒号直接调用类的无参方法,还有 groupby 以及 mapping等。
这里都知道了流是多线程执行的,在多核cpu 上跑的会比较快,但是流还是保留了原有的 有序无需。如果是List就是有序,如果是Set 就还是无需。
由于这里用了新语法,所以将会改变一下之前的list 改成一个对象
语法
demo -> demo.getId() 等同于 Demo::getId
public static void main(String[] args) {
List<Demo> demos = Stream.of(
new Demo(1,"dan","S001"),
new Demo(2,"ben","S002"),
new Demo(3,"lisa","S001"),
new Demo(4,"Angela","S003")
).collect(Collectors.toList());
}
}
@Data
class Demo{
private int id;
private String name;
private String classNo;
public Demo(){}
public Demo(int id,String name,String classNo){
this.id = id;
this.name = name;
this.classNo = classNo;
}
}
1.转换成其他集合 toList,toSet,toCollection
这个就很简单了。直接上代码
List<Demo> demos0 = demos.stream().collect(Collectors.toList());
Set<Demo> demos1 = demos.stream().collect(Collectors.toSet());
Set<Demo> demos2 = demos.stream().collect(Collectors.toCollection(TreeSet::new));
List<Demo> demos3 = demos.stream().collect(Collectors.toCollection(ArrayList::new));
2. 转换成值
我要找到这一组集合里面id最大的demo和最小的demo,可以这样做。
Function<Demo,Integer> getId = Demo::getId;
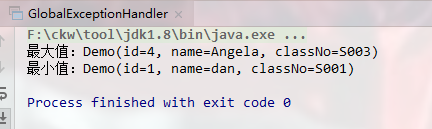
Optional<Demo> max =demos.stream().collect(Collectors.maxBy(Comparator.comparing(getId)));
System.out.println("最大值:"+max.get());
Optional<Demo> min =demos.stream().collect(Collectors.minBy(Comparator.comparing(getId)));
System.out.println("最小值:"+min.get());
执行结果
取平均
double avg = demos.stream().collect(Collectors.averagingInt(Demo::getId));
System.out.println("平均数:"+avg);
数据分块 这里就要涉及到 groupBy 了, groupBy 之前呢先看一个 stream 提供的 predicate 对象
partitioningBy 把符合条件的放到true 底下 false 的放到另一个底下 组合成一个Map
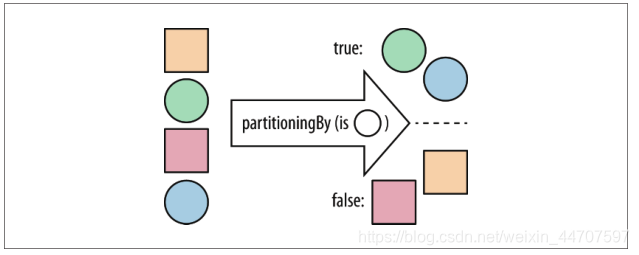
比如说我想找到所有 S001 班的人。
Map<Boolean,List<Demo>> classCount = demos.stream().collect(Collectors.partitioningBy(demo -> demo.getClass().equals("S001")));
System.out.println(JSONObject.toJSONString(classCount));
执行结果

然后就是 groupBy 了。
Map<String,List<Demo>> classInfo = demos.stream().collect(Collectors.groupingBy(Demo::getClassNo));
System.out.println(JSONObject.toJSONString(classInfo));
结果就是

这样我觉得还不够,我想知道每个班的人都叫什么,或者每个班的人数为多少。怎么办呢。
下面就要用到 mapping、counting
// 获取每个班级的人数
Map<String,Long> mapInfo = demos.stream().collect(Collectors.groupingBy(Demo::getClassNo,Collectors.counting()));
System.out.println(JSONObject.toJSONString(mapInfo));
// 获取班级底下的人的名字
Map<String,List<String>> map = demos.stream().collect(Collectors.groupingBy(Demo::getClassNo,
Collectors.mapping(Demo::getName,Collectors.toList())));
System.out.println(JSONObject.toJSONString(map));
结果

3.并行处理
parallelStream
我们知道stream 不光提供了强大的lambda 表达式,还有很强大的并行处理。
就是充分利用我们的cpu 让多个核心处理同一个操作。
Map<String,List<String>> map = demos.parallelStream().collect(Collectors.groupingBy(Demo::getClassNo,
Collectors.mapping(Demo::getName,Collectors.toList())));
是的只要替换一个 parallelStream 就这么简单就可以了。
读到这里,大家的第一反应可能是立即将手头代码中的 stream 方法替换为 parallelStream
方法,因为这样做简直太简单了!先别忙,为了将硬件物尽其用,利用好并行化非常重
要,但流类库提供的数据并行化只是其中的一种形式。
我们先要问自己一个问题:并行化运行基于流的代码是否比串行化运行更快?这不是一
个简单的问题。回到前面的例子,哪种方式花的时间更多取决于串行或并行化运行时的
环境。
以例 6-1 和例 6-2 中的代码为准,在一个四核电脑上,如果有 10 张专辑,串行化代码的速
度是并行化代码速度的 8 倍;如果将专辑数量增至 100 张,串行化和并行化速度相当;如
果将专辑数量增值 10 000 张,则并行化代码的速度是串行化代码速度的 2.5 倍。
性能好
1.ArrayList 、数组或 IntStream.range ,这些数据结构支持随机读取,也就是说它们能轻
而易举地被任意分解。
性能一般
2.HashSet 、 TreeSet ,这些数据结构不易公平地被分解,但是大多数时候分解是可能的。
性能差
3.有些数据结构难于分解,比如,可能要花 O(N) 的时间复杂度来分解问题。其中包括
LinkedList ,对半分解太难了。还有 Streams.iterate 和 BufferedReader.lines ,它们
长度未知,因此很难预测该在哪里分解。
初始的数据结构影响巨大。举一个极端的例子,对比对10 000个整数并行求和,使用 ArrayList
要比使用 LinkedList 快 10 倍。这不是说业务逻辑的性能情况也会如此,只是说明了数据结构
对于性能的影响之大。使用形如 LinkedList 这样难于分解的数据结构并行运行可能更慢。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









