




 使用Python和正则表达式爬取豆瓣电影Top250榜单,涵盖排名、电影名、国家、导演等信息。面对挑战,成功获取top200数据。
使用Python和正则表达式爬取豆瓣电影Top250榜单,涵盖排名、电影名、国家、导演等信息。面对挑战,成功获取top200数据。
WebScraping (Day 2)
*** get and post request ***
Preparation: python 3.7, requests, re
主要任务:爬取豆瓣电影 Top 250里的内容包括名次、影片名称、国家、导演等字段。
- 查看豆瓣电影网页
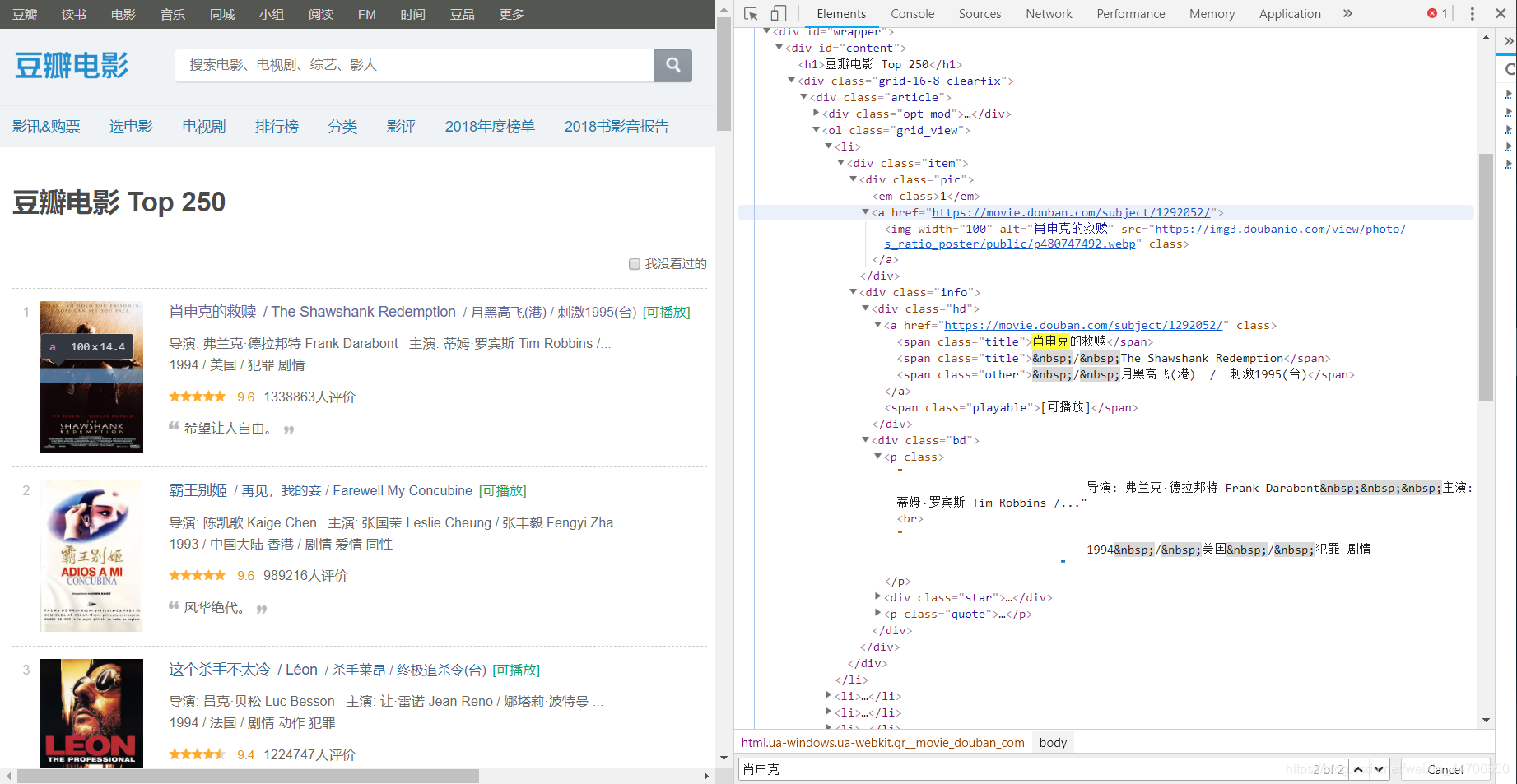 2. 尝试爬取网页,获取前25部电影名
2. 尝试爬取网页,获取前25部电影名
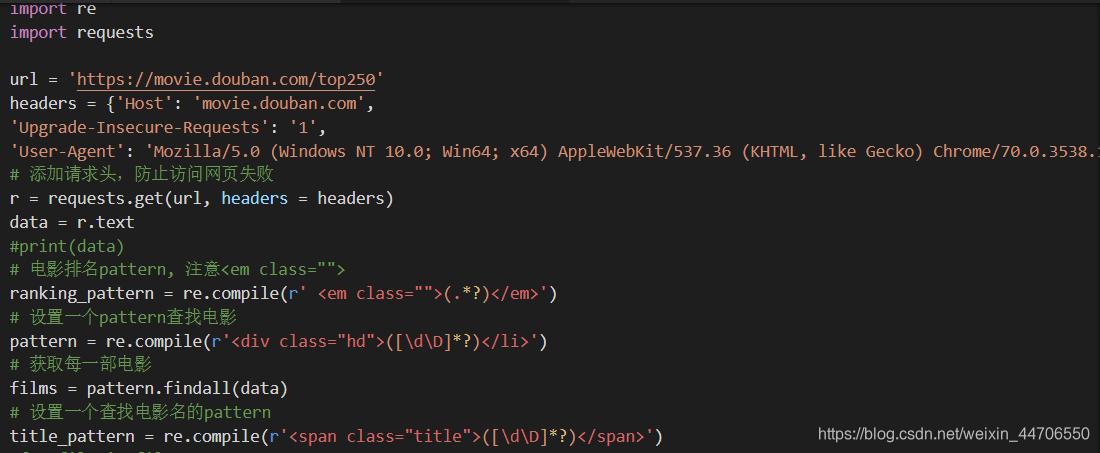
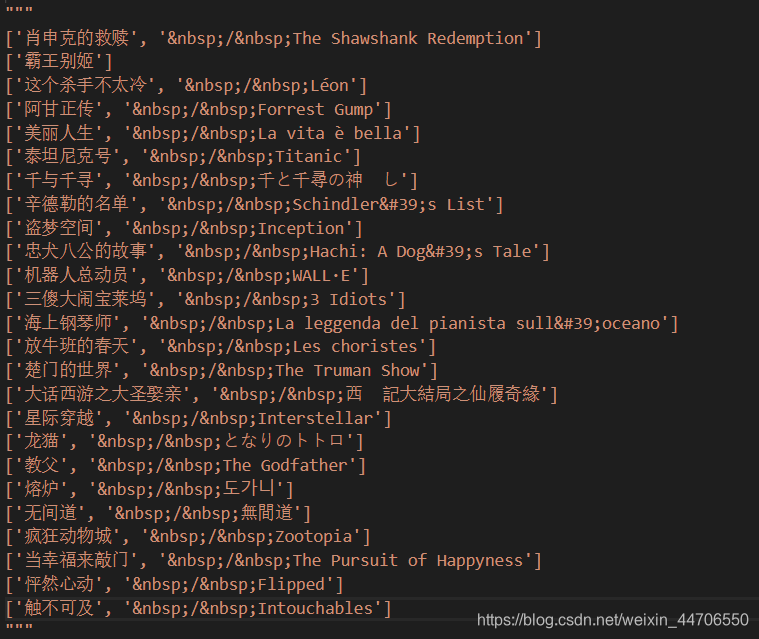
3. 正式开爬
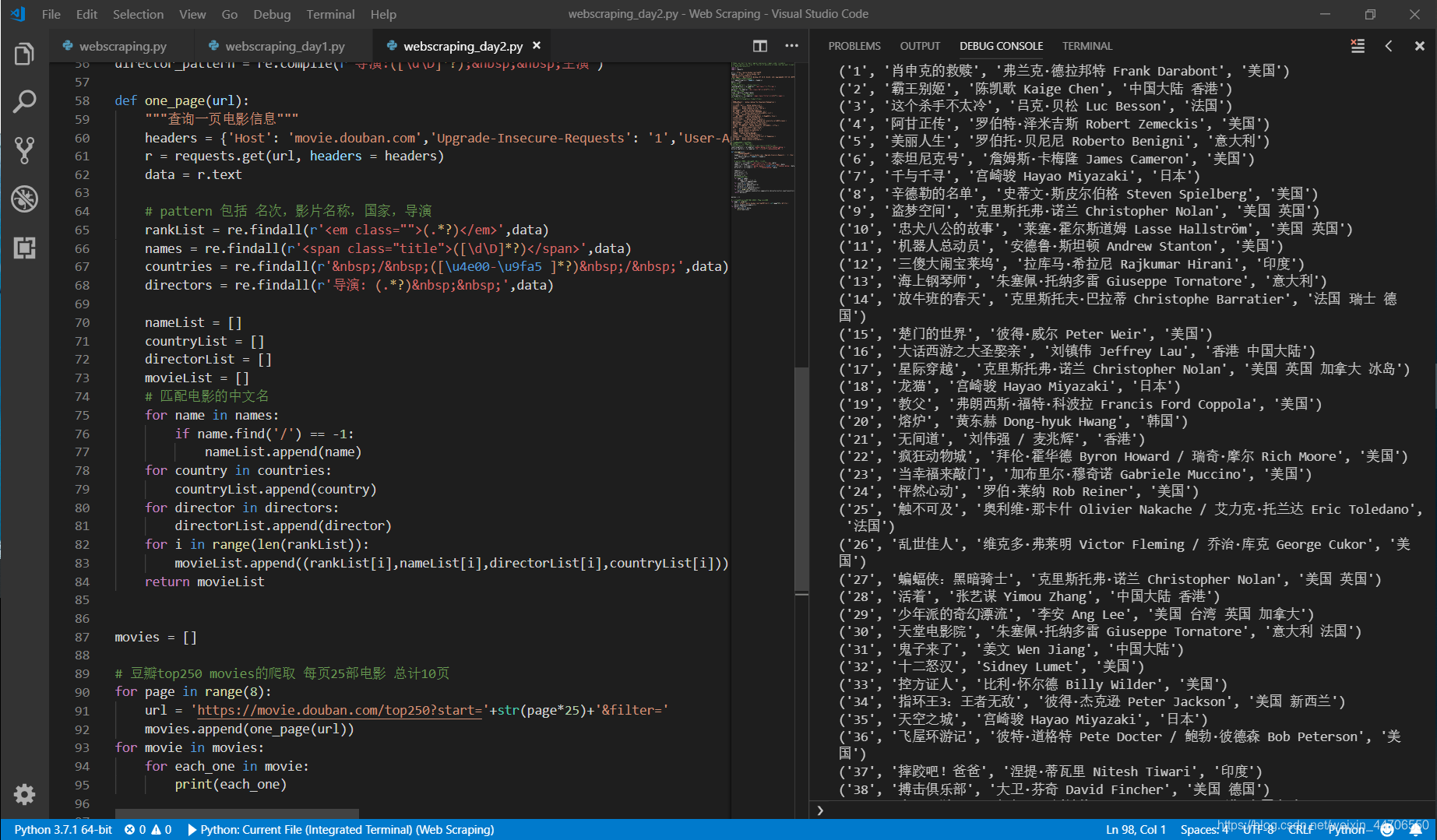
4. 总结
regex 之变幻让人为之惊叹。本想返回所有top250,但最后一个导演的问题无法爬取。 最终只返回top200。
5. 文献
http://funhacks.net/2016/12/27/regular_expression/#匹配中文
https://www.cnblogs.com/carpenterworm/p/6042210.html

















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









