







PySpark中的RDD基本操作
【课程性质:PySpark数据处理】
文章目录
1. 实验目标
- 使用 PySpark创建RDD,并学习RDD的基本操作
2. 本次实验主要使用的 P y t h o n Python Python 库
| 名称 | 版本 | 简介 |
|---|---|---|
| r e q u e s t s requests requests | 2.20.0 2.20.0 2.20.0 | 线性代数 |
| P a n d a s Pandas Pandas | 0.25.0 0.25.0 0.25.0 | 数据分析 |
| P y S p a r k PySpark PySpark | 2.4.3 2.4.3 2.4.3 | 大数据处理 |
| M a t p l o t l i b Matplotlib Matplotlib | 3.0.1 3.0.1 3.0.1 | 数据可视化 |
3. 适用的对象
- 本课程假设您已经学习了 P y t h o n Python Python 基础,具备数据可视化基础
- 学习对象:本科学生、研究生、人工智能、算法相关研究者、开发者
- 大数据分析与人工智能
4. 实验步骤
PySpark中的RDD基本操作
步骤1 安装并引入必要的库
# 安装第三方库
!pip install pyspark==2.4.5
# 获取数据集
import zipfile
with zipfile.ZipFile('/resources/jupyter/pyspark/pyspark_dataset_kdd.zip') as z:
z.extractall()
本实验将介绍三个基本但必不可少的 Spark操作。其中一个是***transformations***中的map and filter。另一个是***action***的collect。同时,我们将介绍 Spark 中的***persistence***概念。
步骤2获取数据并创建RDD
正如我们在第一个笔记本中所做的那样,我们将使用199年KDD杯提供的缩减数据集(1θ%),其中包含近50万个网络交互。该文件作为Gzip文件提供,我们将在下载到本地。
现在我们可以使用这个文件来创建RDD
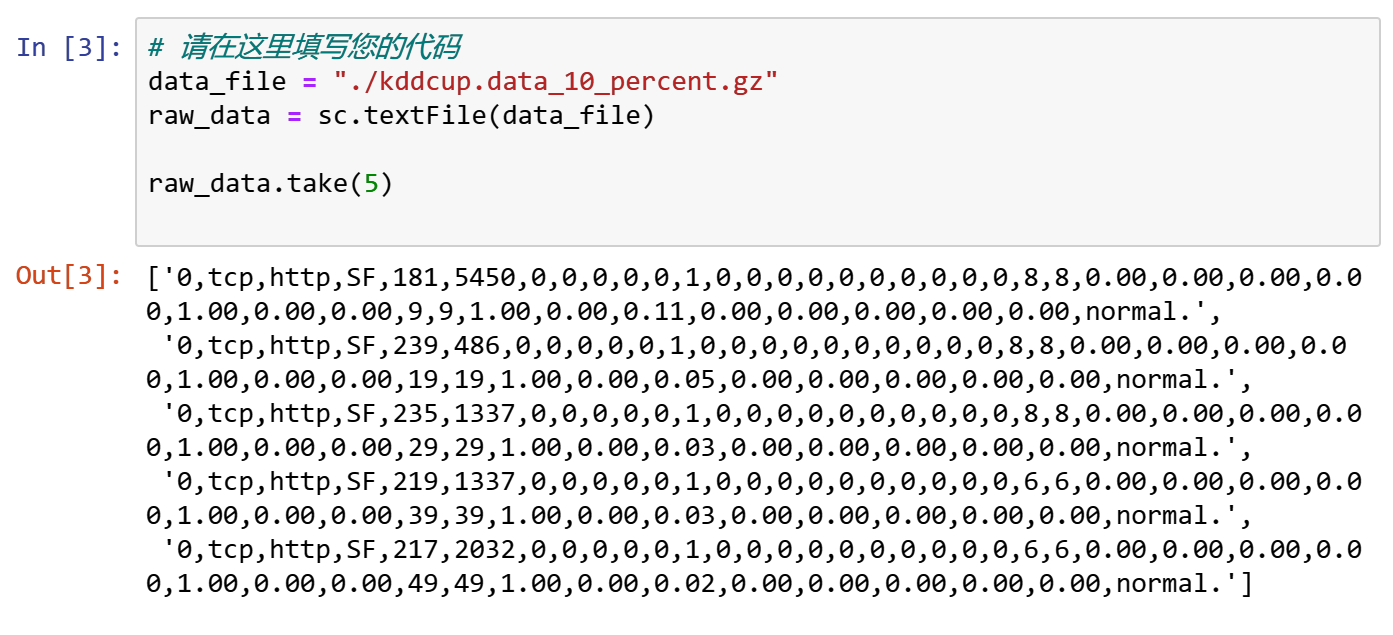
data_file ="./kddcup.data_10_percent.gz"
raw_data=sc.textFile(data_file)
#查看前五行
raw_data.take(5)
现在我们将数据文件加载到 raw_data RDD中。
步骤3 filter 转换
这个转换可以应用于RDDs,以便只保留满足特定条件的元素。
更具体地说,函数是在原始RDD中的每个元素上求值的。新生成的RDD将只包含那些使函数返回True的元素。
例如,假设我们想要计算有多少normal.。我们数据集中进行操作。我们可以按照以下方式过滤我们的 raw_data RDD。
normal_raw_data = raw_data.filter(lambda x: 'normal.' in x)

现在我们可以计算在新的RDD中有多少个元素。
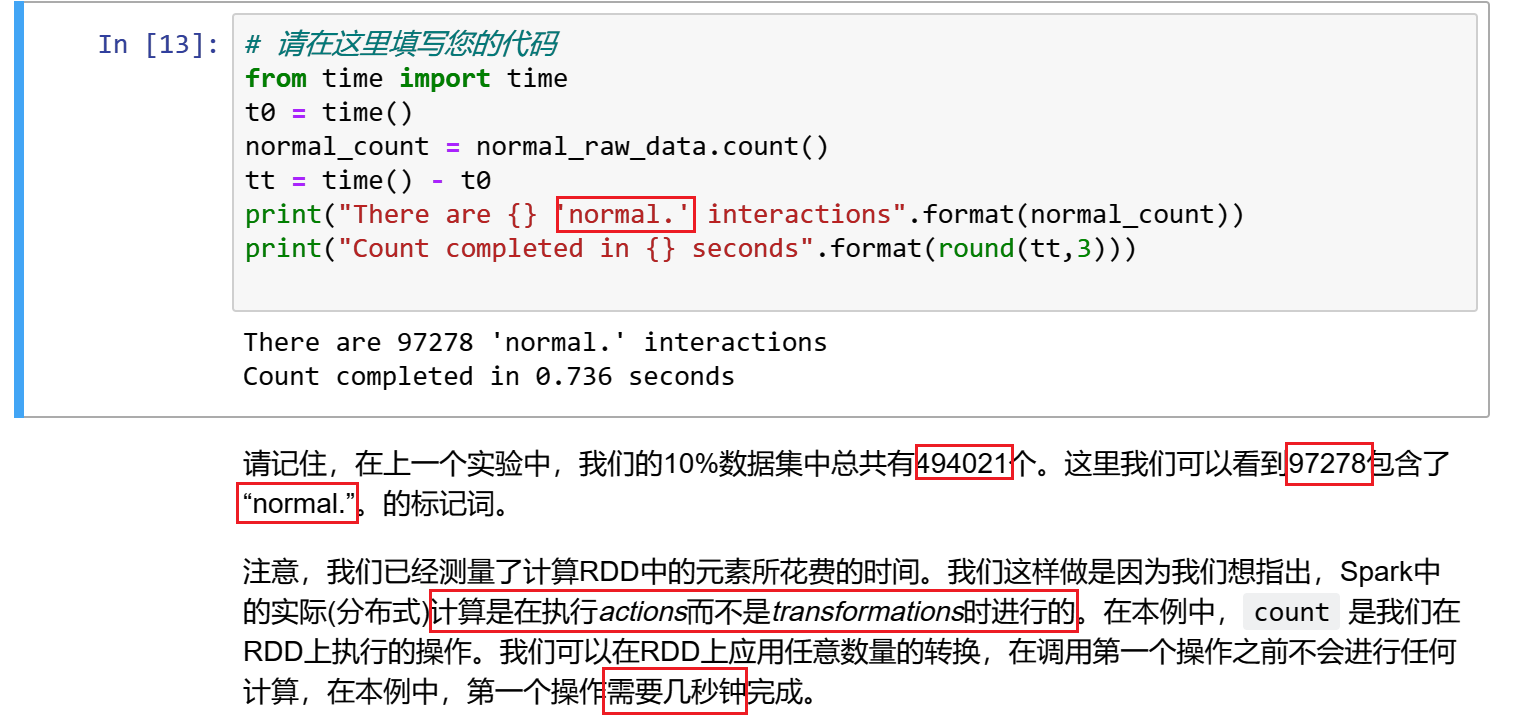
from time import time
t0 = time()
normal_count = normal_raw_data.count()
tt = time() - t0
print("There are {} 'normal.' interactions".format(normal_count))
print("Count completed in {} seconds".format(round(tt,3)))
步骤4 map 转换
通过使用Spark中的map转换,我们可以对RDD中的每个元素应用一个函数。Python的lambdas对这一点特别有表现力。
在本例中,我们希望以csv格式读取数据文件。我们可以这样做,对RDD中的每个元素应用一个lambda函数,如下所示。
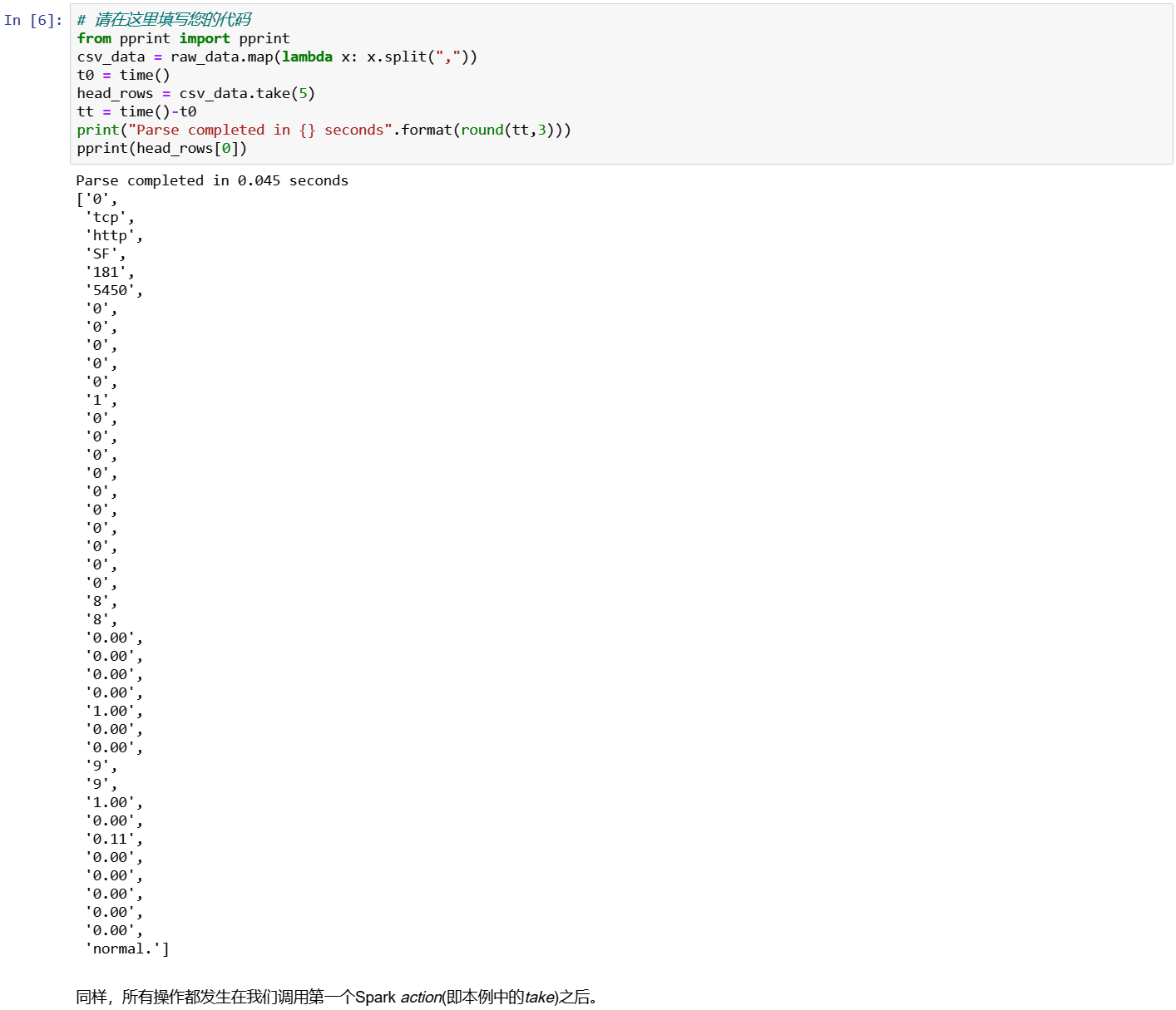
from pprint import pprint
csv_data = raw_data.map(lambda x: x.split(","))
t0 = time()
head_rows = csv_data.take(5)
tt = time() - t0
print("Parse completed in {} seconds".format(round(tt,3)))
pprint(head_rows[0])
如果我们取很多元素而不是前几个呢?
t0 = time()
head_rows = csv_data.take(100000)
tt = time() - t0
print("Parse completed in {} seconds".format(round(tt,3)))

使用 map 和预定义函数
当然,我们可以使用带有map的预定义函数。
假设我们希望RDD中的每个元素都是键值对,其中键是标记(例如***normal***),值是表示CSV格式文件中的行的整个元素列表。我们可以这样进行。
def parse_interaction(line):
elems = line.split(",")
tag = elems[41]
return (tag, elems)
key_csv_data = raw_data.map(parse_interaction)
head_rows = key_csv_data.take(5)
pprint(head_rows[0])

步骤5 collect 动作 action
到目前为止,我们已经使用了actions中的count和take
我们需要学习的另一个基本动作是collect。基本上,它将把RDD中的所有元素都放到内存中,以便我们使用它们。因此,必须小心使用它,特别是在处理大型RDDs时。
一个使用原始数据的例子。
t0 = time()
all_raw = raw_data.collect()
tt = time() - t0
print("Data collected in {} seconds".format(round(tt,3)))

作为组合前面所有内容的最后一个示例,我们希望收集所有normal.交互作为键值对。
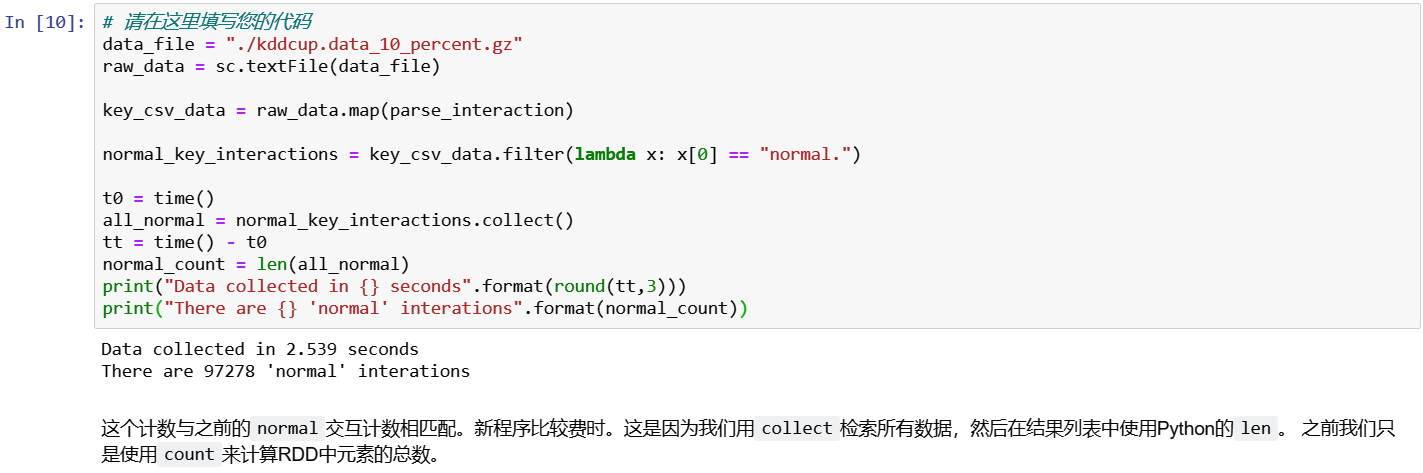
# get data from file
data_file = "./kddcup.data_10_percent.gz"
raw_data = sc.textFile(data_file)
# parse into key-value pairs
key_csv_data = raw_data.map(parse_interaction)
# filter normal key interactions
normal_key_interactions = key_csv_data.filter(lambda x: x[0] == "normal.")
# collect all
t0 = time()
all_normal = normal_key_interactions.collect()
tt = time() -t0
normal_count = len(all_normal)
print("Data collected in {} seconds".format(round(tt,3)))
print("There are {} 'normal' interactions". format(normal_count))
PySpark中的RDDs Aggregations操作
步骤6 根据标签检查交互持续时间
fold 和 reduce都将函数作为参数应用于 RDD 的两个元素。fold操作与reduce操作的不同之处在于,它获取用于初始调用的额外初始***zero value***。这个值应该是所提供函数的恒等元素。
例如,假设我们想知道 normal interactions 和 attack interactions 的总持续时间。我们可以使用reduce,如下所示。
# 解析数据
csv_data = raw_data.map(lambda x: x.split(","))
# separate into different RDDs
normal_csv_data = csv_data.filter(lambda x: x[41]=="normal.")
attack_csv_data = csv_data.filter(lambda x: x[41]!="normal.")
我们传递给 reduce 的函数获取和返回RDD类型相同的元素。
如果我们想要计算持续时间,我们需要将该元素提取到一个新的RDD中。
normal_duration_data = normal_csv_data.map(lambda x: int(x[0]))
attack_duration_data = attack_csv_data.map(lambda x: int(x[0]))
现在我们可以reduce这些新的RDDs。
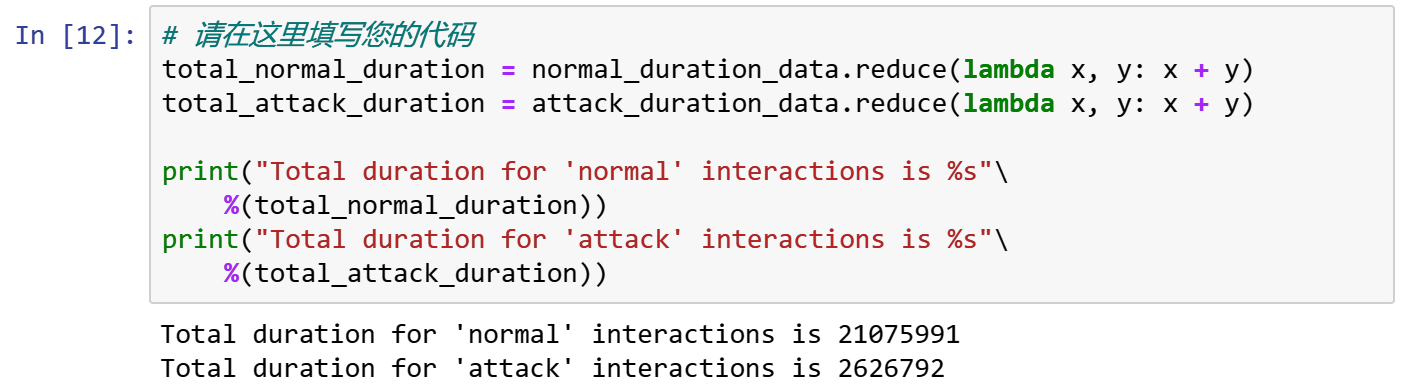
total_normal_duration = normal_duration_data.reduce(lambda x, y: x + y)
total_attack_duration = attack_duration_data.reduce(lambda x, y: x + y)
print("Total duration for 'normal' interactions is %s"\
%(total_normal_duration))
print("Total duration for 'attack' interactions is %s"\
%(total_attack_duration))
我们可以更进一步,使用计数来计算持续时间的平均值。
normal_count = normal_duration_data.count()
attack_count = attack_duration_data.count()
print("Mean duration for 'normal' interactions is %s"\
%(round(total_normal_duration/float(normal_count),3)))
print("Mean duration for 'attack' interactions is %s"\
%(round(total_attack_duration/float(attack_count),3)))

我们有一个第一个(而且过于简单)的方法来识别attack interactions。
步骤7 更好的方法,使用 aggregate
aggregate 操作将我们从返回与我们正在处理的 RDD 类型相同的约束中解放出来。与fold类似,我们提供了想要返回的类型的初始零值。
然后我们提供两个函数。第一个用于将 RDD 中的元素与累加器组合起来。第二个函数用于合并两个累加器。我们来实际计算一下之前的均值。
normal_sum_count = normal_duration_data.aggregate(
(0,0), # the initial value
(lambda acc, value: (acc[0] + value, acc[1] + 1)), # combine value with acc
(lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1])) # combine accumulators
)
print("Mean duration for 'normal' interactions is %s"\
%(round(normal_sum_count[0]/float(normal_sum_count[1]),3)))

在上一步骤的聚合中,累加器的第一个元素保存总和,而第二个元素保存计数。
将累加器与RDD元素组合起来就是对值求和并增加计数。组合两个累加器只需要一个成对的和。
对于attack type interactions,我们也可以这样做。
attack_sum_count = attack_duration_data.aggregate(
(0,0), # the initial value
(lambda acc, value: (acc[0] + value, acc[1] + 1)), # combine value with acc
(lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1])) # combine accumulators
)
print("Mean duration for 'attack' interactions is %s"\
%(round(attack_sum_count[0]/float(attack_sum_count[1]),3)))


PySpark中的RDDs key value操作
步骤8 为交互类型创建键值对RDD
在这个实验中,我们想对我们的网络交互数据集做一些探索性的数据分析。更具体地说,我们希望根据每个网络交互类型的某些变量(如持续时间)来分析它们。为此,我们首先需要创建适合于此的RDD,其中每个交互都被解析为表示值的CSV行,并与对应的标记一起作为键放在一起。
通常,我们创建键/值对 RDDs 是通过使用map的函数应用于原始数据。这个函数返回给定 RDD 元素的对应对。我们可以这样进行。
csv_data = raw_data.map(lambda x: x.split(","))
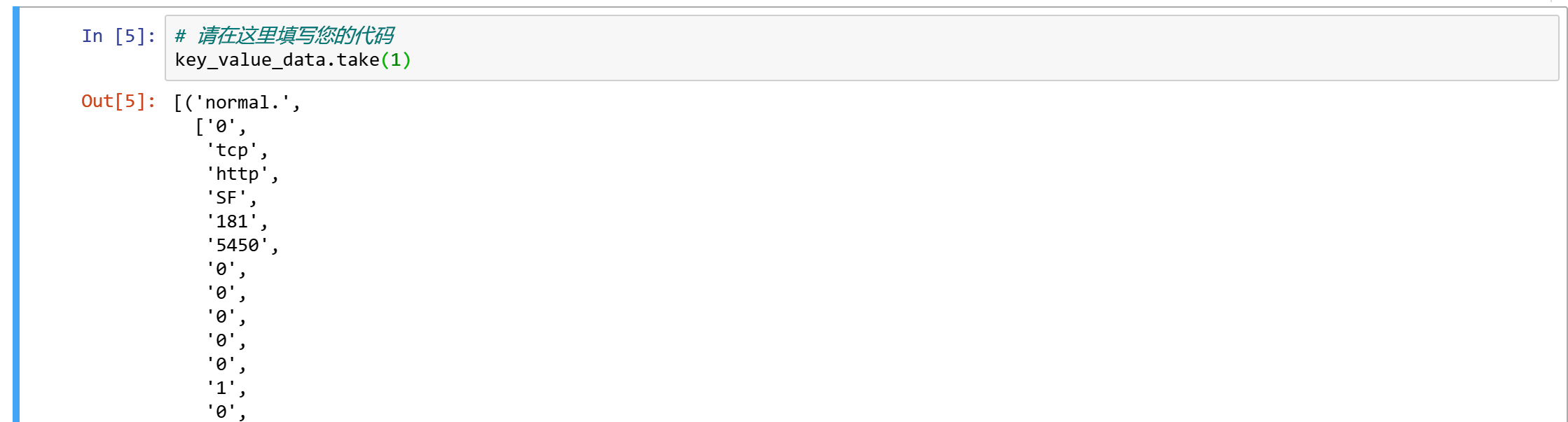
key_value_data = csv_data.map(lambda x: (x[41], x)) # x[41] contains the network interaction tag
现在,我们已经准备好了要使用的键/值对数据。让我们得到第一个元素,看看它是什么样的。
key_value_data.take(1)
步骤9 具有键/值对RDDs的数据聚合
我们可以对具有键/值对的RDDs进行普通RDDs的所有转换和操作。我们只需要让函数与成对元素一起工作。
此外,Spark还提供了特定的功能来处理包含对元素的RDDs。它们与一般的RDDs非常相似。
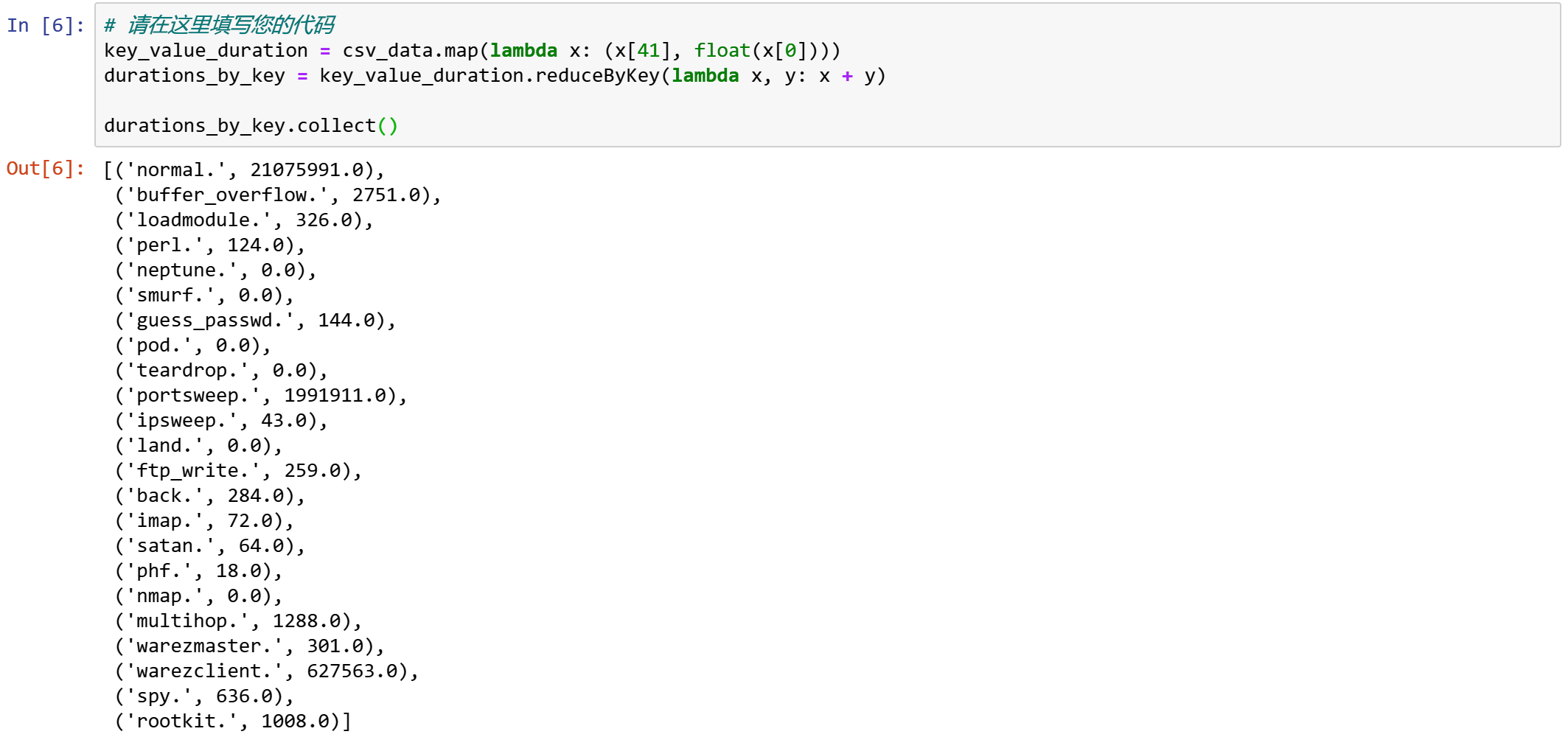
例如,我们有一个reduceByKey转换,我们可以使用它来计算每种网络交互类型的总持续时间。
key_value_duration = csv_data.map(lambda x: (x[41], float(x[0])))
durations_by_key = key_value_duration.reduceByKey(lambda x, y: x + y)
durations_by_key.collect()
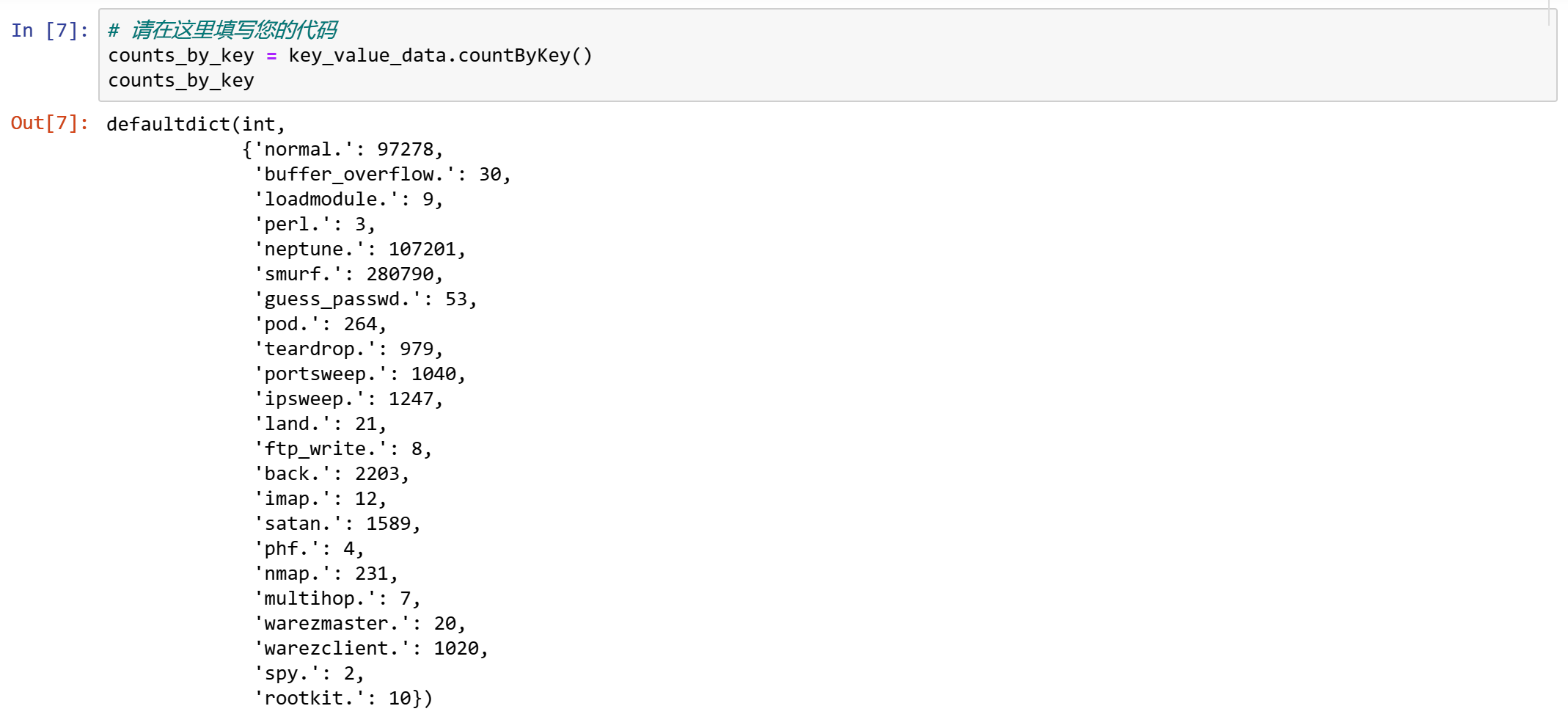
我们对键/值对有一个特定的计数操作。
counts_by_key = key_value_data.countByKey()
counts_by_key
使用combineByKey
这是最常见的按键聚合函数。大多数其他每个键组合器都是使用它实现的。我们可以把它看作是aggregate 的等效,因为它允许用户返回与输入数据类型不同的值。
例如,我们可以使用它来计算每种类型的平均持续时间,如下所示。
sum_counts = key_value_duration.combineByKey(
(lambda x: (x, 1)), # the initial value, with value x and count 1
(lambda acc, value: (acc[0]+value, acc[1]+1)), # how to combine a pair value with the accumulator: sum value, and increment count
(lambda acc1, acc2: (acc1[0]+acc2[0], acc1[1]+acc2[1])) # combine accumulators
)
sum_counts.collectAsMap()
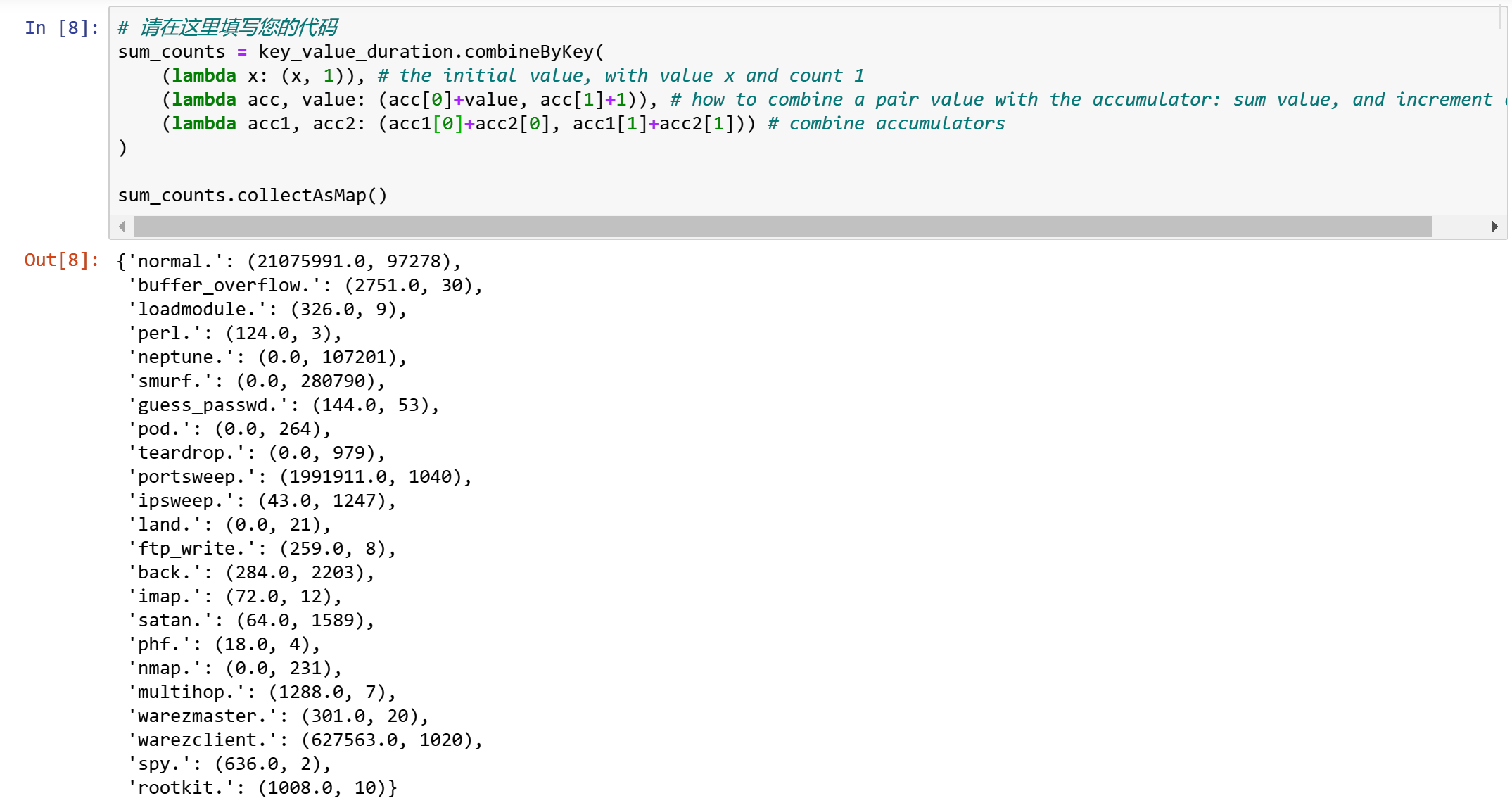
我们可以看到,参数与前一个实验中传递给aggregate的参数非常相似。与每种类型关联的结果都是成对的。如果我们想要得到平均值,我们需要在收集结果之前做除法。
duration_means_by_type = sum_counts.map(lambda x: (x[0], round(x[1][0]/x[1][1],3))).collectAsMap()
# Print them sorted
for tag in sorted(duration_means_by_type, key=duration_means_by_type.get, reverse=True):
print (tag, duration_means_by_type[tag])



















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











