







Chroma原理图
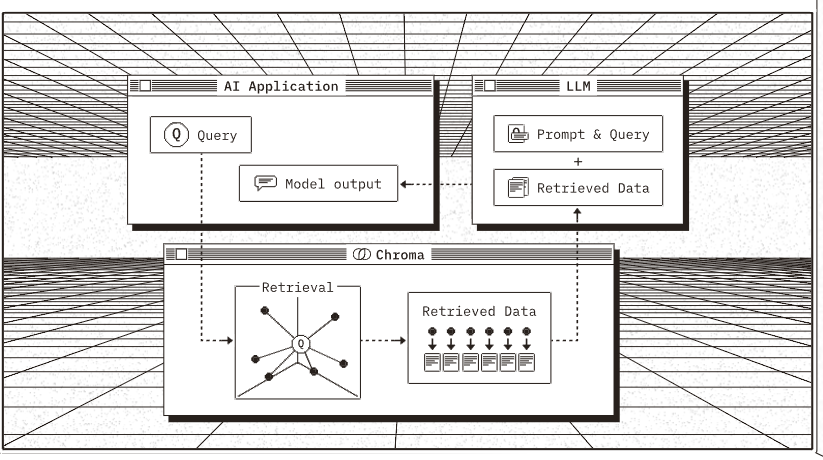
- AI应用程序:
- 应用程序向系统发送查询(Query),请求获取相关信息。
- 系统根据查询生成模型输出(Model output),这是AI处理后的结果。
- Chroma(向量数据库):
- 检索(Retrieval):这是Chroma数据库的核心,数据库根据查询从存储的数据中检索出相关的信息。
- 向量(即数据的数值表示)被用来搜索并找到最相关的文档或数据点。
- 检索到的数据(Retrieved Data)将用于后续的处理。
- LLM(大语言模型):
- LLM接收提示和查询(Prompt & Query)以及从Chroma检索到的数据。
- 结合查询和检索到的信息,LLM生成最终的响应或结果。
Chroma 是如何返回文本
1. 文本向量化:
-
在将文本存储到 Chroma 中之前,每条文本数据会被转换为一个向量(通常是通过一个 embedding model,例如 BERT 或 OpenAI’s GPT 等模型)。
-
这些模型的目的是将文本映射到一个高维空间,在这个空间中,相似的文本会被映射到相近的向量。这些向量通常是浮点数数组,包含了文本的语义信息。
-
举个例子:
-
“今天的天气很好。” 可能会被转换成一个向量
[0.12, 0.45, 0.87, ...]。 -
“今天天气不错。” 可能会被转换成一个向量
[0.11, 0.46, 0.86, ...]。
-
-
虽然这两个句子在文字上有所不同,但它们在语义上是相似的,因此它们的向量会非常接近。
2. 存储向量:
-
这些向量会被存储在 Chroma 向量数据库中,但它们不仅仅是纯粹的数值数据。
-
除了存储向量外,通常还会存储一些 元数据(metadata),例如:
-
对应的 原始文本(即“今天的天气很好”)。
-
该文本的 文档ID、标题、来源 或其他有用的附加信息。
-
-
这样,尽管数据库中存储的是向量,但每个向量都与一个原始的文本(或文档)相关联。
3. 查询与向量化:
-
当用户发送一个查询时,Chroma 会将查询文本也转换成一个向量。例如,用户查询“天气如何?”
-
系统会使用和存储文本时相同的 嵌入模型(例如 BERT)来将查询转换为一个向量。这个查询向量也会处于相同的高维空间中。
4. 向量检索:
-
现在,Chroma 使用该查询向量与数据库中所有存储的向量进行比较。常用的检索方法是 最近邻搜索(例如 KNN,即寻找与查询向量最接近的向量)。
-
Chroma 会根据向量间的相似度(通常使用 余弦相似度、欧氏距离等度量)找到与查询向量最相似的几个向量。
-
这些最相似的向量通常对应于存储在数据库中的文本。
5. 返回文本:
-
一旦 Chroma 找到了与查询向量相似的向量,它会返回这些向量对应的原始文本。例如:
- 如果查询是“天气如何”,Chroma 可能找到与之相似的文本,如“今天天气晴朗”或者“天气很好,适合外出”。
-
在返回时,Chroma 会附带这些文本的元数据,帮助应用程序理解这些文本属于哪个文档,或者为什么它们是相关的。
6. 示例:
假设我们在数据库中存储了以下文本及其向量:
| 文本 | 向量 |
|---|---|
| 今天的天气很好 | [0.12, 0.45, 0.87, …] |
| 明天可能下雨 | [0.10, 0.47, 0.85, …] |
| 这篇文章讨论了机器学习 | [0.98, 0.21, 0.57, …] |
当用户查询“天气怎么样?”时,Chroma 会将该查询转换为向量,并与上述向量进行比较。假设查询的向量是 [0.11, 0.46, 0.86, ...],它与“今天的天气很好”这条文本的向量非常相似,因此系统会返回这条文本作为检索结果。
总结:
-
Chroma 不直接存储文本数据,而是存储文本的 向量表示。
-
每个向量都与原始文本(或文档)绑定,通过 嵌入模型(如 BERT、GPT 等)转换得到。
-
当查询发生时,查询文本会被转换为向量,并通过向量相似度检索找到与之最相似的文本数据。
-
最终返回的结果是原始文本,而非向量本身。
这样,虽然 Chroma 处理的是向量,但通过将向量与文本绑定,确保了最终可以返回人类可读的文本数据。
基础使用
1. 安装
在终端中运行以下命令来安装 Chroma:
pip install chromadb
2. 创建 Chroma 客户端
在 Python 中导入 Chroma 并创建客户端实例:
import chromadb
chroma_client = chromadb.Client()
3. 创建集合
集合是存储嵌入、文档及其他元数据的地方。它为您的数据创建索引,并实现高效的检索和筛选。您可以为集合指定名称:
collection = chroma_client.create_collection(name="my_collection")
4. 向集合中添加文本文档
将文本文档添加到集合中,Chroma 会自动处理嵌入和索引。您需要为每个文档提供一个唯一的字符串 ID:
collection.add(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
ids=["id1", "id2"]
)
5. 查询集合
您可以通过查询文本列表来检索集合中的最相关文档。Chroma 会返回 n 个最相似的结果:
results = collection.query(
query_texts=["This is a query document about hawaii"], # Chroma 会为您处理嵌入
n_results=2 # 返回的结果数量
)
print(results)
如果未指定 n_results,Chroma 默认返回 10 个结果。在这个例子中,我们只添加了 2 个文档,因此设置了 n_results=2。
6. 检查结果
根据上面的查询,您可以看到关于夏威夷的查询与关于菠萝的文档在语义上最为相似:
{
'documents': [
['This is a document about pineapple', 'This is a document about oranges']
],
'ids': [['id1', 'id2']],
'distances': [[1.0404009819030762, 1.243080496788025]],
'uris': None,
'data': None,
'metadatas': [[None, None]],
'embeddings': None,
}
7. 自己尝试一下
您可以尝试使用不同的查询文本,例如:“This is a document about florida”。
import chromadb
chroma_client = chromadb.Client()
# 使用 `get_or_create_collection` 以避免每次都创建新的集合
collection = chroma_client.get_or_create_collection(name="my_collection")
# 使用 `upsert` 以避免重复添加相同的文档
collection.upsert(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
ids=["id1", "id2"]
)
# 查询 "florida" 相关文档
results = collection.query(
query_texts=["This is a query document about florida"], # Chroma 会为您处理嵌入
n_results=2 # 返回的结果数量
)
print(results)
Chrome客户端
临时客户端
在 Python 中,您可以在内存中运行 Chroma 服务器,并使用临时客户端连接到它:
import chromadb
client = chromadb.Client()
Client() 方法在内存中启动 Chroma 服务器,并返回一个可以连接到它的客户端。
例如,这是在 Python 笔记本中试验不同嵌入函数和检索技术的绝佳工具。如果您不需要数据持久性,则临时客户端是启动和运行 Chroma 的不错选择。
持久客户端
您可以将 Chroma 配置为使用 PersistentClient 从本地计算机保存和加载数据库。数据将自动持久化并在启动时加载(如果存在)。
import chromadb
client = chromadb.PersistentClient(path="/path/to/save/to")
该路径是 Chroma 将其数据库文件存储在磁盘上并在启动时加载它们的位置。如果您未提供路径,则默认为 .chroma。
client 对象有一些有用的便捷方法:
heartbeat()- 返回纳秒心跳。用于确保客户端保持连接。reset()- 清空并完全重置数据库。⚠️ 这是破坏性的,不可逆的。
client.heartbeat()
client.reset()
集合
创建、获取和删除 Chroma 集合
Chroma 集合是使用名称和可选的嵌入函数创建的。如果提供嵌入函数,则必须在每次获取集合时提供该函数。
collection = client 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1218
1218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











