






不知道大家有没有关注最近屡次上微博热搜的青春有你2,你是否被虞书欣这个小作精嗲到,或者是在磕大鱼海棠这对甜甜的cp,脑中是否有“蛋黄的长裙,蓬松的头发”魔性环绕,觉得自己的rap水平也能出道,“结果是一场梦,醒来还是很感动”。。。。。。
想不想知道哪位小姐姐更受欢迎,是你心中pick的那位吗?百度小白逆袭大神训练营来了,手把手教你数据分析!刚开始看到小白两个字,内心颇为激动,哇,我不就是小白本白嘛,结果上了几天课后发现,我可能对小白这个词有误解,整个训练营下来,我的心情如下图
 Day1是乘法表口诀,代码不是很完美,后面有大神在群里分享了一行就能生成,对,没看错就是这么简洁,那种感觉就好比你写了几百字的作文在赞美落日壮观,尤其是落日底下一群鸟飞过时引起的震撼,结果你旁边朋友脱口而出一句“落霞与孤鹜齐飞,秋水共长天一色”时给你的惊艳啊~
Day1是乘法表口诀,代码不是很完美,后面有大神在群里分享了一行就能生成,对,没看错就是这么简洁,那种感觉就好比你写了几百字的作文在赞美落日壮观,尤其是落日底下一群鸟飞过时引起的震撼,结果你旁边朋友脱口而出一句“落霞与孤鹜齐飞,秋水共长天一色”时给你的惊艳啊~
def table():
#在这里写下您的乘法口诀表代码吧!
i=1
while i<10:
j=1
while j<=i:
print('%d*%d=%2d'%(j,i,j*i),end='\t')
j+=1
print(" ")
i+=1
if __name__ == '__main__':
table()
print ('\n'.join('\t'.join(f'{i}*{j}={i*j}' for i in range(1,j+1)) for j in range(1,10)))
day2开始就是爬虫相关的,爬现在很火的青春有你2的小姐姐们百度百科里面的图片。下面的图是爬虫的流程

这里用到BeautifulSoup库,json库等
day3的任务是爬虫数据可视化,将小姐姐的来自哪里,体重分为柱状图或者饼图进行可视化。这里介绍了除了我以前用过比较多的Numpy库,PIL库,Matplotlib库,还介绍一个新库:padas库。下面是它的两个核心结构。
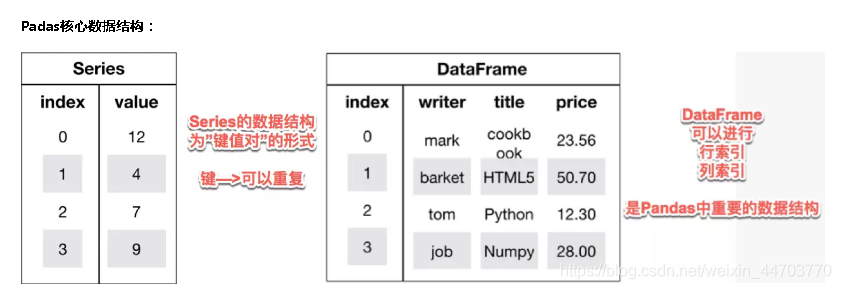
下面用是PD库的两种不同使用方法,前者有点像聚类,后者是分组统计。
df = pd.read_json('data/data31557/20200422.json')
#print(df)
grouped=df['name'].groupby(df['zone'])
s = grouped.count()
c = [0,45,50,55,100]
labels = ['<=45kg','45kg~50kg','50~55kg','55~60kg']
weight1 = pd.cut(weights,c,labels=labels)
day4主要是Paddlehub模型体验,自己制作数据集。利用前两讲的知识爬取图片,制作五个小姐姐的数据集。这一节主要容易出错的是路径和图片问题。数据集爬取后也要再次筛选下,不然最后准确率不高。爬取每人100张图片,按9:1做训练集和验证集,结果不是很好,测试时五个对了三个。据说可以换个模型试试,因为着急交作业就米有整。像许佳琪和安琦确实容易搞混,结果“不负众望”真混了。。。。。。希望公开个满分作业瞅瞅长啥样的
day5简直是小白的灾难现场,爬取评论制作词云。这里代码基本没给,当然晚上直播课老师都讲了下,当然手动疯狂截屏!照着代码抄了一遍,再去评论区晃了晃,嗯,给推荐下AIstudio的评论区是真好用,各种坑集中营哈。最大的坑是字体装不上去,优秀的小伙伴们提出day3作业的开头就有如何装,捣鼓了很久才装上:照着写了又刷新又重启还是不行,就这么折腾几次,结果自动好了。。。爬取了1500多评论,生成的词云图

这节课作业就75分吧,所以有点好奇满分作业是咋做得,毕竟考完试的人还是想看看标准答案的!
结营总结一句话:道路是崎岖的,过程是曲折被虐的,成长是也是有的!!!
最后,附上青春有你2中两个漂亮小姐姐合照生成漫画脸的产品体验




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









