







发表会议:2021 ACCESS
1.Abstract
提出LogM框架,利用深度学习,知识图谱技术对Hadoop集群进行故障与预测分析。
开发一个基于注意力的双向长短期(Bi-LSTM)架构的CAB网络,有效的从日志数据中学习时间动态,预测系统状态。
使用知识图谱方法进行故障分析与诊断。
进行大量实验评估性能,
2.Intuoduction
Motivation1:hadoop的设备通常分布在许多地方,由于单一设备容量有限,因此很容易出现故障,一个设备的故障可能会传播到其他部分,并最终导致整个系统全局中断。随着规模和系统复杂度的不断增加,Hadoop平台的管理和运维难度也越来越大。
Motivation2:日志数据是非结构化的,具有多种格式,包括文本、日期和数字。Hadoop系统日志的异构性使其难以理解和分析,并且平台由多个硬件节点组成,每秒可能会产生大量的日志,因此需要实时处理。
Motivation3:涉及多个组件的系统故障通常比单个组件的系统故障更为复杂。需要成本非常高的标记工作。
LogM框架:
- LogM 及时预测和诊断系统故障,允许操作员立即采取措施避免系统中断。
- LogM不仅分析单个组件相关的故障,还分析涉及多个组件的故障,更符合实际场景。
- LogM 采用 CNN 提取日志的语义信息,并利用基于注意力的 Bi-LSTM 从顺序日志数据中提取时间动态。 通过使用端到端模型,LogM 可以自动从历史系统日志中学习并预测之后是否会发生故障。
- LogM采用知识图谱来刻画不同异常日志之间的关系,从而有效地辅助操作人员诊断系统故障。
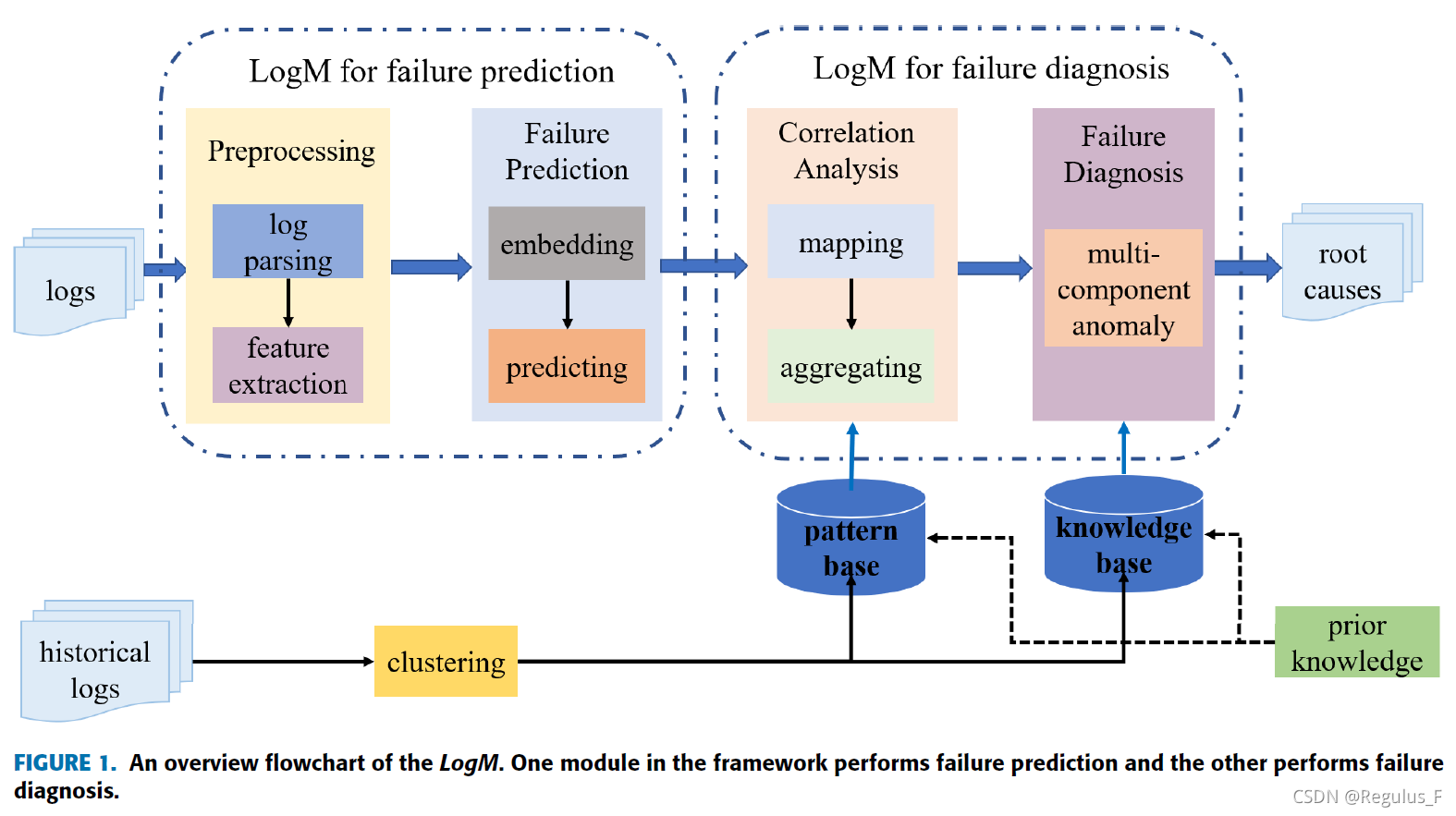
3.The details of LogM
3.1 故障预测
3.1.1数据预处理
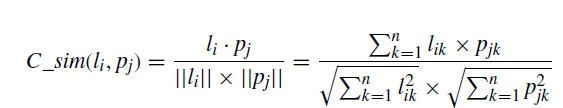
衡量两个日志的相似程度。对于每个日志,我们计算它与现有集群之间的相似度 C_sim。 我们找出所有现有的相似度超过预定阈值的集群,并将相似度最大的集群作为最近的集群。 如果没有相似度超过预先定义的阈值,我们以对应的日志作为代表日志创建一个新的集群。
自动确定预先定义的阈值,首先计算每两个样本之间的余弦距离。然后使用KMeans将余弦距离聚类为两个聚类。然后计算这两个集群的平均值,均值较小的集群,取其中最大值,表示为t1。均值较大的集群,取其中的较小值,表示为t2。最后从t1与t2中选择一个阈值,实验中将t1设置为预先定义的阈值。
3.1.2 故障预测
对于一个日志集合L,使用如下的步骤来训练失败检测模型。
1)划分时间窗口,l(a),…l(n),tw为时间窗口的大小
2)对组内的每个日志进行模板匹配,借助预处理阶段获得的日志模板组,记为p(a)…p(n)
3)使用日志模板组训练CAB进行系统故障预测。
图2为CAB的示意。
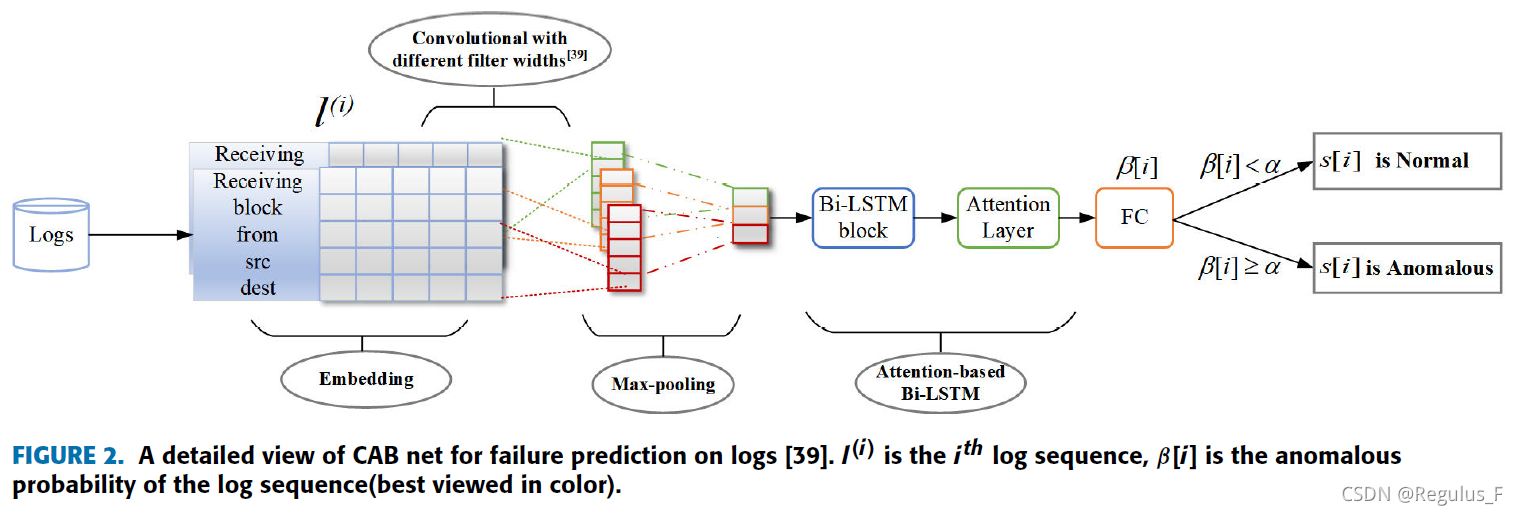
训练过程中,包含错误信息的日志组被定义为故障组,记为l(a),正常的日志组记为l(n),该CAB网络利用具有基于注意力的Bi-LSTM的CNN对系统日志进行建模,可以自动提取日志的语义信息并捕获顺序日志数据的时间动态。

3.2 故障诊断
3.2.1 相关性分析
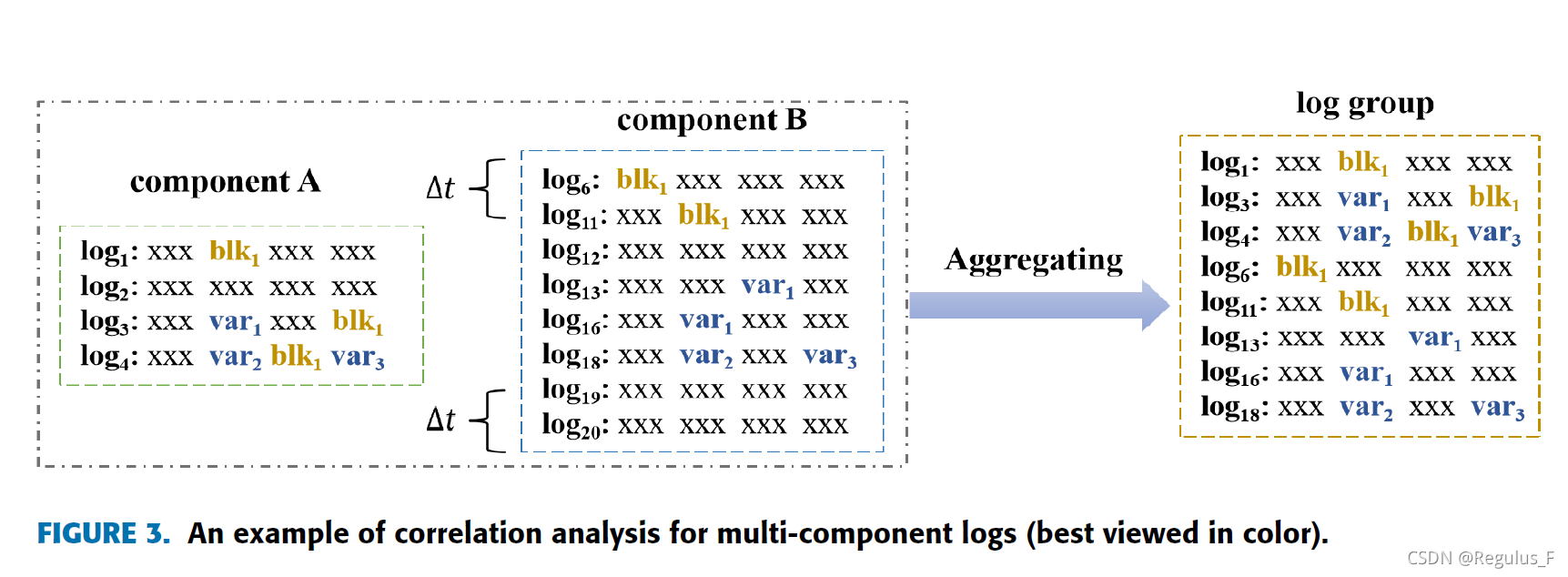
由于网络断开或吞吐量受限,会导致日志丢失、日志重复、日志混乱等一系列问题。因此我们将相关的日志聚合在一个组中,以帮助用户在识别出故障之后更准确的诊断故障。为了正确聚合来自同一故障中涉及的不同组件的日志,文章同时使用时间特征和关键字特征。在将日志聚合到候选组后,我们使用提升置信度来过滤掉相关性不强的日志组。
1)Mapping:首先将模板内的日志向量映射到类别,并使用相应的标签来表示模板。使用one-pass聚类算法构建一个异常日志的类别库,每个类别库代表一个组件内的一类异常日志模板。我们为不同的组件分配不同的标签,如Hive-A、HBase-B、HDFS-C等。并使用不同的标签来表示组件内不同的模板类别,如Class1、Class2、Class3等。于是就可以得到A-2,C-1等标签。

2)Aggregating:将每个日志映射到相应的模板之后,使用模板内的时间戳和标签生成元组,如上表所示,时间戳来自系统日志,关键字由标识符和变量组成,标识符用于标识程序使用的对象,变量用与枚举标识符一组可能的状态。具有共同标识符的日志很可能来自同一事件并具有很强的相关性。一段时间内具有共同变量的日志可能来自同一事件并具有很强的相关性。我们将具有共同标识符或变量的聚合为[Tstart,Tend]。如图所示,AB两个组件中,将具有blk和var的日志聚合在一起。
3.2.2 故障诊断
由于诊断故障需要时间,因此系统服务可能会中断,从而导致严重损失。
于是本文旨在预测系统故障并提前提供合理的解决方案。一旦预测到故障,无需等待收集所有的日志就进行诊断。
hadoop中,各个组件之间存在依赖关系,一个组件引起的故障会导致其他相关组件报错,本文提供两种方法,一种是无监督学习,一种是监督学习方法。
3.2.2.1 无监督学习
测量异常日志组和知识库日志的成对相似性。计算不同日志之间的相似性,将多个相关的日志映射到向量中,对于异常知识库,l1,l2…ld被转换为d个n维向量,即k1,k2…kd。异常日志组g中的m个向量g1,g2…gm被转换成m个n维向量v1,v2…vm,其中n是bag-of-word模型生成的字典的大小。计算向量的TF-IDF值。
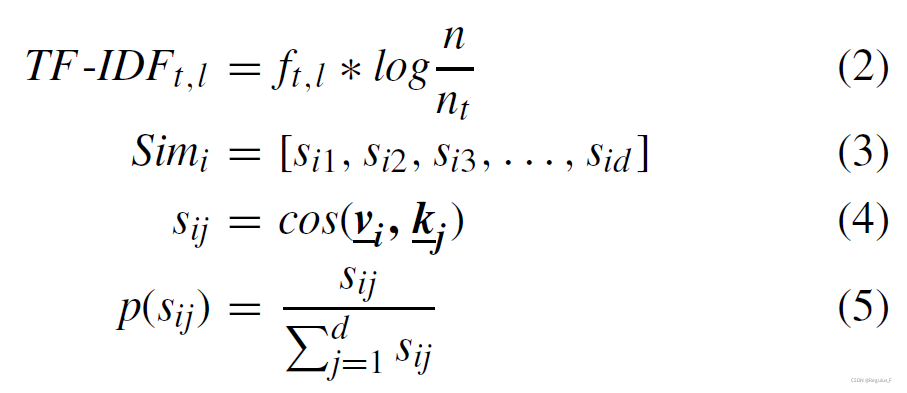
其中t表示词项t在日志中出现的频率,n表示日志的总数,nt表示包含词项t的日志数。
计算g中每个日志与知识库中的每个日志之间的成对相似度,得到一个d维的相似度向量。simi表示g中第i个日志的相似度向量。
sij可以计算vi与kj的想余弦相似度向量,vi是g中第i个对数向量,kj是知识库中第j个对数向量。
为了有效的选择每个异常日志组的根本原因,从相似性列表中分析每个Simi。
首先使用相似性列表和异常知识图谱构建多层加权无向图。
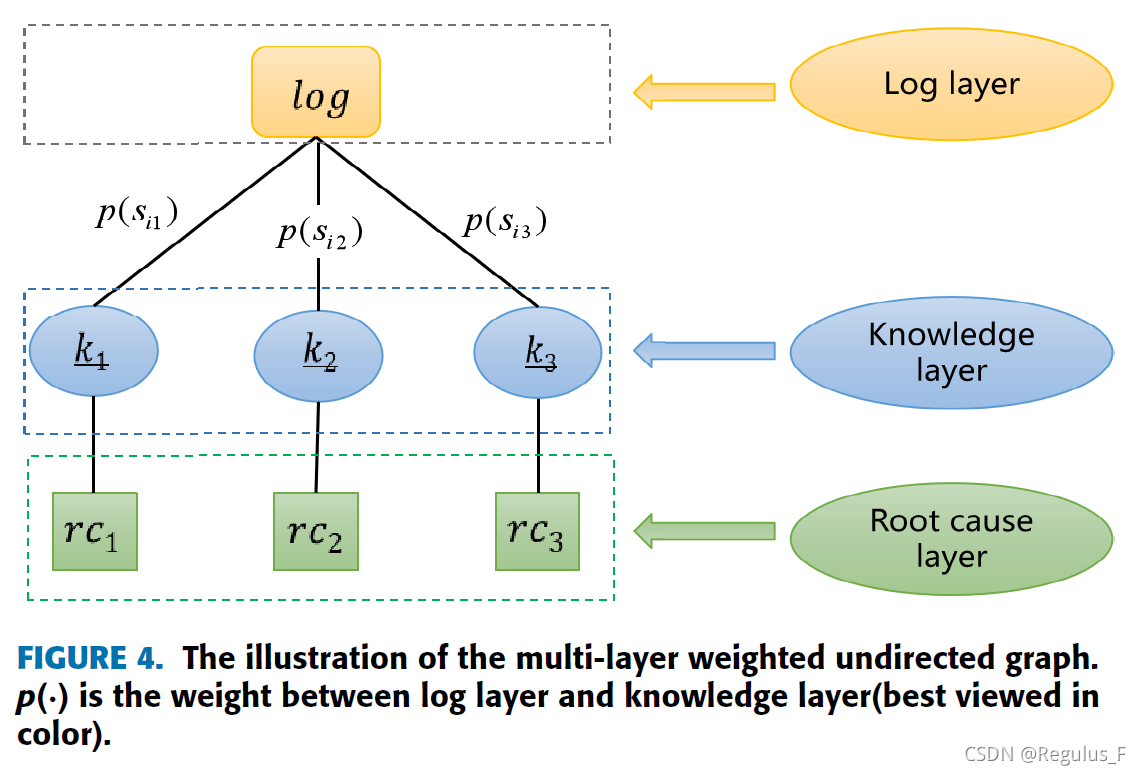
如图所示,主要包括三层,分别是日志层、知识层和原因层,log为需要分析的日志,ki表示知识库中的日志,rci表示对应的根本原因。两层中间的权重p表示ki对应日志的概率。通过上式5进行计算。基于多层加权无向图,我们提出两种推断候选根本原因的方法。
1)从知识库中选择与每个异常日志组最相似的前n个日志,计算每个相关原因的出现次数,选择最频繁的一个作为根本原因。
2)找见最常见的原因之后,按照根原因进一步对n个日志的p(·)求和,并取p(·)之和最大的根本原因作为候选根本原因。
3.2.2.2 有监督学习
本质上每个异常日志组都是由一个故障引起的,有监督最终目标是在根本原因和事件之间建立合理的映射,本文使用Siamese LSTM网络来比较日志序列。
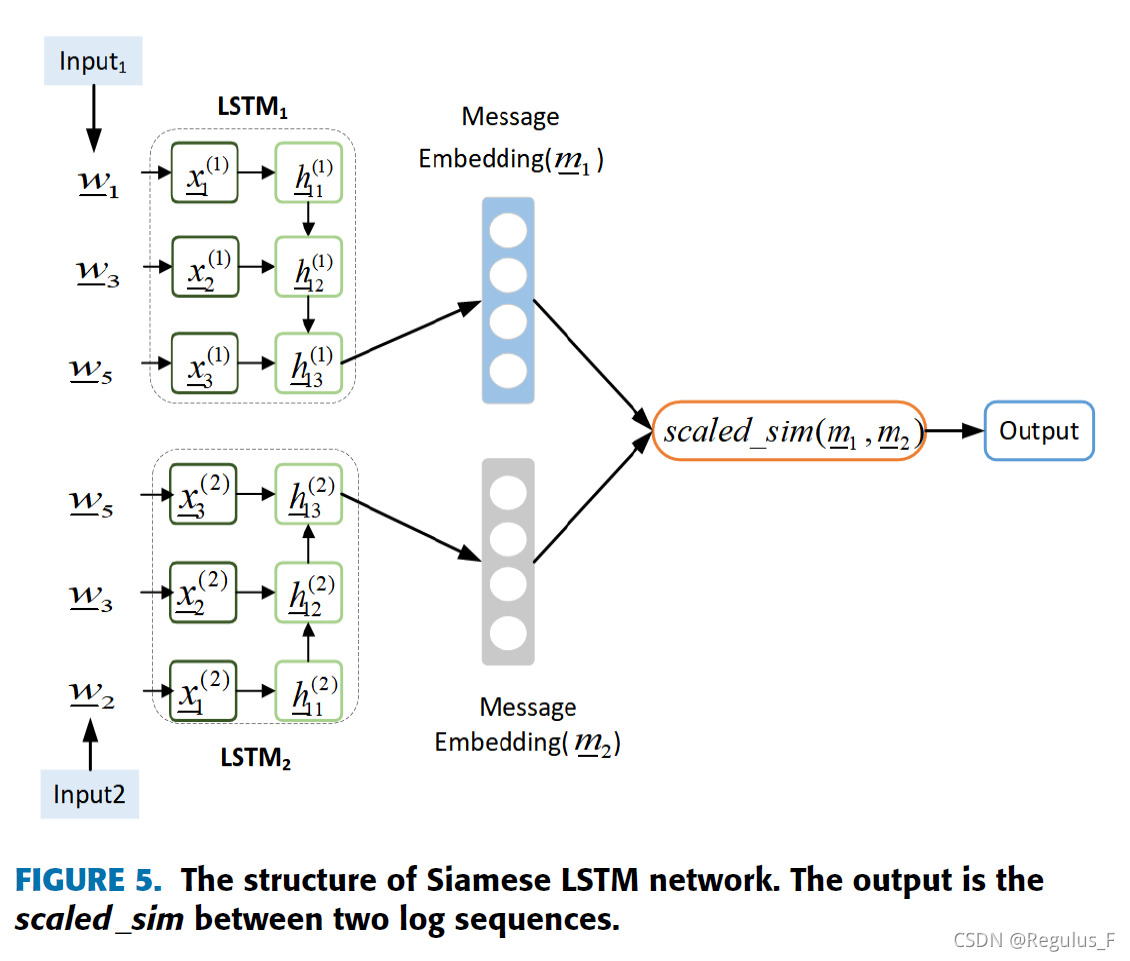
与其他神经网络不同,Siamese网络再输入层需要配对数据,来自异常组和知识库的日志序列按照顺序同时输入到Siamese LSTM中,如图五所示,li表示知识库的第i个日志,gi表示异常组g中的第i个日志,wi表示通过word2vec模型训练得到的对应词向量。
计算两个输入之间的距离以确定它们是否由同一个故障引起。为了衡量相似性,引入一个scaled_sim的度量,即(6)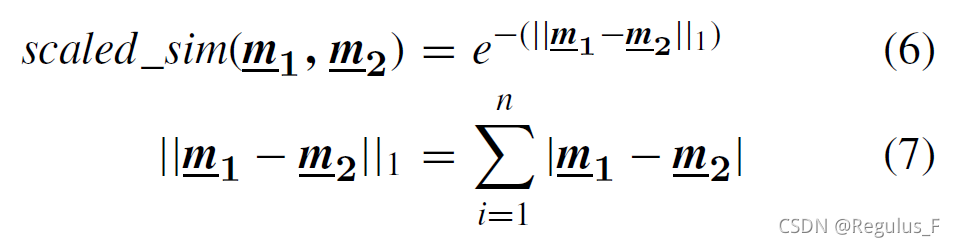
其中m1,m2分别代表最后一个隐藏的神经元的输出。Siamese网络中的两个LSTM自网络共享相同的权重,可以有效的减少训练参数的数量,提高计算能力和存储性能。
算法流程:

首先使用历史系统日志训练word2vec模型以获得相应的词向量。然后将相应的词向量输入Siamese LSTM网络,通过(6)(7)所示的scale_sim计算相似度。最后分析相似性获得根本原因。本文中使用word2vec模型主要基于连续词袋模型CBOW,它试图根据上下文预测当前词,
等式(8)为CBOW模型的目标函数,其中wt为当前词,ct为上下文。
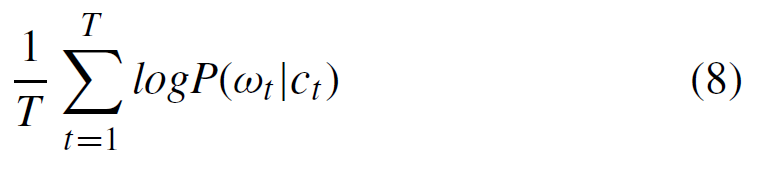
对于上述两种故障诊断方法,都旨在测量日志之间成对相似性。无监督诊断方法简单有效,但再诊断性能上略逊于有监督的诊断方法。有监督的诊断方法,在诊断方面表现更好,但由于需要对训练数据进行标记,它通常耗时且成本高。
3.2.3 异常知识图谱
对于系统故障诊断,需要一个包含 Hadoop 平台的各种根本原因和异常事件的知识库。 在本文中,我们建议使用知识图来存储根本原因和异常事件。
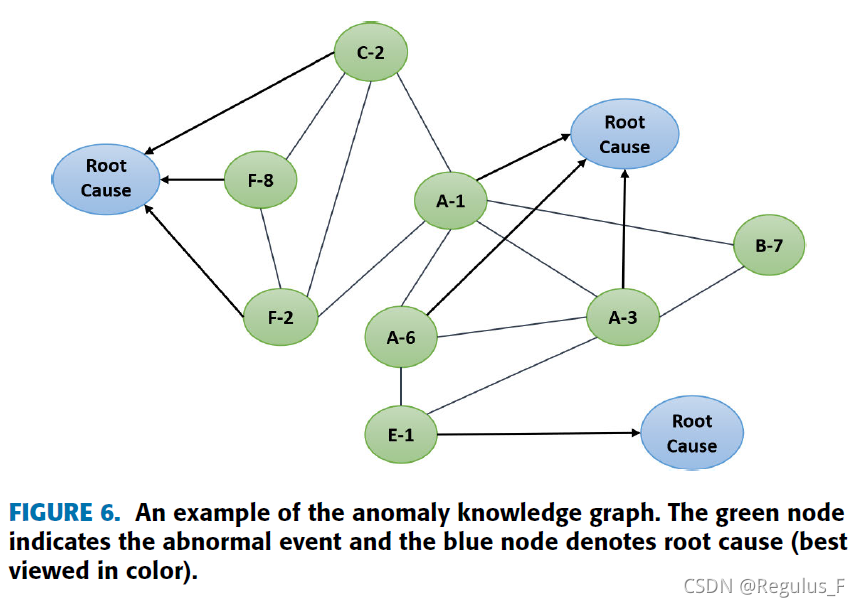
如图所示,绿色节点表示异常事件,蓝色节点表示根本原因,相关的绿色节点之间以无向边相连,与根本原因通过有向边相连,表示异常事件是由根本原因引起的。
4.实验
4.1 数据集
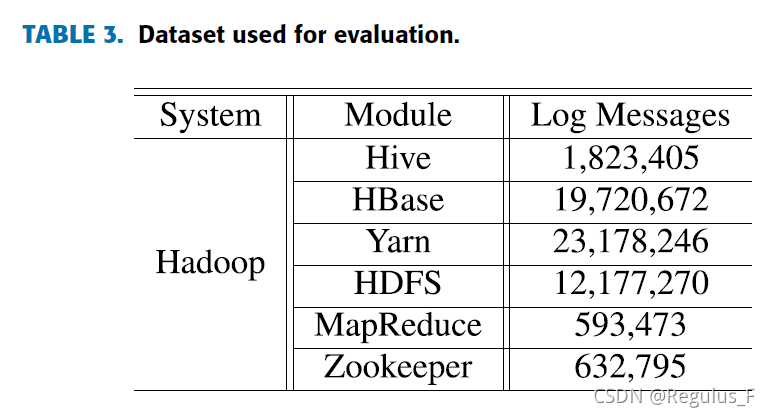
从hadoop平台的四个节点中收集的日志,总计超过五千万条,涵盖Hadoop系统的六个不同组件,Hive,Hbase,Yarn,HDFS,MapReduce,Zookeeper。包含四个级别的日志,INFO、WARN、ERROR 和 FATAL。
4.2 实验结果
4.2.1 日志聚类算法的性能比较
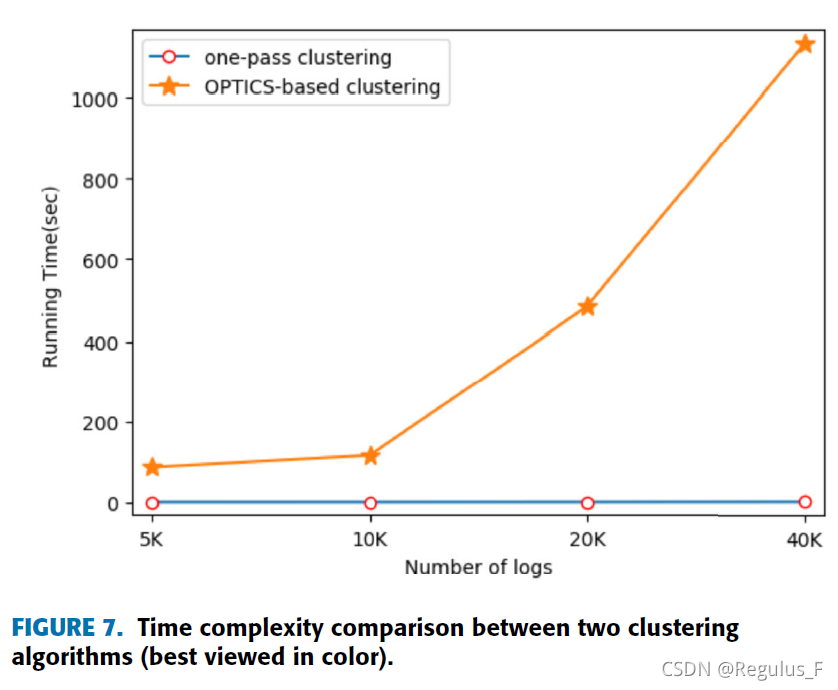
与OPTICS聚类算法的比较。
4.2.2 故障预测算法的性能比较
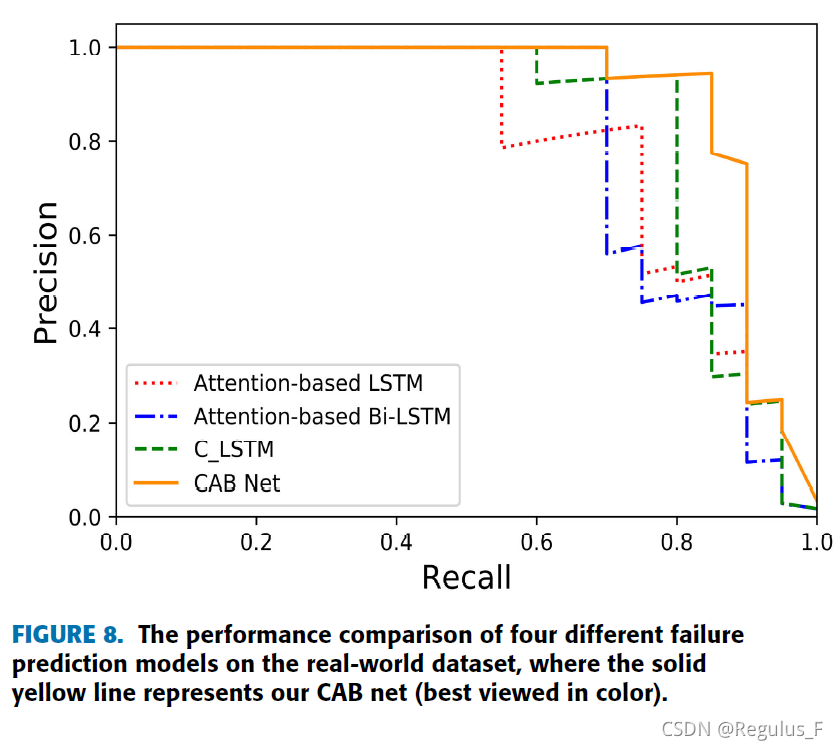
4种网络的比较,作者提出的网络效果最好。
4.2.3 故障诊断方法的性能比较
n为topn
图9是两种无监督方法的性能比较,随着n的增加,无监督方法2的性能逐渐优于无监督方法1。
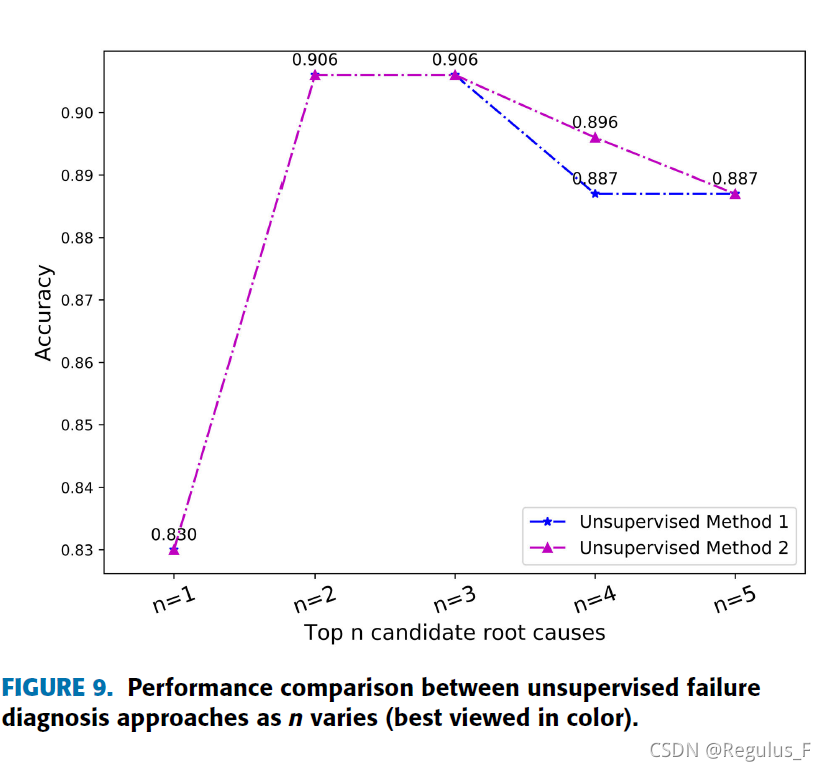
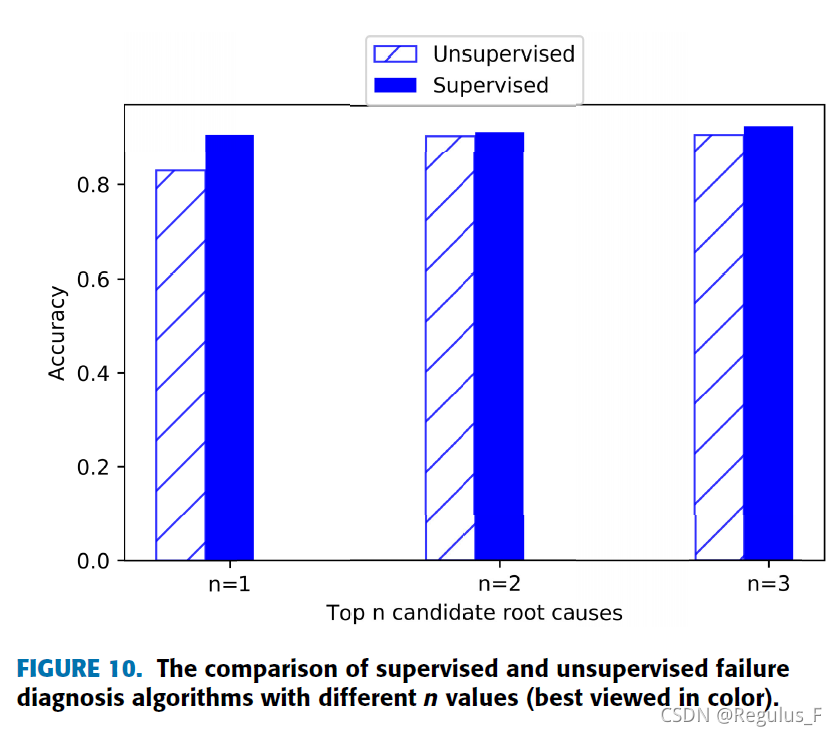
图10是无监督方法与有监督方法的比较。随着n的增加,方法2的性能变的略好于无监督方法1。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









