







 本文深入探讨Solr和Lucene在全文检索领域的应用,解析两者之间的本质区别,以及如何利用Solr解决传统数据库模糊查询效率低的问题。通过具体实例,讲解Solr的安装、配置及中文分词器的设置。
本文深入探讨Solr和Lucene在全文检索领域的应用,解析两者之间的本质区别,以及如何利用Solr解决传统数据库模糊查询效率低的问题。通过具体实例,讲解Solr的安装、配置及中文分词器的设置。
前言
在使用传统数据库(例如Mysql)做模糊查询的时候,相信有经验的朋友都知道,如果使用%content%的方式进行模糊查询,一旦数据量变大,搜索速度会变得很慢,此时可能大家都会想到用索引来解决这个问题。
但是,这种模糊查询的方式会走索引么?答案显然是否定的,因为索引有个原则 “最左匹配原则”,而%是不会走索引的,因此该sql语句执行之后会全表扫描,这种方式显然是不可取的… 但有什么办法,既可以满足模糊查询(%content%的形式),又可以增加查询效率呢?
答案就是Solr!
什么是Solr
我们先来看看度娘上是怎么介绍Solr的。
Solr是一个高性能,采用Java开发基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。Solr是基于Apache Lucene ™构建的流行,快速,开源的企业搜索平台。它并不是apache的顶级项目,而是lucene一个子项目而已

用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件或者Json格式字符串,生成索引,也可以通过http get操作提出查找请求,并得到XML或者Json格式的返回结果。而XML文件和Json本质上都是由字符串构成的,因此Solr具有天然的跨平台特性。
什么是Lucene
刚才提到说Solr是采用Java开发基于Lucene的全文搜索服务器,那么Lucene又是何方神圣呢?
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工
具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索
引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个
简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文
检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。
Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是
一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程
序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相 混淆。
说白了,Lucene就是一个用来实现搜索功能的库,它内置了大量的算法,在搜索使用这个算法,能加快检索速度。这种感觉就像是C++和Python,大家应该都知道现如今很火爆的人工智能基本上都是由Python撰写的,但是人工智能的很多算法并不是由Python编写的,而是C++,Lucene其实也就是算法库,储存了大量的检索算法,而Solr就是面向企业应用的独立的应用程序,Lucene更偏向于底层。
Solr 和 Lucene 的区别
Solr和Lucene的本质区别有以下三点:
| Lucene | Solr |
|---|---|
| 本质上是搜索库 | 是独立的应用程序 |
| 专注于搜索底层的建设 | 专注于企业应用 |
| 不负责支撑搜索服务所必须的管理 | 负责支撑搜索服务所必须的管理 |
因此,Solr可以算是是Lucene面向企业搜索应用的扩展
Solr的安装
介绍了这么多,其实Solr就是一个专业的搜索服务器 Solr Download
配置java环境变量
下载请戳 Linux JDK Download ,记得下载后缀为tar.gz的包哦!
第一步:下载linux版本JDK


第二步:使用XFTP传到Linux并解压
接着我们在Linux下的下创建/download目录,并借助XFTP将文件传到此目录
然后使用以下指令将文件解压到usr/local/java
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /usr/local/java/
第三步:配置环境变量
通过vi /etc/profile指令在最后添加以下配置,这里的JAVA_HOME和Window是一样的,也就是jdk中存放bin(可执行文件)子目录的根路径,下面的写法就是固定的了。
JAVA_HOME=/usr/local/java/jdk1.8.0_181
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export PATH
export CLASSPATH
注意配置完成之后要使用source /etc/profile刷新/etc/profile配置文件
第五步:测试
输入java -version,测试,如果jdk安装配置成功之后,会得到如下结果

安装Solr
第一步:下载Solr的压缩包
这里我就直接使用wget啦!大家也可以点击 Solr Download 下载,使用Xftp将文件导入到Linux文件夹中
#创建solr文件夹
mkdir /usr/local/solr
cd /usr/local/solr
#下载solr至该文件夹中
wget http://mirror.bit.edu.cn/apache/lucene/solr/7.7.2/solr-7.7.2.tgz
第二步:解压Solr压缩包
tar -zxvf solr-7.7.2.tgz
解压完成之后的目录分析如下
| 目录名称 | 解释 |
|---|---|
| Bin | 可执行脚本 |
| Contrib | 给Solr额外添加功能的 |
| Dist | Solr的依赖包 |
| Docs | 文档 |
| Server | Solr 服务器的目录 |
第三步:Solr的启动和关闭
Solr的启停命令很简单,./solr start为启动,./solr stop为停止,./solr restart为重启。注意了,在root 用户里面,solr 要启动必须添加 -force。
[root@localhost bin]# ./solr start -force
*** [WARN] *** Your open file limit is currently 1024.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
*** [WARN] *** Your Max Processes Limit is currently 3795.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
NOTE: Please install lsof as this script needs it to determine if Solr is listening on port 8983.
Started Solr server on port 8983 (pid=7661). Happy searching!
第四步:测试
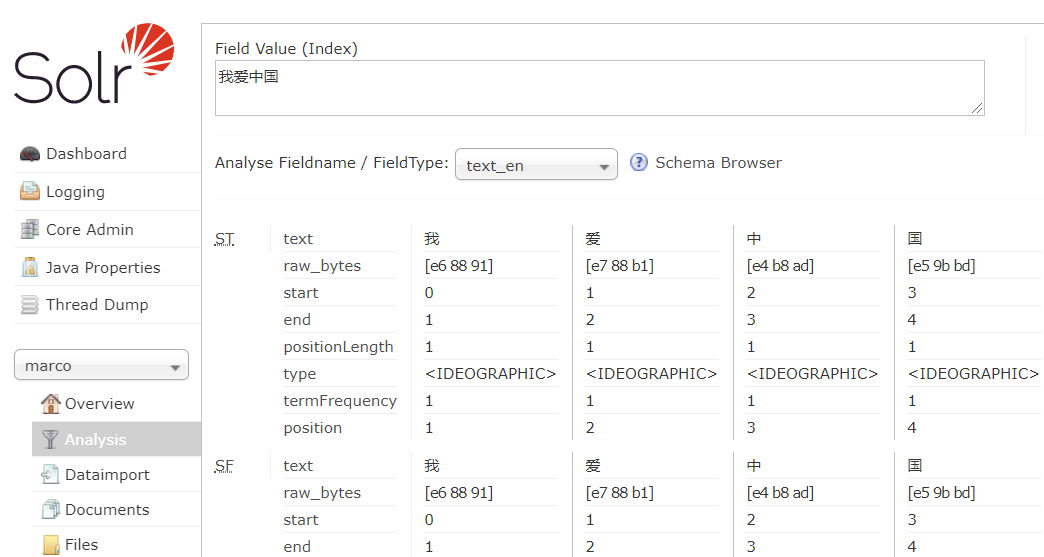
不难发现 “我爱中国” 被拆分成了4个词?但是这样分词并检索没有一点意义
大家可以点击Analyse Fieldname / FieldType,并没有找到text.cn(中文分词器)?是不是很坑?
第五步:配置ik 分词器(最好的中文分词器)
咱们先准备ik的资源,分词器下载请戳 IK Download

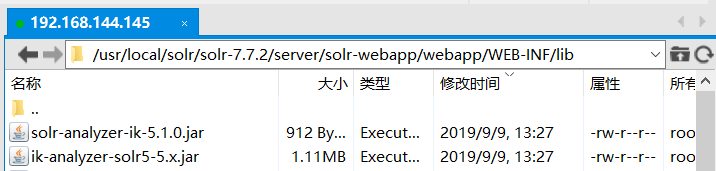
下载好之后,使用Xftp将ik包中的下面两个jar包放入solr-wepapp/webapp/WEB-INF/lib中
第六步:配置扩展,停词
接着我们新建一个classes文件夹(代表java 编译后的jar ,或者需要的xml文件)
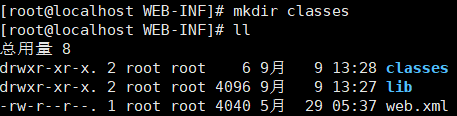
使用Xftp将ik包中剩余的三个文件放入新建好的classes文件夹中
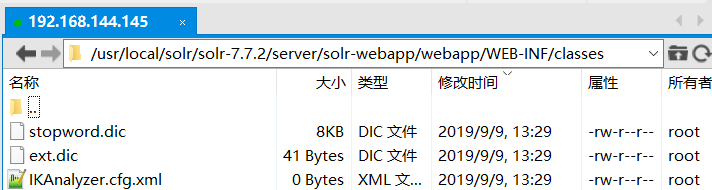
接着通过cd /usr/local/solr7/solr-7.7.2/server/solr/{ego:库的名称}/conf指令进入修改配置文件的目录中,并找到配置文件managed-schema,新增text_cn字段类型
[root@localhost conf]# cd /usr/local/solr/solr-7.7.2/server/solr/marco/conf/
[root@localhost conf]# ll
总用量 132
drwxr-xr-x. 2 root root 4096 9月 9 12:48 lang
-rw-r--r--. 1 root root 54513 5月 17 06:55 managed-schema
-rw-r--r--. 1 root root 308 5月 17 06:48 params.json
-rw-r--r--. 1 root root 873 5月 17 06:48 protwords.txt
-rw-r--r--. 1 root root 53986 5月 17 06:55 solrconfig.xml
-rw-r--r--. 1 root root 781 5月 17 06:48 stopwords.txt
-rw-r--r--. 1 root root 1124 5月 17 06:48 synonyms.txt
使用vim managed-schema指令修改配置文件,加入以下ik的中文配置
<!-- Chinese -->
<dynamicField name="*_txt_cn" type="text_cn" indexed="true" stored="true"/>
<fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false"/>
</analyzer>
</fieldType>
第七步:重启solr
执行./solr restart -force重启Solr
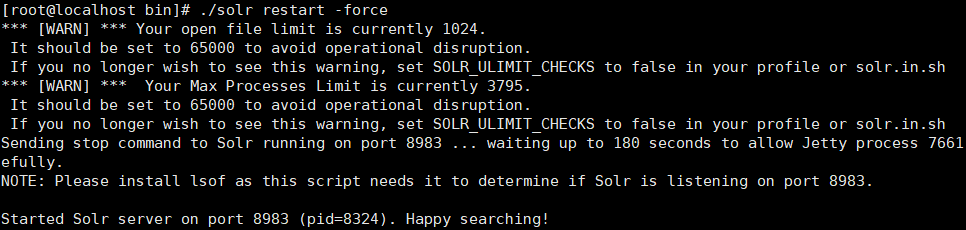
此时,我们搜索text_cn就可以搜索到中文分词啦!
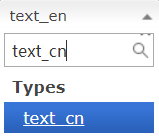
再来执行分词,发现 “我爱中国” 被拆分为 “爱” 和 “中国” 了!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









