







 本文深入解析Spark在不同资源管理器下的运行模式,包括standalone、localCluster、sparkonYarn和sparkonmesos,探讨各自的特点及应用场景。重点阐述了yarn-cluster与yarn-client模式的差异,以及sparkonmesos的调度模式。同时,详细解释了driver的作用及其在yarn模式下的运行位置。
本文深入解析Spark在不同资源管理器下的运行模式,包括standalone、localCluster、sparkonYarn和sparkonmesos,探讨各自的特点及应用场景。重点阐述了yarn-cluster与yarn-client模式的差异,以及sparkonmesos的调度模式。同时,详细解释了driver的作用及其在yarn模式下的运行位置。
这里先主要理解spark运行在四种资源管理器下的模式
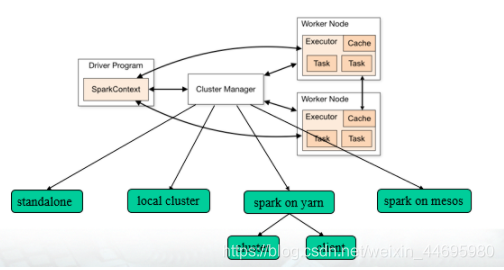
上图为spark的架构图,spark的组件可以分为三个部分,driver、cluster Manager、worker(executor)
standalone模式:
standalone模式是独立模式,自带完整服务,可单独部署到一个集群中,无需依赖其他任何资源管理系统,只支持FIFO调度器。从一定程度上说,它是spark on yarn 和spark on mesos 的基础。在standalone模式中,没有AM和NM的概念,也没有RM的概念,用户节点直接与master打交道,由driver负责向master申请资源,并由driver进行资源的分配和调度等等。
local Cluster模式
standalone模式的单机版,master和worker分别运行在一台机器的不同进程上 (eg:windows环境下可以设置单机模式)
注释:如果在windows模式下 设置的是local模式,那么在IDEA环境中打成jar上传到集群,spark-submit 提交时如果设置的
–master 运行在其他资源环境下,那么就以提交的为准,它会覆盖程序中设置的local模式。
spark on Yarn模式:
这种部署模式,在工作中基本都用这种YARN的模式。但限于YARN自身的发展,目前仅支持粗粒度模式(Coarse-grained Mode)。这是由于YARN上的Container资源是不可以动态伸缩的,一旦Container启动之后,可使用的资源不能再发生变化,不过这个已经在YARN计划中了。 spark on yarn 的支持两种模式:
(1) yarn-cluster:适用于生产环境;(2) yarn-client:适用于交互、调试,希望立即看到app的输出:比如看日志,其中有一些中型或者小型公司也会在生产环境中用这种模式。
yarn-cluster和yarn-client的区别在于yarn appMaster,每个yarn application实例有一个appMaster进程,是为application启动的第一个container;负责从ResourceManager请求资源,获取到资源后,告诉NodeManager为其启动container。yarn-cluster和yarn-client模式内部实现还是有很大的区别。如果你需要用于生产环境,那么请选择yarn-cluster;而如果你仅仅是Debug程序,可以选择yarn-client。
Spark on yarn的 两种运行模式和运行原理:
1、在MapReduce中,计算的最上层单元是是job,系统加载数据,执行一个map函数,shuffle数据,执行一个reduce函数,然后将数据写回到持久化存储器,Spark有一个类似job的概念(虽然一个job可以由多个stage组成,而不是仅仅只包含map和reduce),不过Spark还有一个更高层级的概念叫做应用程序(application),应用程序可以以并行或者串行的方式跑多个job。
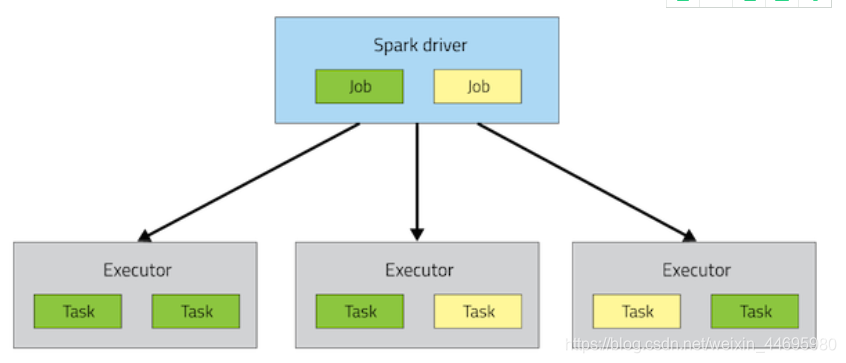
2、熟悉Spark API的人都知道,一个应用程序对应着一个SparkContext类的实例。不同于MapReduce,一个应用程序拥有一系列进程,叫做executors,他们在集群上运行,即使没有job在运行,这些executor仍然被这个应用程序占有。这种方式让数据存储在内存中,以支持快速访问,同时让task快速启动成为现实。
spark on mesos模式:
1、这是很多公司采用的模式,官方推荐这种模式(当然,原因之一是血缘关系)。正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。目前在Spark On Mesos环境中,用户可选择两种调度模式之一运行自己的应用程序(可参考Andrew Xia的“Mesos Scheduling Mode on Spark”):
粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。举个例子,比如你提交应用程序时,指定使用5个executor运行你的应用程序,每个executor占用5GB内存和5个CPU,每个executor内部设置了5个slot,则Mesos需要先为executor分配资源并启动它们,之后开始调度任务。另外,在程序运行过程中,mesos的master和slave并不知道executor内部各个task的运行情况,executor直接将任务状态通过内部的通信机制汇报给Driver,从一定程度上可以认为,每个应用程序利用mesos搭建了一个虚拟集群自己使用。
2、细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。与粗粒度模式一样,应用程序启动时,先会启动executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,mesos会为每个executor动态分配资源,每分配一些,便可以运行一个新任务,单个Task运行完之后可以马上释放对应的资源。每个Task会汇报状态给Mesos slave和Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于MapReduce调度模式,每个Task完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
关于driver的理解
首先不知道这个main函数指的是什么,是像C语言中的main函数一样吗,其次看到那句create context让我想到的是源码中有一段代码在某个场合创建了一个driver然后在driver里面创建的context,但看了两天的代码以后,发并没有找到。思考了很久以后才明白driver是什么意思:
用户提交的应用程序代码在spark中运行起来就是一个driver,用户提交的程序运行起来就是一个driver,他是一个一段特殊的excutor进程,这个进程除了一般excutor都具有的运行环境外,这个进程里面运行着DAGscheduler Tasksheduler Schedulerbackedn等组件。
这段计算π值的程序代码在spark上运行起来就是一个driver,可以看到这段程序里有个main函数,它是整个应用程序的开始,也可以看到在这段代码中创建了context,这样与官网给的解释就完全对上了。
Q:一个应用程序是如何与一个driver一一对应的呢,在worker.scala中我们找到了创建driver的代码,一步步往上追溯就能发现一个Driver如何与一个应用程序一一对应起来的
driver的作用:
运行应用程序的main函数
*创建spark的上下文
*划分RDD并生成有向无环图(DAGScheduler)
*与spark中的其他组进行协调,协调资源等等(SchedulerBackend)
*生成并发送task到executor(taskScheduler)
driver运行在哪里(在这里只讨论yarn模式)
官网上说:There are two deploy modes that can be used to launch Spark application on Yarn.In cluster mode,the Spark driver run inside an application master process.And in the client mode,the driver runs in the client process.
yarn-cluster模式下,client将用户程序提交到到spark集群中就与spark集群断开联系了,此时client将不会发挥其他任何作用,仅仅负责提交。在此模式下。AM和driver是同一个东西,但官网上给的是driver运行在AM里,可以理解为AM包括了driver的功能就像Driver运行在AM里一样,此时的AM既能够向AM申请资源并进行分配,又能完成driver划分RDD提交task等工作
yarn-client模式下
yarn-client模式下,Driver运行在客户端上,先有driver再用AM,此时driver负责RDD生成、task生成和分发,向AM申请资源等 ,AM负责向RM申请资源,其他的都由driver来完成
总结
用户提交的程序运行起来就是一个driver,他是一个一段特殊的excutor进程,这个进程除了一般excutor都具有的运行环境外,这个进程里面运行着DAGscheduler Tasksheduler Schedulerbackedn等组件
yarn-Cluster模式下driver运行在AM里,这个AM既完成划分RDD生成有向无环图提交task等任务也负责管理与这个application运行有关的executor
yarn-Client模式下由AM负责管理excutor其余的由driver完成。

















 4428
4428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









