







1、下载并解压spark包,注意要和hadoop版本适配。
[root@hadoop01 software]# tar -xzvf spark-3.2.0-bin-hadoop2.7.tgz -C /export/servers/

2、修改配置文件。

[root@hadoop01 conf]# vim spark-env.sh
#配置java环境变量
export JAVA_HOME=/export/servers/jdk
#指定Master的IP
export SPARK_MASTER_HOST=hadoop01
#指定Master端口
export SPARK_MASTER_PORT=7077

[root@hadoop01 conf]# scp -r /export/servers/spark/ hadoop02:/export/servers/
[root@hadoop01 conf]# scp -r /export/servers/spark/ hadoop03:/export/servers/
3、测试服务。

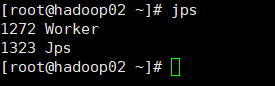
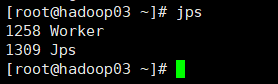
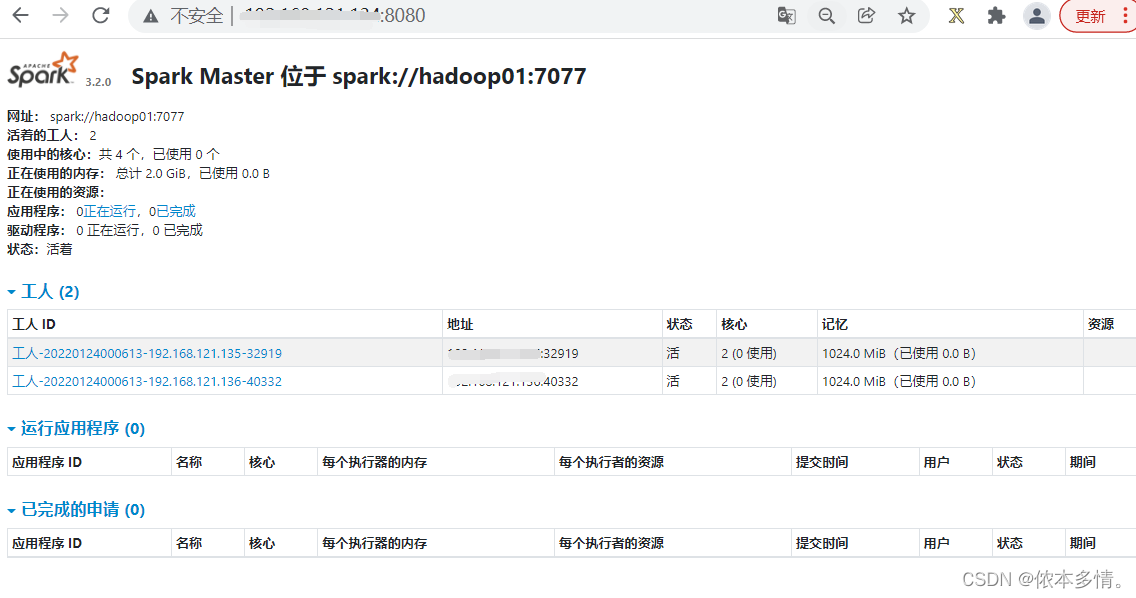
4、配置高可用spark。
添加环境变量
export SPARK_HOME=/export/servers/spark
export PATH=$PATH:$SPARK_HOME/bin
修改配置文件,注销指定IP,添加如下内容。
[root@hadoop01 conf]# vim spark-env.sh
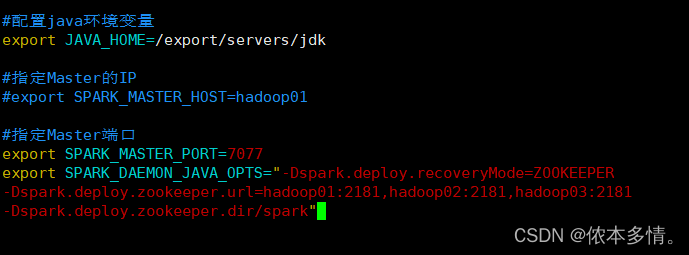
[root@hadoop01 conf]# scp spark-env.sh hadoop02:/export/servers/spark/conf/
spark-env.sh 100% 4778 5.2MB/s 00:00
[root@hadoop01 conf]# scp spark-env.sh hadoop03:/export/servers/spark/conf/
spark-env.sh
5、测试高可用spark。
各节点zkServer.sh start启动zookeeper
然后启动spark

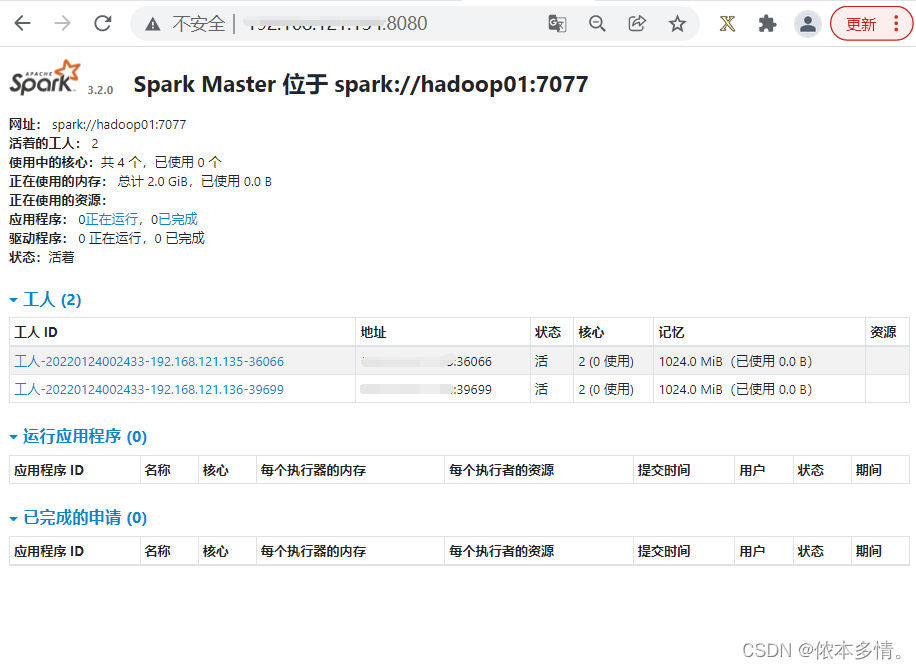
在hadoop02中单独启动master服务,因为现在mater服务在hadoop01中式alive的,所以这一部分是standby,随时准备好当hadoop01故障时进行转换。

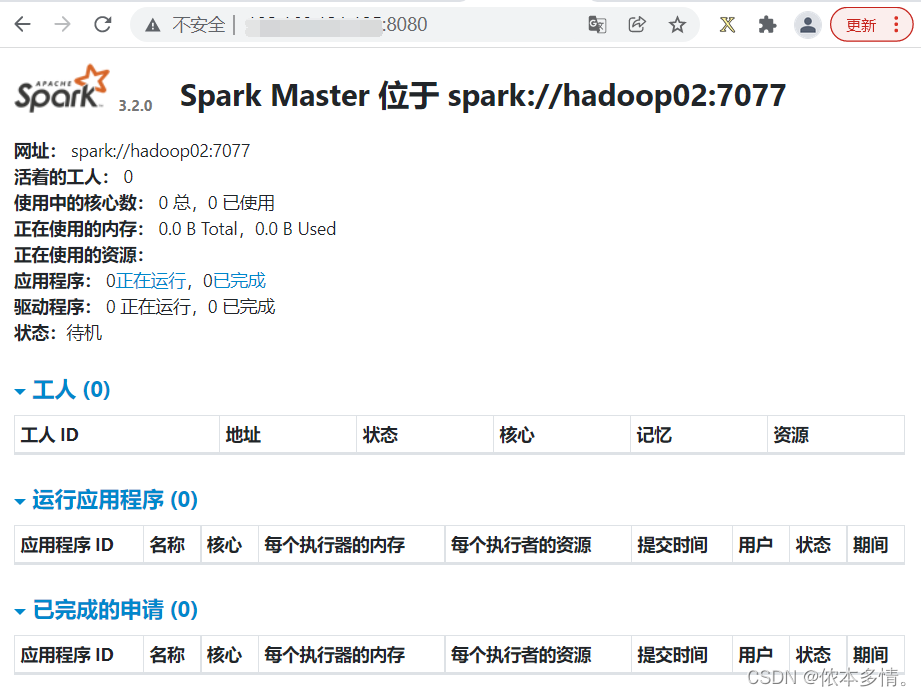
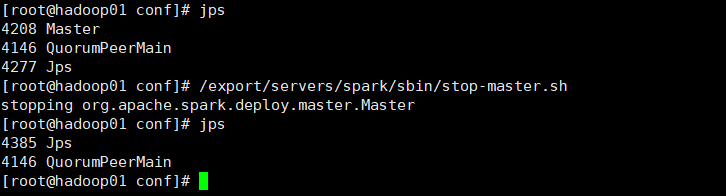
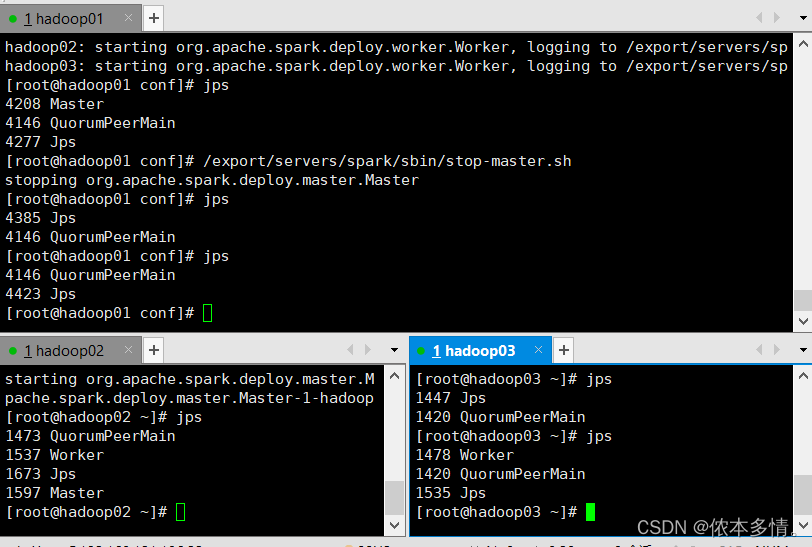
6、测试hadoop01的单点故障。
先停掉hadoop01的master服务
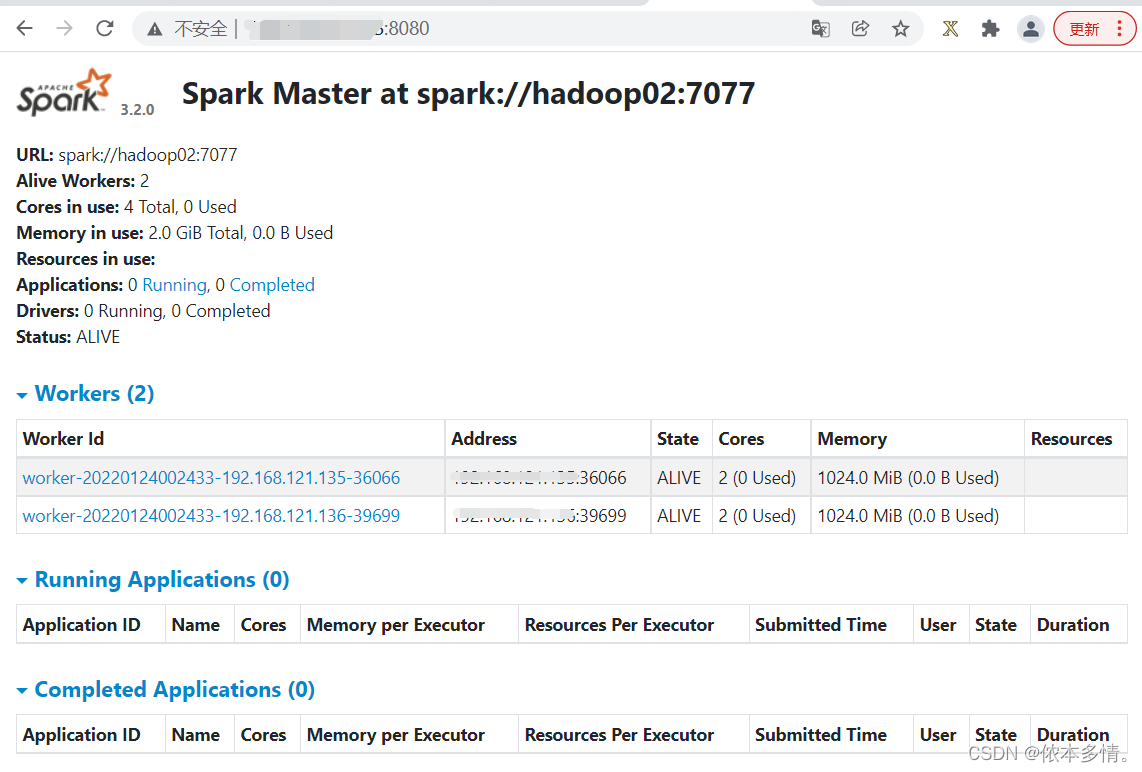
经过了zookeeper高可用的选举,最终hadoop02继承了hadoop01.


















 1837
1837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











