






1.猜拳游戏:玩家从控制台输入手势与电脑进行人机PK:(ps:pk表帮助理解)
| 玩家 | 电脑 | 玩家 | 电脑 | 玩家 | 电脑 |
| 石头 1 | 剪刀 | 剪刀 | 剪刀 | 石头 | 布 |
| 剪刀 2 | 布 | 石头 | 石头 | 剪刀 | 石头 |
| 布 3 | 石头 | 布 | 布 | 布 | 剪刀 |
| 玩家赢 | 平局 | 电脑赢 | |||
下面直接上程序喽:
import random
# 1.玩家从控制台输入手势
player_str = input('请输入要输出的手势[石头]/1 [剪刀]/2 [布]/3:')
# 类型转换
player = int (player_str)
# 2.电脑输出手势
computer = random.randint(1,3)
print(computer)
# 3.玩家和电脑进行比较
if (player==1 and computer==2 ) or(player==2 and computer==3) or(player==3 and computer==1):
print('win!')
elif player==computer:
print('go on!')
else:
print('computer is perfect!')注:此处用到随机数random.randint() #randint 产生整数类型的数据,包含头和尾.
2.打印小星星
先把怎样的小星星展示一下:
*
**
***
****
*****代码:(这里可能也就我会想当然吧,不过还是要说下Debug调试的好处,它可以帮你理清思路,超好用!)
row=1
while row<=5:
col = 1
while col<=row:
print('*',end='')
col+=1
print()
row+=13.九九乘法表:
row =1
while row<=9:
col=1
while col<=row:
print('{}*{}'.format(row,col),end=' ')
col+=1
print()
row+=1就是一想就会想到的九九乘法表,不过这里又学到一个新的格式化输出语句,使用占位符。
print('{}*{}'.format(row,col),end=' ')简单网络爬虫
老规矩先解释:
1.网络爬虫:模拟客户端发送网络请求,接受请求响应,一种按照一定的规则,自动的抓取互联网信息的程序。
2只要浏览器能做的事情,原则上,爬虫都能做。
3网络爬虫的步骤
(1)构造url列表
(2)遍历url列表,发送请求,获取响应
(3)保存数据
练习1:先来保存一张 idol 的照片吧
import requests
url = "http://imgsrc.baidu.com/forum/w%3D580%3B/sign=a011b898a7773912c4268569c8228618/63d0f703918fa0ec5ee89a28289759ee3d6ddbec.jpg"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
response = requests.get(url, headers = header)
with open('bd.png', mode='wb') as f:
ret = response.content
f.write(ret)
pass对的就是这个:
注意:
url:即为你要保存的图片地址。
header:跟着我的步骤来------>先打开贴吧----->按F12得如下图:
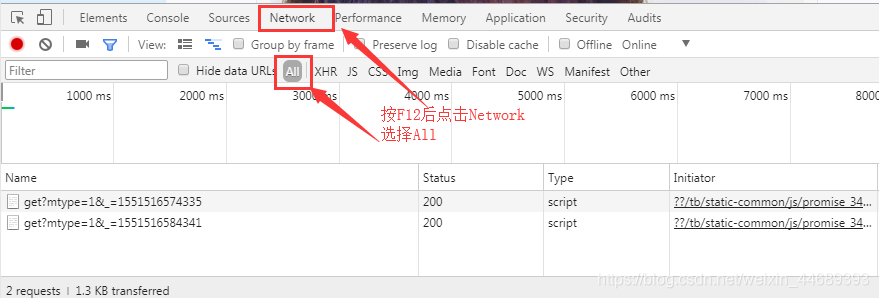
然后依次根据图片顺序步骤来操作:
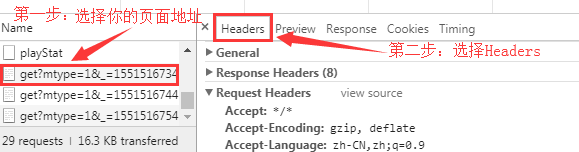
到关键步骤了:

好啦,需要的参数都有了,代码在下方:
import requests
url = "http://imgsrc.baidu.com/forum/w%3D580%3B/sign=a011b898a7773912c4268569c8228618/63d0f703918fa0ec5ee89a28289759ee3d6ddbec.jpg"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
response = requests.get(url, headers = header)
with open('bd.png', mode='wb') as f:
ret = response.content
f.write(ret)
pass练习2.保存网页
注:参数获取步骤都一样,这里就不再说了。
import requests
def down_tieba():
url="http://tieba.baidu.com/f?kw=朱一龙&ie=utf-8&pn=50"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2767.400"
}
response=requests.get(url,headers=header)
ret=response.content.decode()
with open('file1/第一页.html',mode='w',encoding='utf-8') as f :
f.write(ret)
pass
down_tieba()
练习3:爬虫下载百度贴吧所有内容
# 爬虫下载百度贴吧所有内容
import requests
def down_alltieba():
url_temp = "http://tieba.baidu.com/f?kw=朱一龙&ie=utf-8&pn={}"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2767.400"
}
#1.构造url列表
url_list = []
for index in range(100):
index=(index-1)*50
url=url_temp.format(index)
url_list.append(url)
# print(url)
#2.循环下载
num=1
for url in url_list:
print('正在下载第{}页.html'.format(num))
response=requests.get(url,headers=header)
html_content=response.content.decode()
with open('tieba/第{}页.html'.format(num),'w',encoding='utf-8') as f:
f.write(html_content)
num+=1
down_alltieba()注意:


结果展示一下:
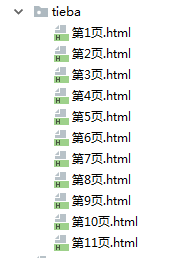 本来好多页的,我中途停止执行了,所以到第11页。
本来好多页的,我中途停止执行了,所以到第11页。
完成了,我要去好好度过我这个周末了。


















 6292
6292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









