






 本文围绕JUC展开,介绍了可重入锁、死锁概念,详细讲解了Callable接口、FutureTask、JUC三个辅助类、读写锁演变、阻塞队列、线程池、Fork和join分支合并框架及异步回调等内容,还提及了各部分的特点、使用场景及代码示例,知识可用于约三年工作经验的面试。
本文围绕JUC展开,介绍了可重入锁、死锁概念,详细讲解了Callable接口、FutureTask、JUC三个辅助类、读写锁演变、阻塞队列、线程池、Fork和join分支合并框架及异步回调等内容,还提及了各部分的特点、使用场景及代码示例,知识可用于约三年工作经验的面试。
可重入锁:字面意思就是可以重复进入的锁。synchronized(隐式)和Lock(显式)
死锁:两个或以上的进程因为争夺资源而造成互相等待资源的现象称为死锁。
Callable接口
Callable中的call()返回计算结果,如果无法计算结果,会抛出异常.
Runnable接口和Callable接口区别:
- 是否有返回值
- 是否抛出异常
- 实现方法名称不同,一个是run方法,一个是call方法
FutureTask
未来的任务,如果运行过一次get(),那么下一次,就直接得到结果.
JUC的三个辅助类
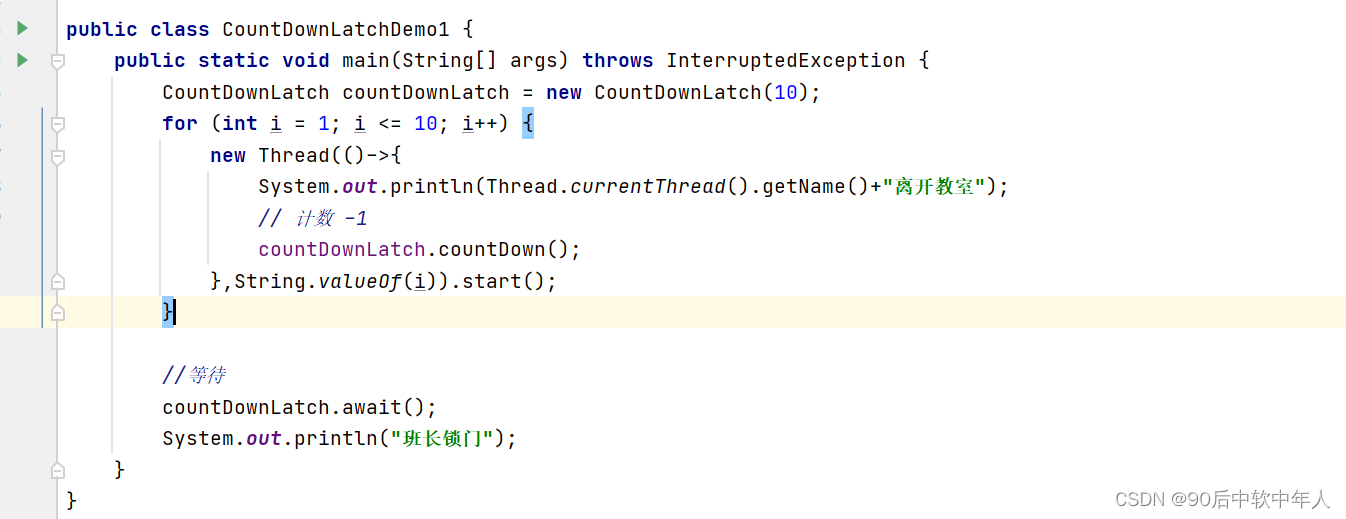
减少计数CountDownLatch
CountDownLatch 类可以设置一个计数器,然后通过 countDown ()来进行减 1 的操作,使用 await 方法等待计数器不大于 0后,然后继续执行 await 方法之后的语句。以下是代码演示:
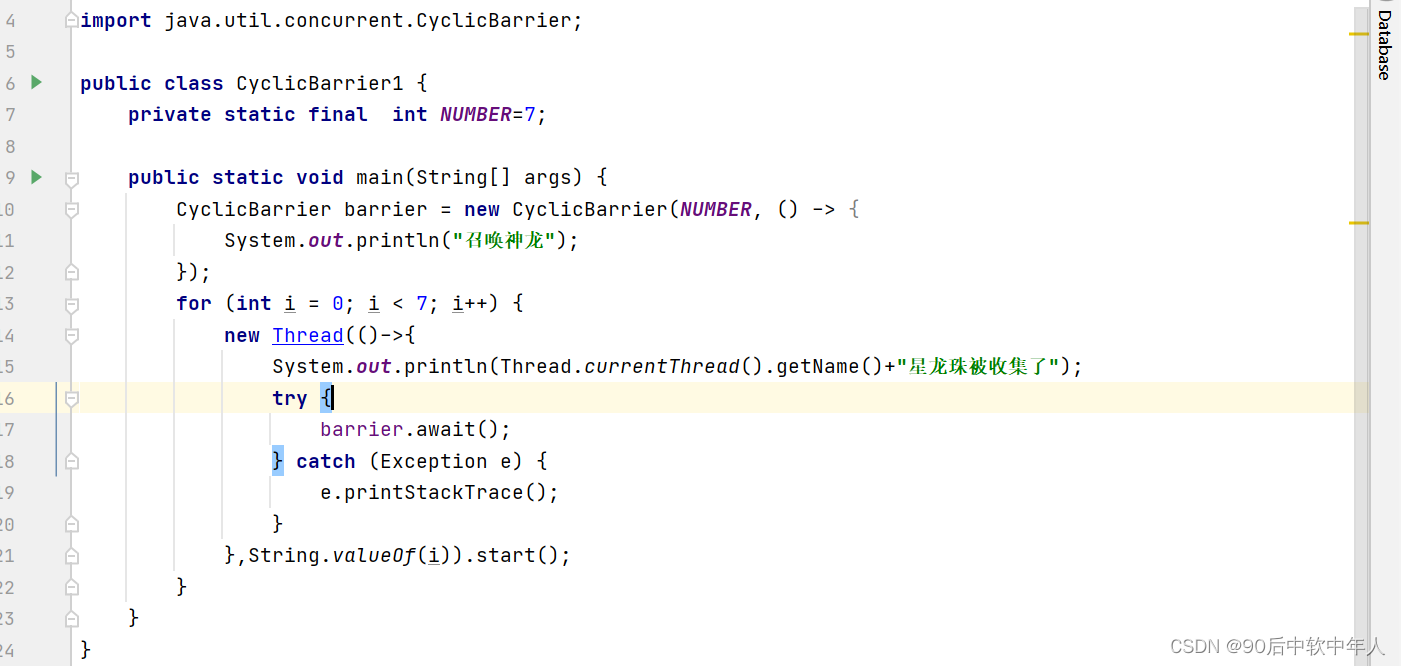
循环栅栏 CyclicBarrier
该类是 允许一组线程 互相 等待,直到到达某个公共屏障点,在设计一组固定大小的线程的程序中,这些线程必须互相等待,因为barrier在释放等待线程后可以重用,所以称为循环barrier。以下是代码演示:
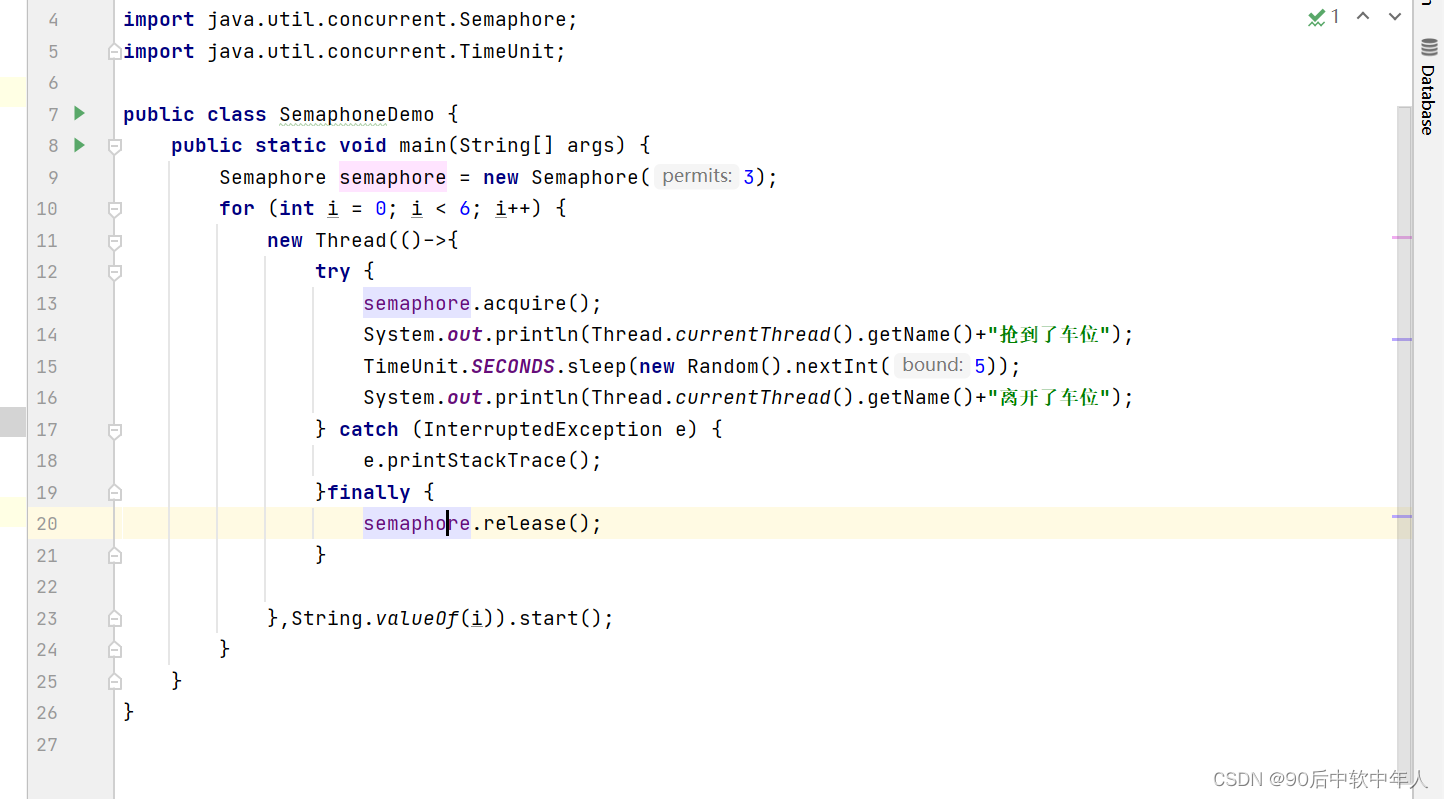
信号灯 Semaphore
一个计数信号量,从概念上讲,信号量维护了一个许可集,如有必要,在许可前会阻塞每一个acquire(),然后在获取该许可。每个release()添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore只对可用许可的号码进行计数,并采取相应的行动。以下是代码演示:
读写锁的演变
读写锁:一个资源可以被多个资源访问,或者可以被一个写资源访问,但是不能同时存在读写线程,读写互斥,读读共享。

只有写锁可以降级为读锁。
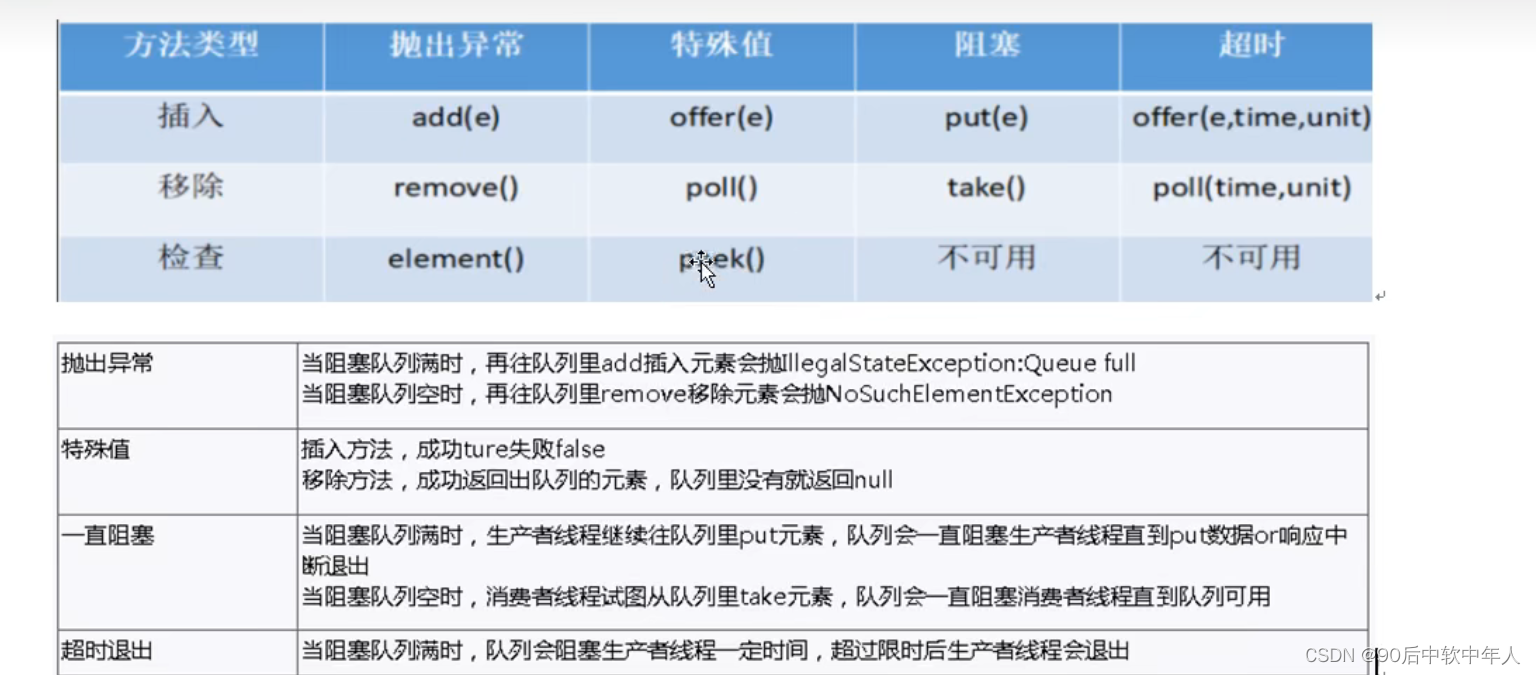
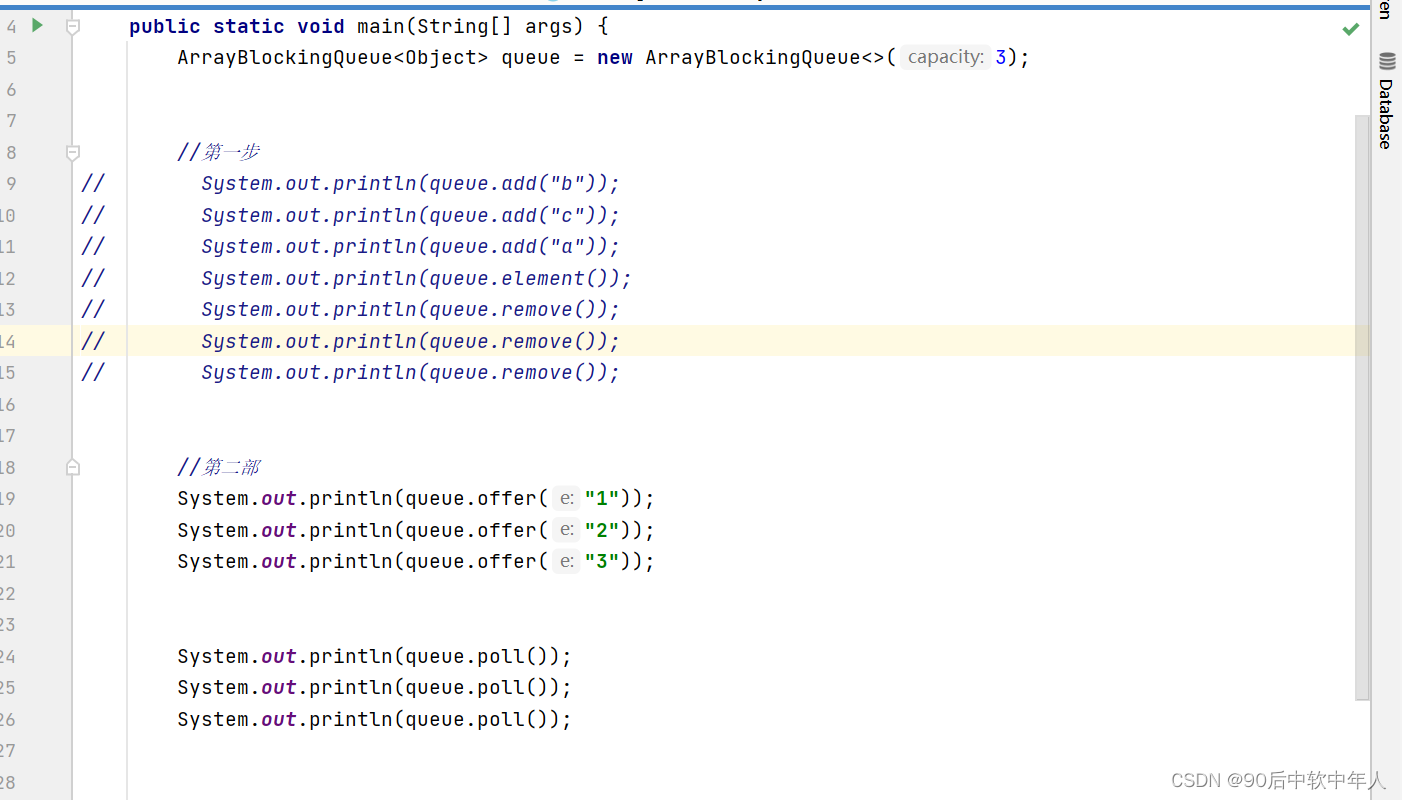
阻塞队列
线程往队列里面放入元素,放满之后处于阻塞状态.同样,取元素时也不无限的,没有元素时也会进入等待状态。
常见的队列有两种:
先进先出(FIFO)、后进先出(LIFO).
阻塞队列的好处:我们不需要关注什么时候需要阻塞线程、什么时候需要唤醒线程。BlockQueue可以包办。
阻塞队列分类
ArrayBlockingQueue(常用)
基于数组的阻塞队列实现,在ArrayBlockingQueue 内部,维护了一个定长数组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数组外,ArrayBlockingQueue内部还保存着两个整形变量,分别标识着队列的头部和尾部在数组中的位置。
LinkedBlockingQueue(常用)
基于链表的阻塞队列
由链表结构组成的(大小默认值为Integer.MAX_VALUE)阻塞队列。之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
DelayQueue
使用优先级队列实现的延迟无界阻塞队列
DelayQueue 中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。
PriorityBlockingQueue
支持优先级排序的无界阻塞队列。
SynchronousQueue
单个元素的队列
线程池
线程过多会带来调度开销,进而影响整体缓存局部性和整体性能。而线程池维护着多个线程,这就避免了短时间创建和销毁的代价。线程池做的工作只要是控制住运行的线程数量,处理过程中将线程放入队列,然后在线程创建时启动这些任务,超过线程数目,线程排队等候,等待其他线程完成,再从队列中取出线程。
七个主要参数

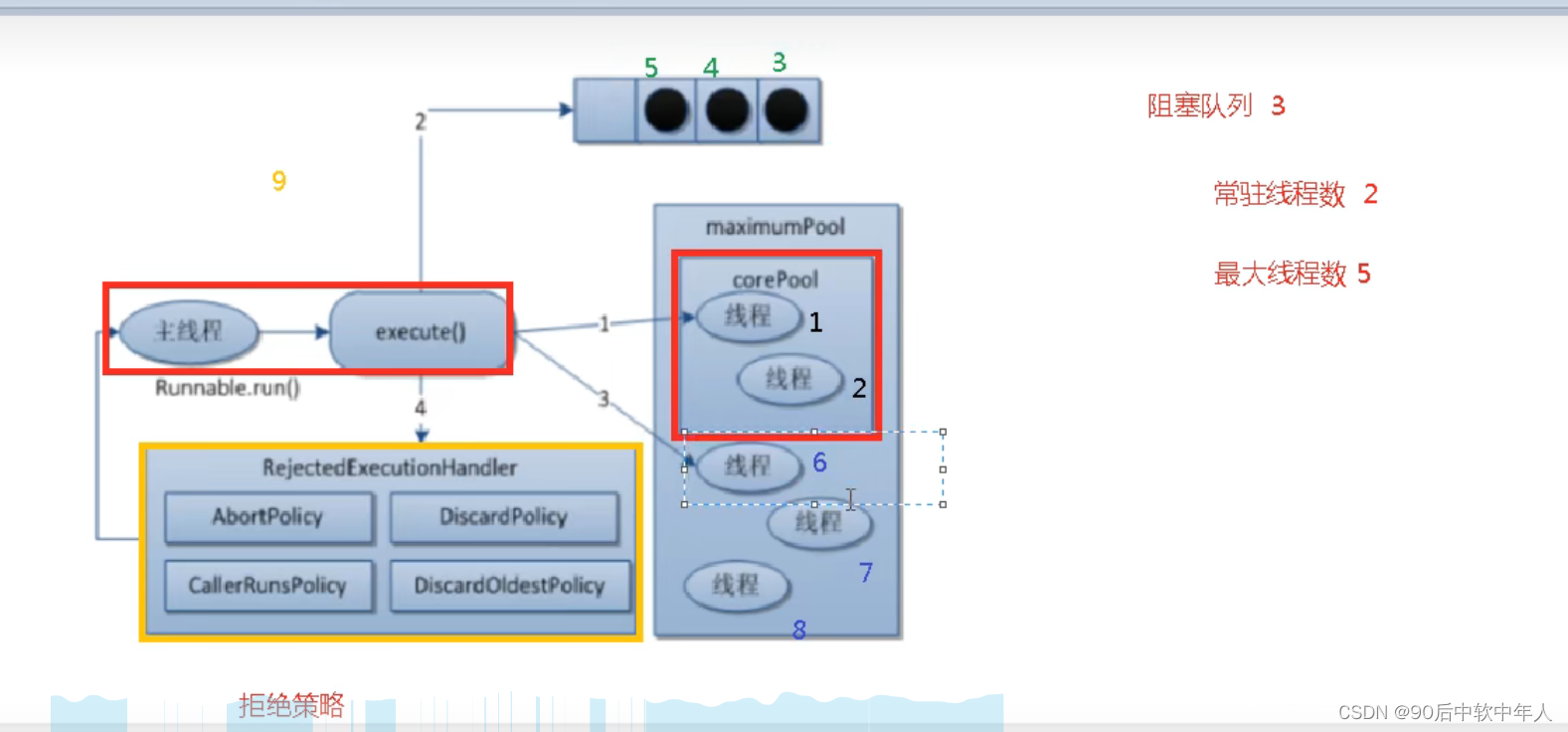
先到常驻线程,满了之后再到阻塞队列进行等待,阻塞队列满了之后,在往外扩容线程,扩容线程不能大于最大线程数。大于最大线程数和阻塞队列之和后,会执行拒绝策略。
Fork和join分支合并框架
Fork/Join它可以将一个大的任务拆分成多个子任务进行并行处理,最后将士任务结果合并成最后的计算结果,并进行输出。
Fork/Join框架要完成两件事情:
Fork:把一个复杂任务进行分拆,大事化小。
Join:把分拆任务的结果进行合并。
异步回调
异步:指设立哨兵,资源空闲通知线程,否则该线程去做其他事情(非阻塞)
浅浅总结一下,虽然我自己写得少,但是看的时间大概有一个月的时间,中间穿插着很多事情,我也不想单纯的把视频刷完就作为结束了,为了更进一步,我在最后面仅仅了解了概念,不乱写笔记。眼下写的东西已经足够面试三年左右的工作了。接下来该总结jvm了

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









