



 Redis是一款高性能的Key-Value数据库,支持多种数据结构如字符串、哈希、列表、集合和有序集合,提供数据持久化、备份及高可用性。本文探讨Redis在缓存系统、计数器、消息队列、排行榜、社交网络、实时系统等方面的应用。
Redis是一款高性能的Key-Value数据库,支持多种数据结构如字符串、哈希、列表、集合和有序集合,提供数据持久化、备份及高可用性。本文探讨Redis在缓存系统、计数器、消息队列、排行榜、社交网络、实时系统等方面的应用。
分布式缓存之redis
1.redis介绍
Redis是一个开源的使用C语言编写、开源、支持网络、可基于内存亦可持久化的日志型、高性能的Key-Value数据库,并提供多种语言的API。它通常被称为数据结构服务器,因为值value)可以是 字符串(String)、哈希(Map)、 列表(list)、集合(sets) 和 有序集合(sorted sets)等类型。
Redis 与其他 key - value 缓存产品有以下三个特点:
(1)Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
(2)Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
(3)Redis支持数据的备份,即master-slave模式的数据备份。
Redis优势
1)性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
(2)丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
(3)原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
(4)丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
2.体系架构
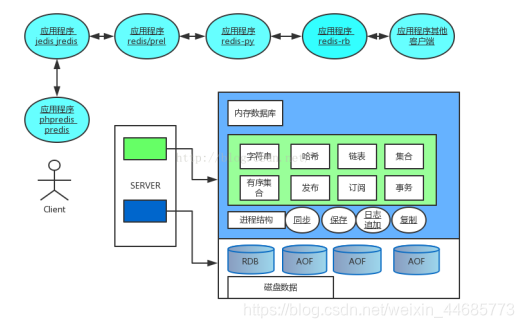
互联网数据目前基本使用两种方式来存储,关系数据库或者key value。但是这些互联网业务本身并不属于这两种数据类型,比如用户在社会化平台中的关系,它是一个list,如果要用关系数据库存储就需要转换成一种多行记录的形式,这种形式存在很多冗余数据,每一行需要存储一些重复信息。如果用key value存储则修改和删除比较麻烦,需要将全部数据读出再写入。Redis在内存中设计了各种数据类型,让业务能够高速原子的访问这些数据结构,并且不需要关心持久存储的问题,从架构上解决了前面两种存储需要走一些弯路的问题.
Redis新版本增加了VM特性。让Redis数据容量突破了物理内存的限制。并实现了数据冷热分离。用get/set方式使用Redis 作为一个key value存在,很多开发者自然的使用set/get方式来使用Redis,实际上这并不是最优化的使用方法。尤其在未启用VM情况下,Redis全部数据需要放入内存,节约内存尤其重要。假如一个key-value单元需要最小占用512字节,即使只存一个字节也占了512字节。这时候就有一个设计模式,可以把key复用,几个key-value放入一个key中,value再作为一个set存入,这样同样512字节就会存放10-100倍的容量
AOF和RDB两种方式的高可用
Redis有两种存储方式,默认是RDB方式,实现方法是定时将内存的快照(snapshot)持久化到硬盘,这种方法缺点是持久化之后如果出现crash则会丢失一段数据,因为RDB是在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。 优点:使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能 缺点:RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候。
因此在完美主义者的推动下作者增加了AOF方式。aof即append only file(append only mode),在写入内存数据的同时将操作命令保存到日志文件,在一个并发更改上万的系统中,命令日志是一个非常庞大的数据,管理维护成本非常高,恢复重建时间会非常长,这样导致失去aof高可用性本意。另外更重要的是Redis是一个内存数据结构模型,所有的优势都是建立在对内存复杂数据结构高效的原子操作上,这样就看出aof是一个非常不协调的部分。
aof目的主要是数据可靠性及高可用性,可以保持更高的数据完整性,如果设置追加file的时间是1s,如果redis发生故障,最多会丢失1s的数据;且如果日志写入不完整支持redis-check-aof来进行日志修复;AOF文件没被rewrite之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的flushall)。缺点:AOF文件比RDB文件大,且恢复速度慢。在Redis中还有另外一种方法来达到目的:Replication。由于Redis的高性能,复制基本没有延迟。这样达到了防止单点故障及实现了高可用。
3.数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及
zset(sorted set:有序集合)。
4.应用场景
Redis 最大的作用是增加你原来的访问性能问题,试想如果项目已经搭建好,这个项目一般是不太可能更换的。但是 Redis 独特的存在是只需要增加一层,把常用的数据存放在 Redis 即可。你在开发环境中使用 Redis 功能,但却不需要转到 Redis。
无论是什么架构,你都可以将 Redis 融入项目中来,这可以解决很多关系数据库无法解决的问题。比如,现有数据库处理缓慢的任务,或者在原有的基础上开发新的功能,都可以使用 Redis。接下来,我们一起看看 Redis 的典型使用场景。
1.缓存系统。这是 Redis 使用最多的场景。Redis 能够替代 Memcached,让你的缓存从只能存储数据变得能够更新数据,因此你不再需要每次都重新生成数据。毫无疑问,Redis 缓存使用的方式与
Memcached 相同。网络中总是能够看到这个技术更新换代,Redis 的原生命令,尽管简单却功能强
大,把它们加以组合,能完成的功能是无法想象的。当然,你可以专门编写代码来完成所有这些操作,但 Redis 实现起来显然更为轻松。
2.计数器。如转发数、评论数,有了原子递增(Atomic Increment),你可以放心的加上各种计数,用GETSET重置,或者是让它们过期。目前新浪是号称史上最大的 Redis 集群。
比如,你想计算出最近用户在页面间停顿不超过 30 秒的页面浏览量,当计数达到比如 10 时,就可以显示提示。再比如,如果想知道什么时候封锁一个 IP 地址,INCRBY命令让这些变得很容易,通过原子递增保持计数;GETSET用来重置计数器;过期属性用来确认一个关键字什么时候应该删除。
3.消息队列系统。虽然 Kafka 更强,但是简单的可以使用 Redis。运行稳定并且快速,支持模式匹配,能够实时订阅与取消频道。
Redis 还有阻塞队列的命令,能够让一个程序在执行时被另一个程序添加到队列。你也可以做些更有趣的事情,比如一个旋转更新的 RSS Feed 队列。
4.排行榜及相关问题。实际就是一种有序集合。对于 Redis 来说,如果你要在几百万个用户中找到排名,其他数据库查询是非常慢的,因为每过几分钟,就会有几百万个不同的数据产生变化,但是 Redis却可以轻松解决。
排行榜(Leader Board)按照得分进行排序。ZADD 命令可以直接实现这个功能,而 ZREVRANGE 命令可以用来按照得分获取前 100 名的用户,ZRANK 可以用来获取用户排名,非常直接而且操作容易。
5.社交网络。Redis 可以非常好地与社交网络相结合,如新浪微博、Twiter等,比如QQ和用户交互的时候,用户和状态消息将会聚焦很多有用的信息,很多交互如实时聊天就是通过 Redis 来实现的。
6.按照用户投票和时间排序。Reddit 的排行榜,得分会随着时间变化。LPUSH 和 LTRIM 命令结合运用,把文章添加到一个列表中。一项后台任务用来获取列表,并重新计算列表的排序,ZADD 命令用来按照新的顺序填充生成列表。列表可以实现非常快速的检索,即使是负载很重的站点。
7.过期项目处理。通过 Unix 时间作为关键字,用来保持列表能够按时间排序。对 currenttime 和
timeto_live 进行检索,完成查找过期项目的艰巨任务。另一项后台任务使用 ZRANGE…WITHSCORES进行查询,删除过期的条目。
8.实时系统。使用位图来做布隆过滤器,例如实现垃圾邮件过滤系统的开发变的非常容易。
综上所述, Redis 的应用是非常广泛的,而且在实际使用中是非常有价值的。你可以让网站向 100 万用户推荐新闻、可以实时显示最新的项目列表、在游戏中实时获得排名、获得全球排名等等。Redis 的出现,解决了传统关系数据库的短板,让开发变的更加简单和高效,大大提高了开发效率,也在用户体验上获得更加实时的体验。随着 Redis 的使用越来越广泛,将会有更多的开发者加入 Redis 的使用和开发上来。
持久化
redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化。redis支持四种持久化方式,一是 Snapshotting(快照)也是默认方式;二是Append-only file(缩写aof)的方式;三是虚拟内存方式;四是diskstore方式。

















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









