






实验目的
通过本次实验,掌握了维吉尼亚的加密、解密和维吉尼亚密码在无密钥情况下的破解。
实验步骤
- 维吉尼亚密码的加密和解密
维吉尼亚加密实际上是由一些偏移量不同的恺撒密码组成。所以,我们在写的时候重要的是先将明文处理分组,然后在每一组内采用不同的偏移量进行加密。
对分组进行处理,我采用的是对密钥的长度取余的方式
offset = ord(key[(i-non_space) % len(key)]) -ord('a')
cipter +=chr((ord(message[i]) - ord('a') +offset) %26 +ord('a'))
offset是计算偏移量的,cipter的计算和凯撒密码的处理一样。
因为在一段英文文章中,存在大写字母、小写字母和一些其他字符的情况,所以我们需要对这些情况进行分类讨论。
for i in range (len(message)):
if message[i].isalpha():
if message[i] in string.ascii_lowercase:
offset = ord(key[(i-non_space) % len(key)]) -ord('a')
cipter +=chr((ord(message[i]) - ord('a') +offset) %26 +ord('a'))
else:
offset = ord(key[(i-non_space) % len(key)]) -ord('A')
cipter +=chr((ord(message[i]) - ord('A') +offset) %26 +ord('A'))
else:
cipter += message[i]
non_space += 1
我是将这些情况分三种进行处理:
1、大写字母
2、小写字母
3、其他字符(对于其他字符的处理,我们是不对这些字符进行处理让其保持其原来的面目)
维吉尼亚解密的处理方式和维吉尼亚加密的处理方式是一样的:
for i in range(0,len(cipter),1):
if cipter[i].isalpha():
if cipter[i] in string.ascii_lowercase:
offset = ord(key[(i-space)%len(key)]) -ord('a')
message +=chr( (ord(cipter[i]) -ord('a')-offset)%26 + ord('a') )
else:
offset = ord(key[(i-space)%len(key)]) -ord('A')
message +=chr( (ord(cipter[i]) -ord('A')-offset)%26 + ord('A') )
else:
message += cipter[i]
space += 1
加密和解密只是加和减的区别,在这里我就不作过多赘述。
代码展示:
#-*-coding:utf-8-*-
#维吉尼亚加密
'''
fileName : VigenereEncrypto.py
'''
import string
def VigenereEncrypto (message , key) :
message = message.lower()
key = key.lower()
cipter = ''
non_space = 0
for i in range (len(message)):
if message[i].isalpha():
if message[i] in string.ascii_lowercase:
offset = ord(key[(i-non_space) % len(key)]) -ord('a')
cipter +=chr((ord(message[i]) - ord('a') +offset) %26 +ord('a'))
else:
offset = ord(key[(i-non_space) % len(key)]) -ord('A')
cipter +=chr((ord(message[i]) - ord('A') +offset) %26 +ord('A'))
else:
cipter += message[i]
non_space += 1
return cipter
def VigenereDecrypto (cipter, key):
space=0
message= ''
for i in range(0,len(cipter),1):
if cipter[i].isalpha():
if cipter[i] in string.ascii_lowercase:
offset = ord(key[(i-space)%len(key)]) -ord('a')
message +=chr( (ord(cipter[i]) -ord('a')-offset)%26 + ord('a') )
else:
offset = ord(key[(i-space)%len(key)]) -ord('A')
message +=chr( (ord(cipter[i]) -ord('A')-offset)%26 + ord('A') )
else:
message += cipter[i]
space += 1
return message
if __name__ == '__main__':
message = 'wear discovered save yourself'
key = 'decep'
ciphertext = VigenereEncrypto(message,key)
print ciphertext
plaintext = VigenereDecrypto(ciphertext,key)
print plaintext
加密和解密的结果:

- 维吉尼亚的破解
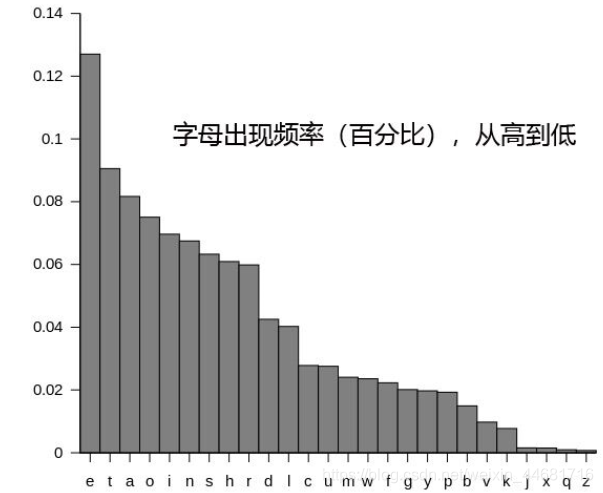
英文中字母出现的频率是不一样的,只要字符总量足够,全部收集到一起,统计各个字符出现的频率,然后再加上字母前后的关联关系,以及所要加密的语言本身语法搭配就可大幅度降低字母
的排列组合的可能性,这样密码就破解了。
1、首先,我们要先得到密钥的长度
我们利用位移法求解key的长度
每次位移后计算与原密文对应相同的字母个数,即s[i]==s[i+j],i为位置,j为位移量。
def find_key_length(cipher):
MAX_LEN_REP = 10
shift = [ None ]
length = len(cipher)
for i in range(1, length//MAX_LEN_REP):
repeat = 0
for j in range(length):
repeat += 1 if cipher[j]==cipher[(j+i)%length] else 0
shift.append((i,repeat))
for i in range(1, length//MAX_LEN_REP):
print shift[i]
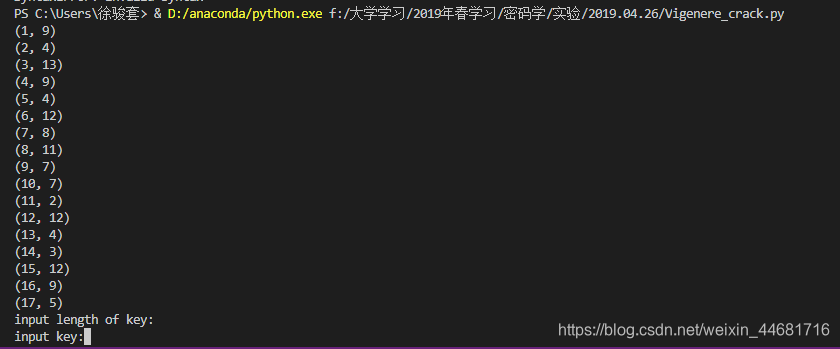
从中选出最有可能的密钥长度。从上图可以看出3、6、8、12、15 重复字母数相对偏高,这些字母的公因子约为3,于是说密钥长度为3的可能性非常大。
2、对密钥中的每一个进行频率分析
获取key长度之后,将文本分为key长度份,即s[0],s[3],s[6]……为一份,s[1],s[4],s[7]……为第二份,剩下的为第三份。
def textToList(text,length): # 根据密钥长度将密文分组
textMatrix = []
row = []
index = 0
for ch in text:
row.append(ch)
index += 1
if index % length ==0:
textMatrix.append(row)
row = []
return textMatrix
接下来将每份进行频率分析,获得每一份的偏移量,即得到一串密钥中的每一个。
def countList(lis): # 统计字母频度
li = []
alphabet = [chr(i) for i in range(97,123)]
for c in alphabet:
count = 0
for ch in lis:
if ch == c:
count+=1
li.append(count/len(lis))
return li
def getKey(text,length): # 获取密钥
key = [] # 定义空白列表用来存密钥
alphaRate =[0.08167,0.01492,0.02782,0.04253,0.12705,0.02228,0.02015,0.06094,0.06996,0.00153,0.00772,0.04025,0.02406,0.06749,0.07507,0.01929,0.0009,0.05987,0.06327,0.09056,0.02758,0.00978,0.02360,0.0015,0.01974,0.00074]
matrix =textToList(text,length)
for i in range(length):
w = [row[i] for row in matrix] #获取每组密文
li = countList(w)
powLi = [] #算乘积
for j in range(26):
Sum = 0.0
for k in range(26):
Sum += alphaRate[k]*li[k]
powLi.append(Sum)
li = li[1:]+li[:1]#循环移位
Abs = 100
ch = ''
for j in range(len(powLi)):
if abs(powLi[j] -0.065546)<Abs: # 找出最接近英文字母重合指数的项
Abs = abs(powLi[j] -0.065546) # 保存最接近的距离,作为下次比较的基准
ch = chr(j+97)
key.append(ch)
return key
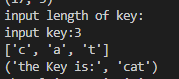
3、解密
得到密钥后,利用解密函数得到明文。

最后附上维吉尼亚破解的完整代码:
#-*-coding:utf-8-*-
from __future__ import division
def openfile(fileName): # 读文件
file = open(fileName,'r')
text = file.read()
file.close()
text = text.replace('\n','')
return text
def find_key_length(cipher):
MAX_LEN_REP = 10
shift = [ None ]
length = len(cipher)
for i in range(1, length//MAX_LEN_REP):
repeat = 0
for j in range(length):
repeat += 1 if cipher[j]==cipher[(j+i)%length] else 0
shift.append((i,repeat))
for i in range(1, length//MAX_LEN_REP):
print shift[i]
def textToList(text,length): # 根据密钥长度将密文分组
textMatrix = []
row = []
index = 0
for ch in text:
row.append(ch)
index += 1
if index % length ==0:
textMatrix.append(row)
row = []
return textMatrix
def countList(lis): # 统计字母频度
li = []
alphabet = [chr(i) for i in range(97,123)]
for c in alphabet:
count = 0
for ch in lis:
if ch == c:
count+=1
li.append(count/len(lis))
return li
def getKey(text,length): # 获取密钥
key = [] # 定义空白列表用来存密钥
alphaRate =[0.08167,0.01492,0.02782,0.04253,0.12705,0.02228,0.02015,0.06094,0.06996,0.00153,0.00772,0.04025,0.02406,0.06749,0.07507,0.01929,0.0009,0.05987,0.06327,0.09056,0.02758,0.00978,0.02360,0.0015,0.01974,0.00074]
matrix =textToList(text,length)
for i in range(length):
w = [row[i] for row in matrix] #获取每组密文
li = countList(w)
powLi = [] #算乘积
for j in range(26):
Sum = 0.0
for k in range(26):
Sum += alphaRate[k]*li[k]
powLi.append(Sum)
li = li[1:]+li[:1]#循环移位
Abs = 100
ch = ''
for j in range(len(powLi)):
if abs(powLi[j] -0.065546)<Abs: # 找出最接近英文字母重合指数的项
Abs = abs(powLi[j] -0.065546) # 保存最接近的距离,作为下次比较的基准
ch = chr(j+97)
key.append(ch)
return key
def virginiaCrack(cipher,key,length): # 解密函数
keyStr = ''
for k in key:
keyStr+=k
print('the Key is:',keyStr)
plain = ''
index = 0
for ch in cipher:
c = chr((ord(ch)-ord(key[index%length]))%26+97)
plain += c
index+=1
return plain # 返回明文
if __name__ == '__main__':
cipher = openfile('F:\english.txt')
find_key_length(cipher)
print('input length of key:')
key_length = input("input key:")
'''for i in range(0,key):
print("next is %d" %(i+1))
frequency_analysis(cipher,key,i)'''
key=getKey(cipher,key_length)
print key
plainText= virginiaCrack(cipher,key,key_length)
print('the plainText is %s'%plainText)

















 1906
1906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









