






一、数据加载
读取数据主要分成两种,Dataset、Dataloader
用up的垃圾回收的例子来说
Dataset可以进行一个编号的控制,提供一种方式去获取数据及其label
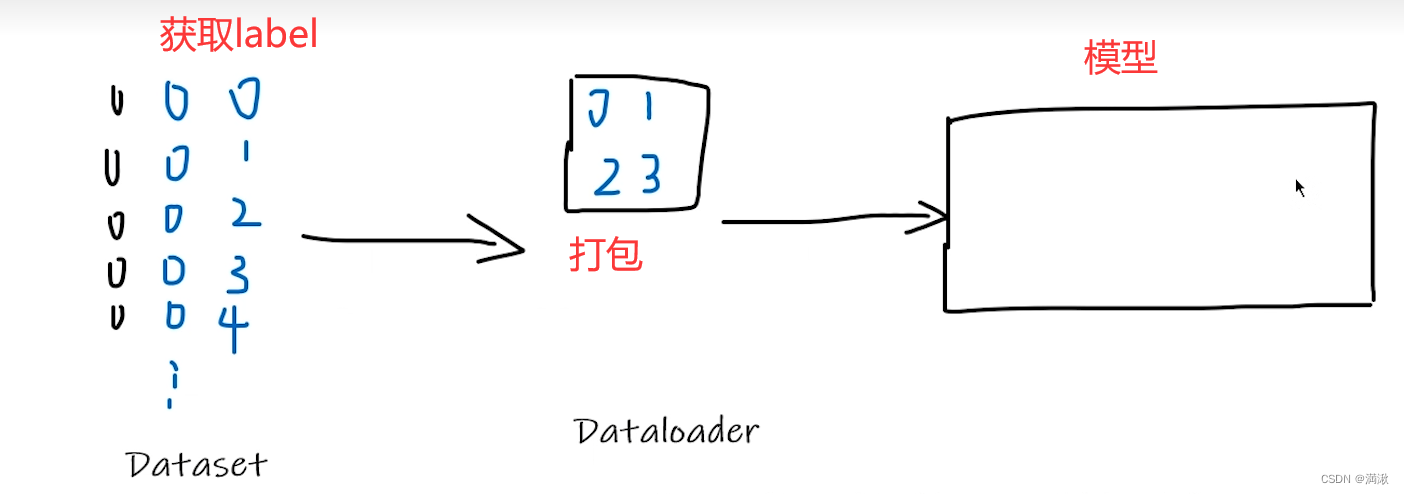
| Dataset | Dataloader |
| 提供一种方式去获取数据及其label | 为后面的网络提供不同的数据形式 |
| 如何获取每一个数据及其label 告诉我们总共有多少的数据 |
为了更好的了解上述两种加载方式,先了解下几种组织形式

训练图片和训练label

.txt的+label
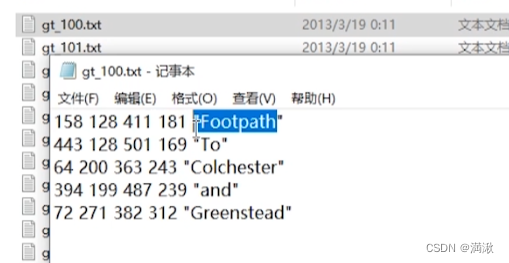
图片上直接+label
二、练手
对蚂蚁和蜜蜂进行二分类
1.用工具之前,先看看官方文档怎么使用
from torch.utils.data import Dataset两种方式查看Dataset怎么使用
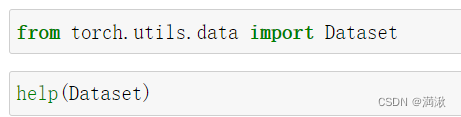

Init signature: Dataset(*args, **kwds)
Source:
class Dataset(Generic[T_co]):
r"""An abstract class representing a :class:`Dataset`.
All datasets that represent a map from keys to data samples should subclass
it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a
data sample for a given key. Subclasses could also optionally overwrite
:meth:`__len__`, which is expected to return the size of the dataset by many
:class:`~torch.utils.data.Sampler` implementations and the default options
of :class:`~torch.utils.data.DataLoader`.
.. note::
:class:`~torch.utils.data.DataLoader` by default constructs a index
sampler that yields integral indices. To make it work with a map-style
dataset with non-integral indices/keys, a custom sampler must be provided.
"""
def __getitem__(self, index) -> T_co:
raise NotImplementedError
def __add__(self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]':
return ConcatDataset([self, other])
File: d:\work_app\anconda\envs\motionbert\lib\site-packages\torch\utils\data\dataset.py
Type: type
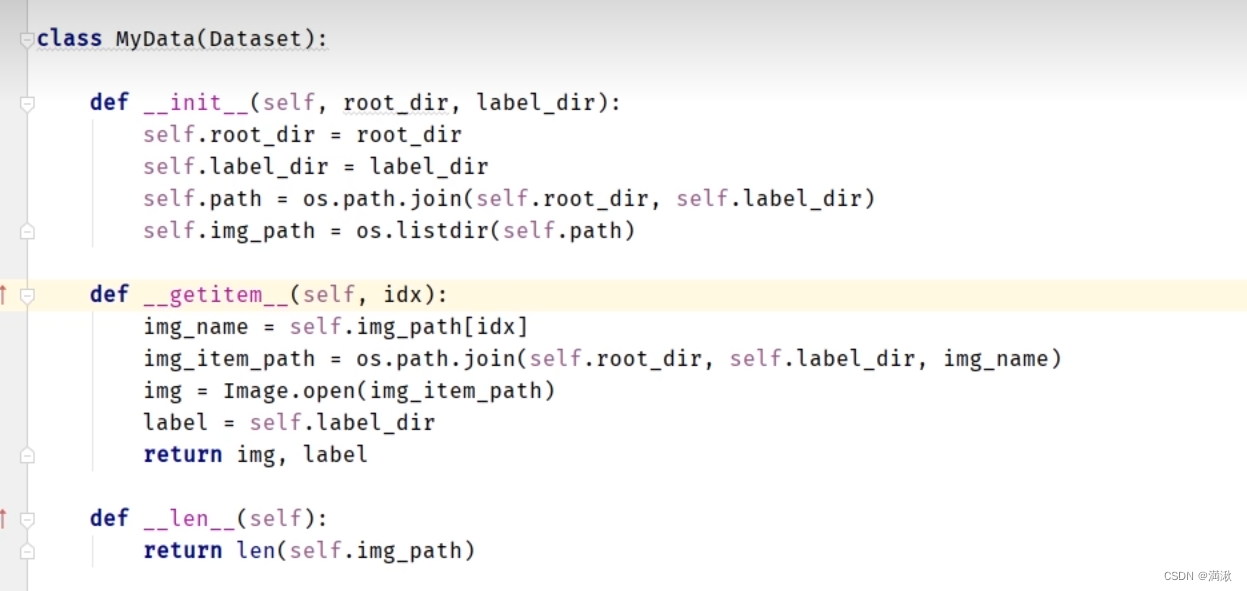
Subclasses: IterableDataset, TensorDataset, ConcatDataset, Subset, MapDataPipe主要是重写,__getitem__(),__add__()这两个类。
以下是相对路径,注意windows下要写两个斜杠表示转义


套路就是读取一个文件的地址然后,打开这个地址存到一个变量里,这个变量就是这张图片
os关于系统的一个库

根路径的生成,用os.path.join这个函数不容易出现转义上的错误

![]()

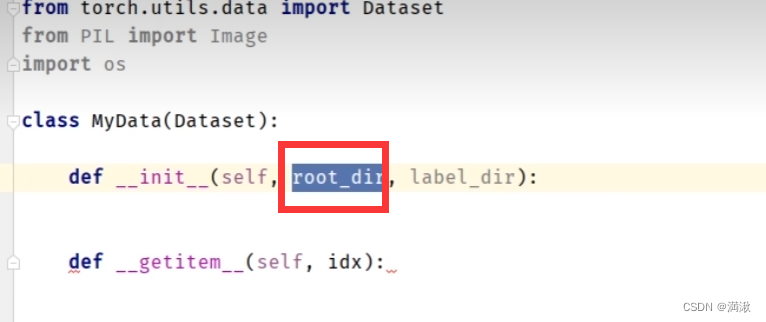
关于为啥使用self,因为,一个函数的变量不能给另外一个函数使用,它的作用就是把这个函数的变量给另外一个函数使用,相当于指定了一个函数的全局变量。
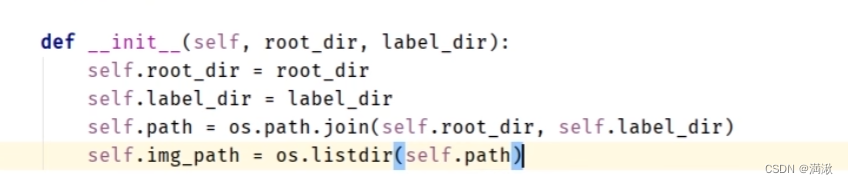
从上往下分别是根目录地址,标签地址,总的地址,然后获取图片的一个列表
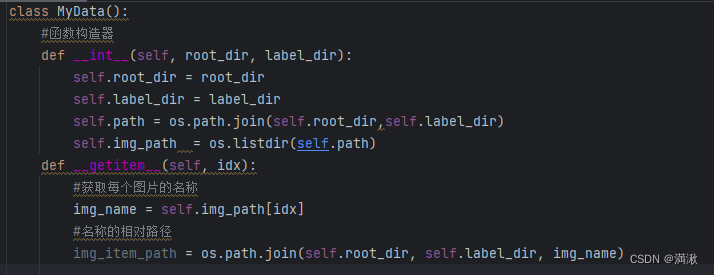
在控制台去idx = 0去测试一下看看有没有读取到地址
获取蚂蚁的数据集

重命名
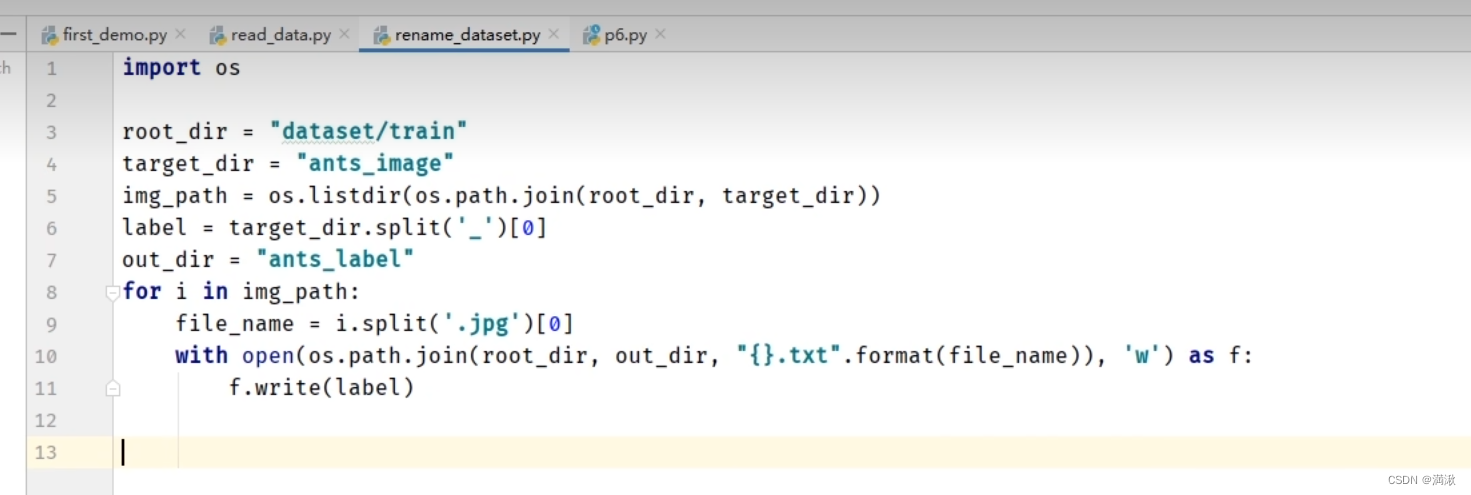
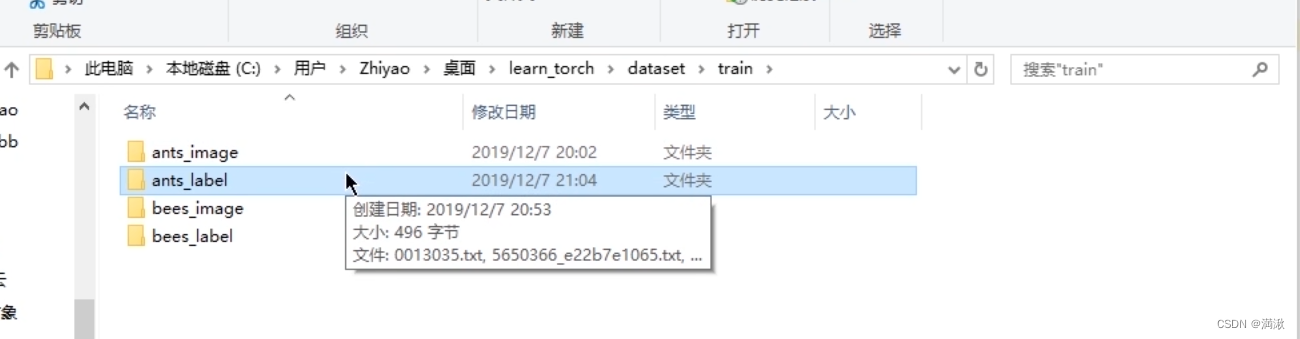
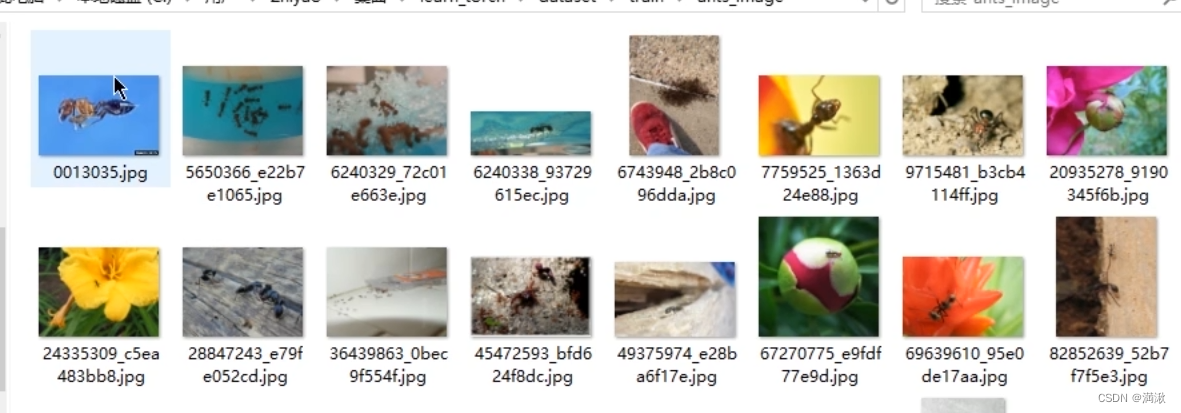
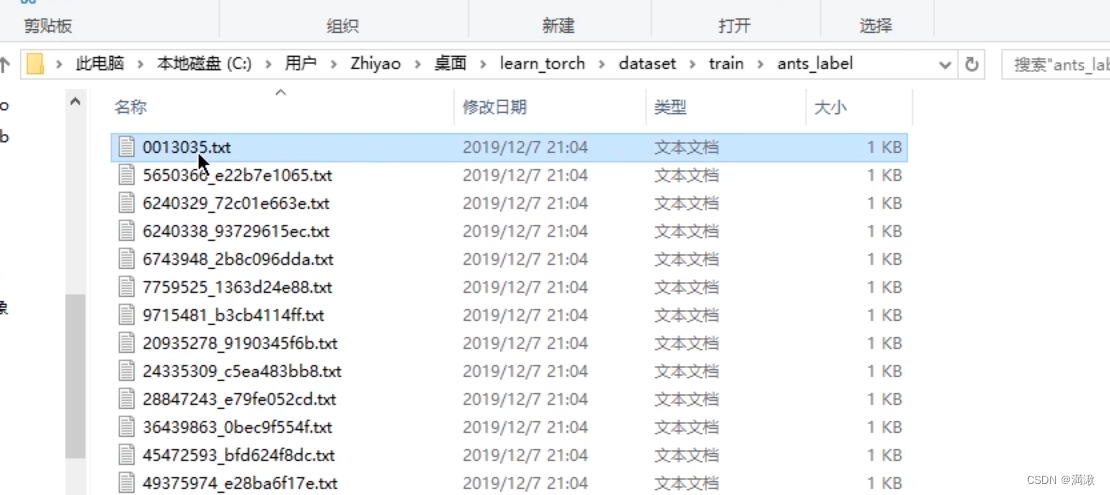
txt存储信息命名。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









