






#集合的关系
list_1=set([1,2,3,4,5,6,6,7,])
list_2=set([5,6,9,17,21,27])
print(list_1,list_2)
'''
#交集
print(list_1.intersection(list_2))
#并集
print(list_1.union(list_2))
#差集
print(list_1.difference(list_2))
#子集
list_3=set([5,6,7])
print(list_3.issubset(list_1))
print(list_1.issuperset(list_3))
#对称差集
print(list_1.symmetric_difference(list_2))
list_4=set([1,3,8])
print(list_3.isdisjoint(list_4)) #Return True if two sets have a null intersection
'''
'''
#交集intersection
print(list_1&list_2)
#并集union
print(list_1|list_2)
#差集difference
print(list_1-list_2)#in list_1 but nat in lsdt_2
#对称差集 symmetric_difference
print(list_1^list_2)
'''
#添加
list_1.add(27) #添加一项
list_1.update([21,27]) #添加多项
print(list_1)
#删除
list_1.pop()#Remove and return an arbitrary set element.Raises KeyError if the set is empty.
#list_1.remove(2)
print(list_1)
print(list_1.discard('6'))
#文件操作
#data=open('geci',encoding='utf-8').read()
'''
f=open('geci2','a',encoding='utf-8')#文件句柄#"r"文件只读#"w"文件只写#"a"文件读写
#data=f.read()
#print(data)
f.write('when i was young i learn Python')
data=f.read()
print('--read',data)
f.close()#文件关闭
'''
#f=open('geci2','r',encoding='utf-8')
'''
print(f.readline())#读1行
for i in range(5):
print(f.readline())#读5行
'''
#print(f.readlines())
'''
for index,line in enumerate(f.readlines()):
if index == 9:
print('-------------')
continue
print(line.strip())
'''#简单
'''
count=0
for line in f:
count+=1
if count==9:
print('-------------')
continue
print(line.strip())
'''
'''
print(f.readline())
print(f.tell())#把文件句柄光标的所在位置打印出来,并记录所打印字符的个数
f.seek(0)#查找返回所打印的字符
print(f.readline())
print(f.encoding)#打印文件编码
print(f.fileno())#操作系统调用文件接口的编号
print(f.name)#打印文件名字
print(f.readable())#判断文件是否可读
print(f.buffer)
print(f.flush())#将要写入的东西强制刷新写入
f.truncate()#在write模式下将文件清空,在a模式下选择保留截断文件
'''
#既能读又能写
#f=open('geci2','r+',encoding='utf-8')#这叫读写,打开文件并且可追加
f=open('geci2','w+',encoding='utf-8')
for i in range(5):
f.write('-----------NB-------------\n')
f.seek(27)
#print(f.tell())
f.write('nihenNB\n')
f.close()
f=open('geci2','a+',encoding='utf-8')#追加读写
f=open('geci2','rb')#读二进制,网络传输只能用二进制
print(f.read())
f=open('geci2','wb')#写二进制
f.write('NB'.encode())
f.close()
#进度条
import sys,time
for i in range(20):
sys.stdout.write('#')
sys.stdout.flush
time.sleep(0.1)
#文件修改
f=open('geci','r',encoding='utf-8')
f_new=open('geci.bak','w',encoding='utf-8')
for line in f:
if 'I love you' in line:
line=line.replace('I love you','我爱你')
f_new.write(line)
f.close()
f_new.close()
#with语法
with open('geci','r',encoding='utf-8')as f,\
open('geci.bak','w',encoding='utf-8')as f2:
for line in f :
line = line.replace('I love you','我爱你')
f2.write(line)
else:
f2.write(line)
f.close()
f2.close()
#编码解码
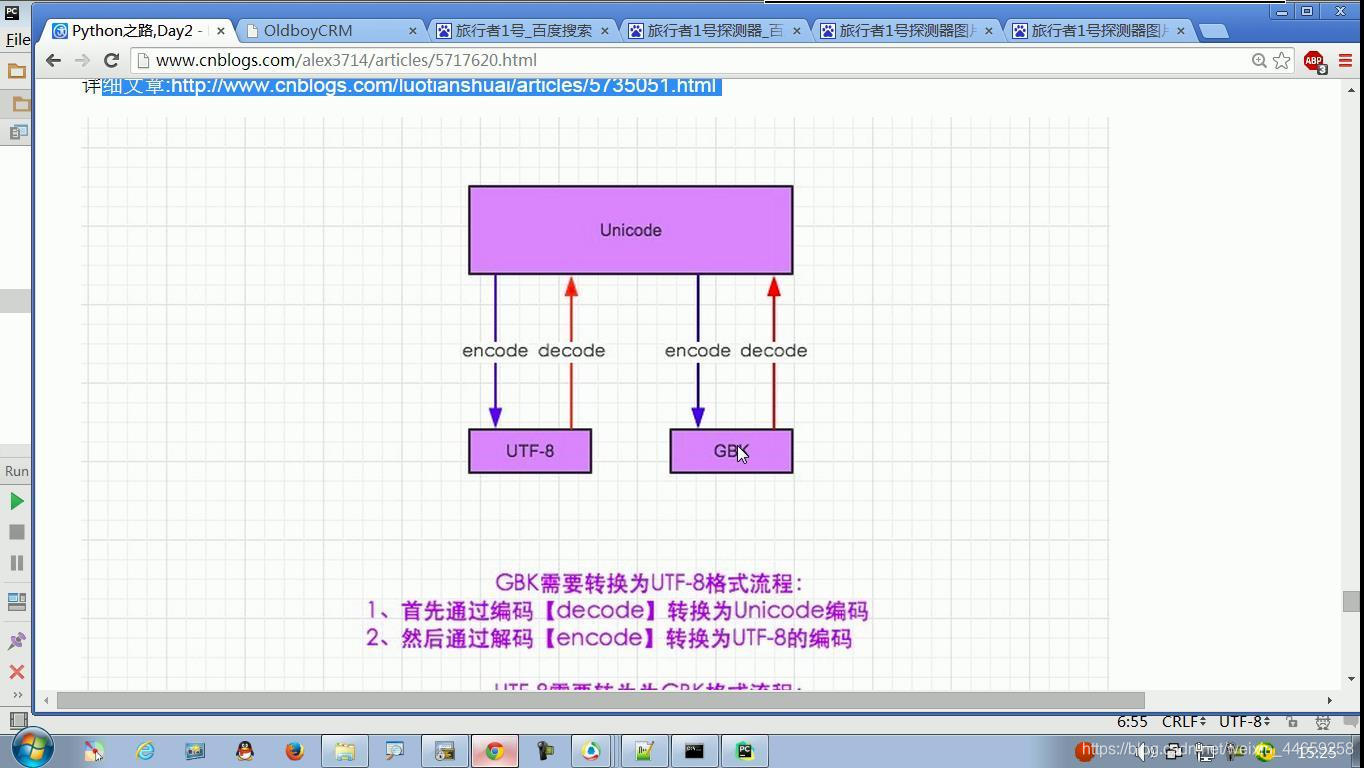
#简单的说任何编码库要转换都要先解码成unicode,在进行编码
#编程方法
1.面向对象————————》类——————》class
2.面向过程————————》过程—————》def
3.函数式编程———————》函数—————》def
#函数式编程
def test(x):
"注释此函数功能用途,对函数简单描述"
x+=1 #函数功能代码
return (x)#返回值
#面向过程
def func2():
"""testing2"""
print("in the func2")
#过程和函数都可以调用,过程就是没有返回值的函数,python中面向过程相当于返回一个none
x=func1()
y=func2()
print("from func1 return is %s"%x)
print("from func2 return is %s"%y)
#用函数实现打开文件记录并加日期格式
import time
def logger():
time_format = '%Y-%m-%d-%x'
time_current = time.strftime(time_format)
with open('a.txt','a+') as f:
f.write('%s\tI love China!\n'%time_current)
def test1():
print("in the test1")
logger()
def test2():
print("in the test2")
logger()
test1()
test2()
返回值
def test1():
print("in the test1")
#返回none
def test2():
print("in the test2")
return 0
#返回0
def test3():
print("in the test3")
return 1,"hello",['bml','ly'],{'name':'bml'}
#返回一个元组
x=test1()
y=test2()
z=test3()
print(x)
print(y)
print(z)
#运行有位置参数的函数代码
def test(x,y): # x,y代表形式参数,相当于代数,位置参数
print(x)
print(y)
test(y=2,x=1) #关键字调用
test(1,2) #位置参数调用 # 1,2代表实际参数,相当于把1,2代入学院x,y,而且要一一对应
test(2,y=3) #关键参数不能写在位置参数前面,且位置参数必须符合顺序
#默认参数
def test(x,y=2): #写形参,位置参数时直接赋值,就是默认参数
print(x)
print(y)
test(1,y=2)
#默认参数特点:调用函数时候,默认参数非必须传递
#用途:1.把需要先给值的值固定
#参数组
'''
def test(*args):
print(args)
test(1,2,3,4,5,) #当实参不固定,形参可定义成*加形参名,只能接受位置参数,转换成元组
test(*[1,2,3,4,5]) # *bml=tuple([1,2,3,4,5])
def test1(x,*args):
print(x)
print(args)
test1(1,2,3,4,5,6,7,8)
'''
'''
def test2(**kwargs):
print(kwargs)
print(kwargs['name'])
test2(name='bai',age=27) #**kwargs:把N个关键字参数,转换成字典的方式
test2(**{'name':'bai','age':27})
'''
'''
def test3(name,**kwargs):
print(name)
print(kwargs)
test3('bml',age=27)
'''
'''
def test4(name,age=27,**kwargs): #参数组要放到最后
print(name)
print(age)
print(kwargs)
test4('bml',28,sex='m')
'''
def test4(name,age=27,*args,**kwargs): #参数组要放到最后
print(name)
print(age)
print(args)
print(kwargs)
logger("test4")
def logger(source):
print('from %s'% source)
test4('bml',28,sex='m',hobby='tesla') #
#局部变量和全局变量
'''
age=27 #在函数外定义的变量就是全局变量,可在全局生效
def change_name(name):
global age #像字符串,整数类型的全局变量默认不可在函数内更改,调用global语句即可更改,不应在函数内改全局变量
age=28
print('before change',name,age)
name='BML' #在函数内定义的变量称为局部变量,这个函数就是这个变量的作用域,此变量仅在此函数内生效
print('after change',name)
print(names)
name='bml'
change_name(name)
print(name)
print(age)
'''
names=['bml','ly']
def change_name():
print(names)
names[0] = 'BML' #列表,字典类型的全局变量默认可以在函数内直接更改
change_name()
print(names)
#递归
#在函数内部,可以调用其他函数,如果一个函数在内部调用自己本身,这个函数就叫递归函数
#要求:1.必须要有明确的结束条件
# 2.每次进入更深一层递归是,问题规模相比上次递归都应有所减少
# 3.递归效率不高
def calc(n):
print(n)
if int(n/2)>0:
return calc(int(n/2))
print('->',n)
calc(10)
高阶函数
在这里插入代码片


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









