







如图,将文件夹标记为sources root后,仍然错误
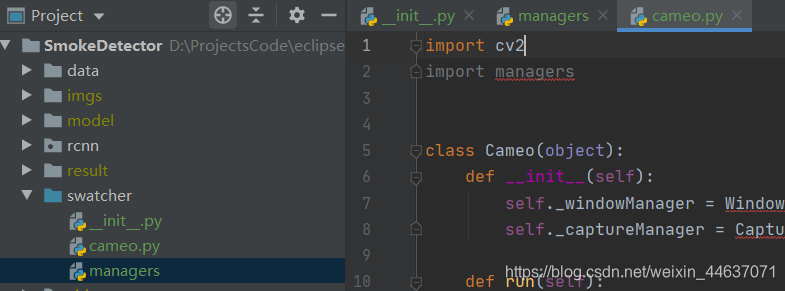 观察发现,managers文件缺少了一个精致的 ‘.py’,
观察发现,managers文件缺少了一个精致的 ‘.py’,
原因是创建managers时未选择Python File而是直接创建的File
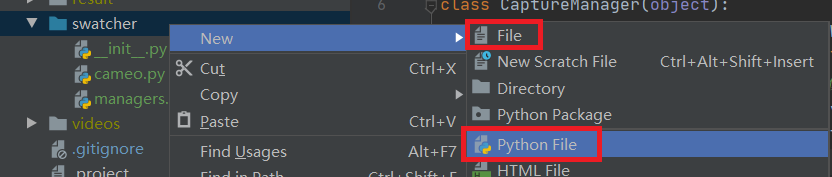
解决办法:
新建Python File(而不是File),把原来的文件内容剪切到新文件里
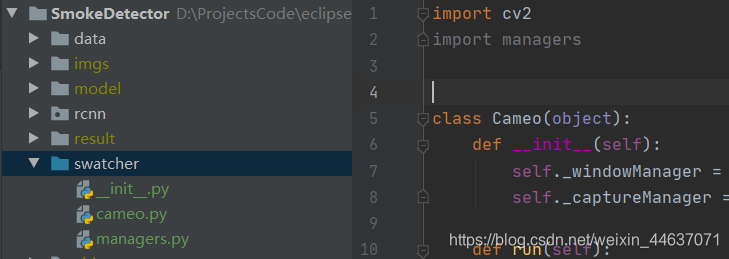
 不再有错误提示,问题解决了!
不再有错误提示,问题解决了!

















 8906
8906
05-15
如图,将文件夹标记为sources root后,仍然错误
观察发现,managers文件缺少了一个精致的 ‘.py’,
原因是创建managers时未选择Python File而是直接创建的File
解决办法:
新建Python File(而不是File),把原来的文件内容剪切到新文件里
不再有错误提示,问题解决了!

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









