






cnn的基本结构(应用于图像)
本文参考百度飞桨讲解ppt,进行总结
卷积层+激活函数+池化层+全连接层**
卷积:提取特征
卷积核的个数 = 下一层数据的深度 = 下一卷积层卷积核的深度
卷积核的个数 = 提取特征的数量 ,超参数,可以自己调节
Stride:一次滑动的步长
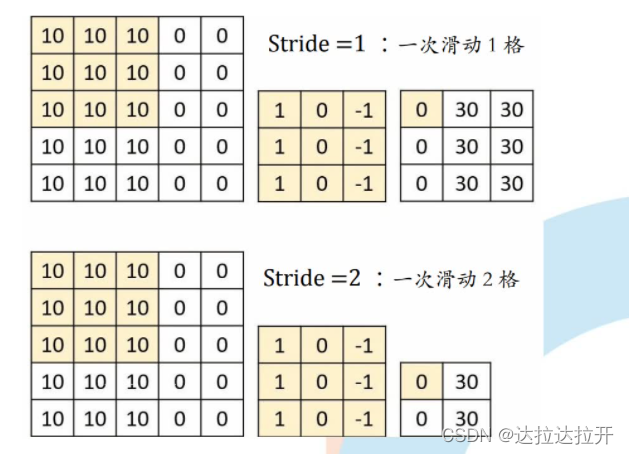
padding 填充
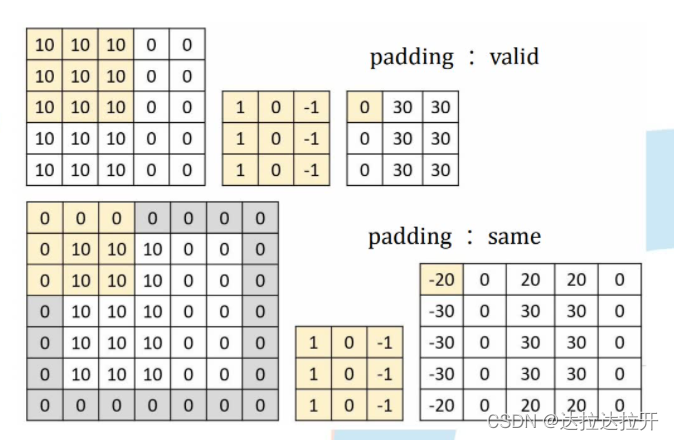
Padding = valid不进行补零操作,s=1时,每卷积一次,宽和高方向的数据维度下降F-1,其中F为卷积核大小
Padding = same在输入的周围进行0或复制填充卷积前width=卷积后width,卷积前height=卷积后height
F =3,stride =1,pad = 1
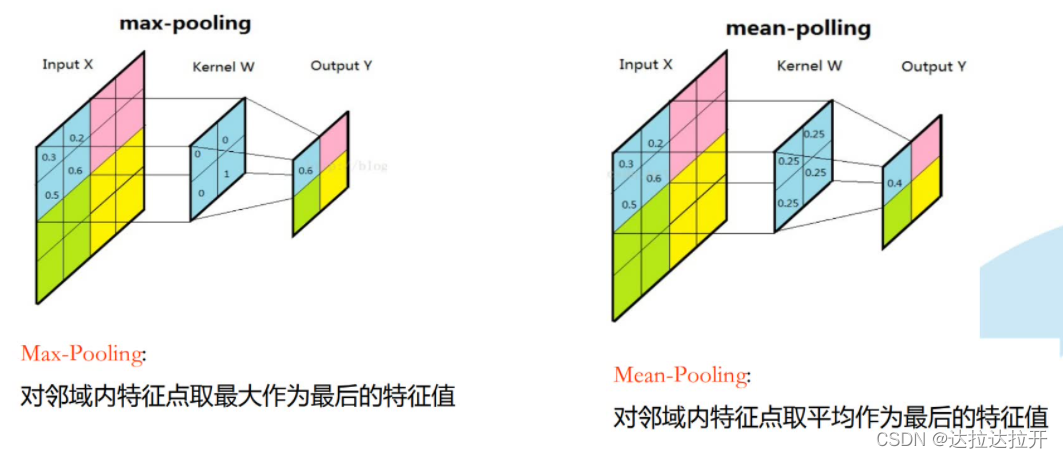
池化层
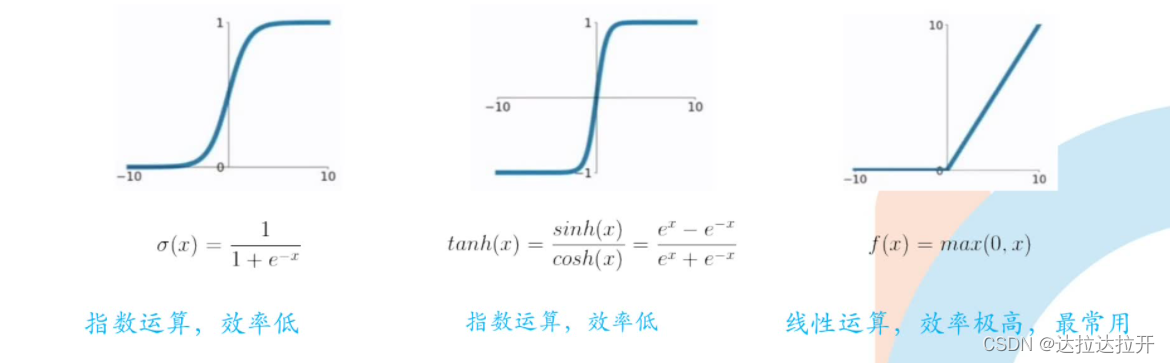
激活函数
全连接层:将多层的特征映射抻直成一个一维的向量
模型的泛化
如何提高学习算法效果?
- 降低训练误差
训练误差高:欠拟合,表现:训练集和测试集上精确度都低。实质:模型的表示能力不够。
-
缩小训练误差和测试误差的差距
训练误差和测试误差间差距大:过拟合,表现:训练集精确度高,测试集精确度低。
实质:模型模拟训练数据独有的噪声
1)高模型容量——高拟合各种函数的能力,模型偏向于过拟合。
2)正则化——对学习算法的修改,为了减少测试误差(泛化误差)而不是训练误差。
正则化 -
Early-stopping(早停法):
检测训练集和验证集上的精确度,训练集的精确度上升but验证集上的精确度下降则停止训练
- 权重正则化:
噪声相比于正常信号而言,通常会在某些点出现较大的峰值,保证权重系数在绝对值意义上小,能够保证噪声不会被过度响应,模型不应过于复杂。
- L1正则:
代表损失函数,代表参数向量w的范数 - L2正则(weight decay):
代表损失函数,代表参数向量w的范数将损失函数改写成上述方式,在最小化损失函数的过程中就会限制权重w不会过大。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









