







Go基础(三)之文件操作、命令行参数、序列化、并发编程
一、文件操作
1.1 打开和关闭文件
func Open(name string) (file *File, err error),打开文件
- Open打开一个文件用于读取。如果操作成功,返回的文件对象的方法可用于读取数据;对应的文件描述符具有O_RDONLY模式。
func OpenFile(name string, flag int, perm FileMode) (file *File, err error)
- OpenFile是一个更一般性的文件打开函数,大多数调用者都应用Open或Create代替本函数。它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。
func (f *File) Close() error,关闭文件
- Close关闭文件f,使文件不能用于读写。它返回可能出现的错误。
func main() {
//打开文件
file , err := os.Open("d:/test.txt")
if err != nil {
fmt.Println("open file err=", err)
}
//输出下文件,看看文件是什么, 看出file 就是一个指针 *File
fmt.Printf("file=%v", file)
//关闭文件
err = file.Close()
if err != nil {
fmt.Println("close file err=", err)
}
}
为了防止由于程序出现异常,而致使file.close执行不到,我们通常使用defer语句关闭文件。
1.2 读取文件
1.2.1 按字节读取:file.Read()
func (f *File) Read(b []byte) (n int, err error)
- Read方法从f中读取最多len(b)字节数据并写入b。它返回读取的字节数和可能遇到的任何错误。文件终止标志是读取0个字节且返回值err为io.EOF。
循环读:
func main() {
// 只读方式打开当前目录下的main.go文件
file, err := os.Open("./golong.txt")
if err != nil {
fmt.Println("open file failed!, err:", err)
return
}
defer file.Close()
// 循环读取文件
var content []byte
var tmp = make([]byte, 128)
for {
n, err := file.Read(tmp)
if err == io.EOF {
fmt.Println("文件读完了")
break
}
if err != nil {
fmt.Println("read file failed, err:", err)
return
}
content = append(content, tmp[:n]...)
}
fmt.Println(string(content))
}
1.2.2 bufio按行读取文件
bufio是在file的基础上封装了一层API,支持更多的功能。
func NewReader(rd io.Reader) *Reader
- NewReader创建一个具有默认大小缓冲、从r读取的*Reader。
// bufio按行读取示例
func main() {
file, err := os.Open("./golong.txt")
if err != nil {
fmt.Println("open file failed, err:", err)
return
}
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n') //注意是字符
if err == io.EOF {
if len(line) != 0 {
fmt.Println(line)
}
fmt.Println("文件读完了")
break
}
if err != nil {
fmt.Println("read file failed, err:", err)
return
}
fmt.Print(line)
}
}
1.2.3 ioutil读取整个文件
io/ioutil包的ReadFile方法
能够读取完整的文件,只需要将文件名作为参数传入。
func ReadFile(filename string) ([]byte, error)
- ReadFile 从filename指定的文件中读取数据并返回文件的内容。成功的调用返回的err为nil而非EOF。
// ioutil.ReadFile读取整个文件
func main() {
content, err := ioutil.ReadFile("./main.go")
if err != nil {
fmt.Println("read file failed, err:", err)
return
}
fmt.Println(string(content))
}
1.3 文件写入
func OpenFile(name string, flag int, perm FileMode) (file *File, err error)
-
OpenFile是一个更一般性的文件打开函数,大多数调用者都应用Open或Create代替本函数。它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。
-
name:要打开的文件名flag:打开文件的模式。 模式有以下几种:const ( O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件 O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件 O_RDWR int = syscall.O_RDWR // 读写模式打开文件 O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部 O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件 O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在 O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件 ) -
perm:文件权限,一个八进制数
-
创建文件时,我们可以指定文件的权限,文件权限总共分三种:读(r)、写(w)、执行(x),其中:
读(r):4 写(w):2 执行(x):1
-
然后一个文件可被拥有者、拥有者所在组里的其他成员、以及除此以外的其他成员读写或执行(在赋予相应的权限的前提下)。例如 0764 模式:
其中 0 后面第一个位置处的 7 代表 4 + 2 + 1,即 rwx 权限,意思就是:文件拥有者可以读写并执行该文件 7 后面的 6 代表 4 + 2 + 0,即 rw- 权限,意思就是:文件拥有者所在的组里的其他成员可对文件进行读写操作 6 后面的 4 代表 4 + 0 + 0,即 r-- 权限,意思就是:除了上面提到的用户,其余用户只能对该文件进行读操作
-
1.3.1 Write和WriteString
func (f *File) Write(b []byte) (n int, err error)
- Write向文件中写入len(b)字节数据。它返回写入的字节数和可能遇到的任何错误。如果返回值n!=len(b),本方法会返回一个非nil的错误
func (f *File) WriteString(s string) (ret int, err error)
- WriteString类似Write,但接受一个字符串参数。
func main() {
file, err := os.OpenFile("xx.txt", os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
fmt.Println("open file failed, err:", err)
return
}
defer file.Close()
str := "hello 沙河"
file.Write([]byte(str)) //写入字节切片数据
file.WriteString("hello 小王子") //直接写入字符串数据
}
1.3.2 bufio.NewWriter
func NewWriter(w io.Writer) *Writer
- NewWriter创建一个具有默认大小缓冲、写入w的*Writer
func main() {
file, err := os.OpenFile("xx.txt", os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
fmt.Println("open file failed, err:", err)
return
}
defer file.Close()
writer := bufio.NewWriter(file)
for i := 0; i < 10; i++ {
writer.WriteString("hello沙河\n") //将数据先写入缓存
}
writer.Flush() //将缓存中的内容写入文件
}
1.3.3 ioutil.WriteFile
func WriteFile(filename string, data []byte, perm os.FileMode) error
- 函数向filename指定的文件中写入数据。如果文件不存在将按给出的权限创建文件,否则在写入数据之前清空文件。
func main() {
str := "hello 沙河"
err := ioutil.WriteFile("./xx.txt", []byte(str), 0666)
if err != nil {
fmt.Println("write file failed, err:", err)
return
}
}
1.4 判断文件是否存在
golang判断文件或文件夹是否存在的方法为使用os.Stat()函数返回的错误值进行判断:
-
如果返回的错误为nil,说明文件或文件夹存在
-
如果返回的错误类型使用os.IsNotExist()判断为true,说明文件或文件夹不存在
-
如果返回的错误为其它类型,则不确定是否在存在
func IsExist(filename string) {
_, err := os.Stat(filename)
if err != nil && !os.IsNotExist(err) {
fmt.Println(err)
return
}
if os.IsNotExist(err) {
fmt.Println(filename, "不存在")
} else {
fmt.Println(filename, "存在")
}
}
func main() {
IsExist("os.txt")
}
二、命令行参数
命令行参数(或参数):是指运行程序时提供的参数;
2.1 原生方式解析
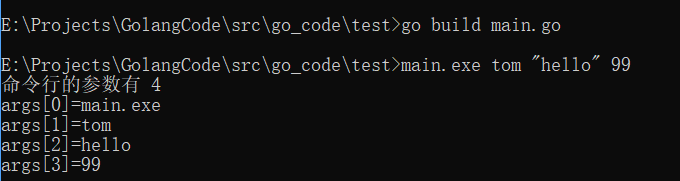
os.Args是一个string 的切片,用来存储所有的命令行参数
func main() {
fmt.Println("命令行的参数有", len(os.Args))
//遍历os.Args切片,就可以得到所有的命令行输入参数值
for i, v := range os.Args {
fmt.Printf("args[%v]=%v\n", i, v)
}
}
执行结果:
2.2 flag包用来解析命令行参数
前面的方式是比较原生的方式,对解析参数不是特别的方便,特别是带有指定参数形式的命令行。
比如: cmd>go run main.go -u root -pwd root -h 192.168.0.2 -port 3306这样的形式命令行,go 设计者给我们提供了flag包,可以方便的解析命令行参数,而且参数顺序可以随意
flag.Type(flag 名, 默认值, 帮助信息) *Type
- Type 可以是 Int、String、Bool 等,返回值为一个相应类型的指针
flag.TypeVar(Type 指针, flag 名, 默认值, 帮助信息)
- TypeVar 可以是 IntVar、StringVar、BoolVar 等,其功能为将 flag 绑定到一个变量上
flag.Parse()
- 通过以上两种方法定义好命令行 flag 参数后,需要通过调用 flag.Parse() 来对命令行参数进行解析。
支持的命令行参数格式有以下几种:
- -flag:只支持 bool 类型;
- -flag=x;
- -flag x:只支持非 bool 类型。
输入的命令行参数:

代码实现:
func main() {
//定义几个变量,用于接收命令行的参数值
var user *string
var pwd string
var host string
var port int
user = flag.String("u", "张三", "姓名")
//&pwd 就是接收用户命令行中输入的 -u 后面的参数值
//"pwd" ,就是 -pwd 指定参数
//"" , 默认值
//"用户名,默认为空" 表示对参数的说明
// flag.StringVar(&user, "u", "", "用户名,默认为空")
flag.StringVar(&pwd, "pwd", "", "密码,默认为空")
flag.StringVar(&host, "h", "localhost", "主机名,默认为localhost")
flag.IntVar(&port, "port", 3306, "端口号,默认为3306")
//这里有一个非常重要的操作,转换, 必须调用该方法
flag.Parse()
//输出结果
fmt.Printf("user=%v\npwd=%v\nhost=%v\nport=%v\n",
*user, pwd, host, port)
}
三、序列化与反序列化
参考文章:go语言序列化及反序列化
JSON是一种轻量级的数据交换格式,常用在前后端数据交换,go的encoding/json提供了对json的支持
3.1 序列化
func Marshal(v interface{}) ([]byte, error)
-
把 Go struct 序列化成 JSON对象
-
举例:
type Message struct { Name string Body string Time int64 } func main() { m := Message{"Alice", "Hello", 1294706395881547000} b, _ := json.Marshal(m) fmt.Println(string(b)) //{"Name":"Alice","Body":"Hello","Time":1294706395881547000} }
注意:
- 只支持struct中导出的field才能被序列化,即
首字母大写的field - GO中不是所有类型都支持序列化,其中key只支持string
- 无法对channel,complex,function序列化
- 数据中如存在循环引用,不支持序列化,因为会递归。
- pointer序列化后是其指向的值或者是nil
Struct Tag:
-
Struct tag 可以决定 Marshal 和 Unmarshal 函数如何序列化和反序列化数据。指定JSON filed name
-
JSON object 中的 name 一般都是小写,我们可以通过 struct tag 来实现:
指定 field 是 empty:
-
使用
omitempty可以告诉 Marshal 函数如果 field 的值是对应类型的 zero-value,那么序列化之后的 JSON object 中不包含此 field:type MyStruct struct { SomeField string `json:"some_field,omitempty"` }如果
SomeField == “”,序列化之后的对象就是{}。
跳过 field:
-
Struct tag “-” 表示跳过指定的 filed
type MyStruct struct { SomeField string `json:"some_field"` Passwd string `json:"-"` }即序列化的时候不输出,这样可以有效保护需要保护的字段不被序列化。
type Person struct {
Name string `json:"name"`
Gender string `json:"gender"`
Age uint32 `json:"age,omitempty"`
Passwd string `json:"-"`
}
func main() {
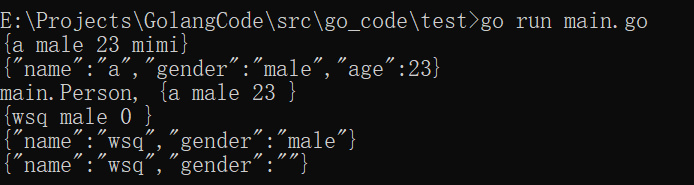
// 默认初始化
p := Person{"a", "male", 23, "mimi"}
fmt.Printf("%v\n", p) //{a male 23}
// 序列化
b, _ := json.Marshal(p)
fmt.Println(string(b)) //{"Name":"a","Gender":"male","Age":23}
// 反序列化
var pp Person
err := json.Unmarshal(b, &pp)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
fmt.Printf("%T, %v\n", pp, pp) //main.Person, {a male 23 }
// 指定成员初始化
p1 := Person{Name: "wsq", Gender: "male"}
fmt.Println(p1) //{wsq male 0}
// 指定field是empty时的行为
d, _ := json.Marshal(p1)
fmt.Println(string(d)) //{"name":"wsq","gender":"male"}
// 跳过指定field
importPerson := Person{Name: "wsq", Passwd: "password"}
importPersonMar, _ := json.Marshal(importPerson)
fmt.Println(string(importPersonMar)) //{"name":"wsq","gender":""}
}
执行结果:
3.2 反序列化
func Unmarshal(data []byte, v interface{}) error
- 反序列化函数:Unmarshal函数解析json编码的数据并将结果存入v指向的值
b := []byte(`{"Name":"Wednesday","Age":6,"Parents":["Gomez","Morticia"]}`)
var f interface{}
err := json.Unmarshal(b, &f)
if err != nil {
errors.New("unmarshal error")
}
fmt.Printf("%T, %v\n", f, f)
结构体、map和切片的序列化和反序列化:
//定义一个结构体
type Monster struct {
Name string
Age int
Birthday string //....
Sal float64
Skill string
}
//演示将json字符串,反序列化成struct
func unmarshalStruct() {
//说明str 在项目开发中,是通过网络传输获取到.. 或者是读取文件获取到
str := "{\"Name\":\"牛魔王~~~\",\"Age\":500,\"Birthday\":\"2011-11-11\",\"Sal\":8000,\"Skill\":\"牛魔拳\"}"
//定义一个Monster实例
var monster Monster
err := json.Unmarshal([]byte(str), &monster)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 monster=%v monster.Name=%v \n", monster, monster.Name)
}
//将map进行序列化
func testMap() string {
//定义一个map
var a map[string]interface{}
//使用map,需要make
a = make(map[string]interface{})
a["name"] = "红孩儿~~~~~~"
a["age"] = 30
a["address"] = "洪崖洞"
//将a这个map进行序列化
//将monster 序列化
data, err := json.Marshal(a)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("a map 序列化后=%v\n", string(data))
return string(data)
}
//演示将json字符串,反序列化成map
func unmarshalMap() {
//str := "{\"address\":\"洪崖洞\",\"age\":30,\"name\":\"红孩儿\"}"
str := testMap()
//定义一个map
var a map[string]interface{}
//反序列化
//注意:反序列化map,不需要make,因为make操作被封装到 Unmarshal函数
err := json.Unmarshal([]byte(str), &a)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 a=%v\n", a)
}
//演示将json字符串,反序列化成切片
func unmarshalSlice() {
var slice []map[string]interface{}
var m1 map[string]interface{}
//使用map前,需要先make
m1 = make(map[string]interface{})
m1["name"] = "jack"
m1["age"] = "7"
m1["address"] = "北京"
slice = append(slice, m1)
var m2 map[string]interface{}
//使用map前,需要先make
m2 = make(map[string]interface{})
m2["name"] = "tom"
m2["age"] = "20"
m2["address"] = [2]string{"墨西哥","夏威夷"}
slice = append(slice, m2)
//将切片进行序列化操作
data, err := json.Marshal(slice)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("slice 序列化后=%v\n", string(data))
//定义一个slice
var ans []map[string]interface{}
//反序列化,不需要make,因为make操作被封装到 Unmarshal函数
err = json.Unmarshal(data, &ans)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 slice=%v\n", slice)
}
func main() {
unmarshalStruct()
unmarshalMap()
unmarshalSlice()
}
执行结果:

四、并发编程
好的博客:
4.1 MPG模型
Go 中的 MPG 线程模型对两级线程模型进行一定程度的改进,使它能够更加灵活地进行线程之间的调度。它由三个主要模块构成,如图所示:
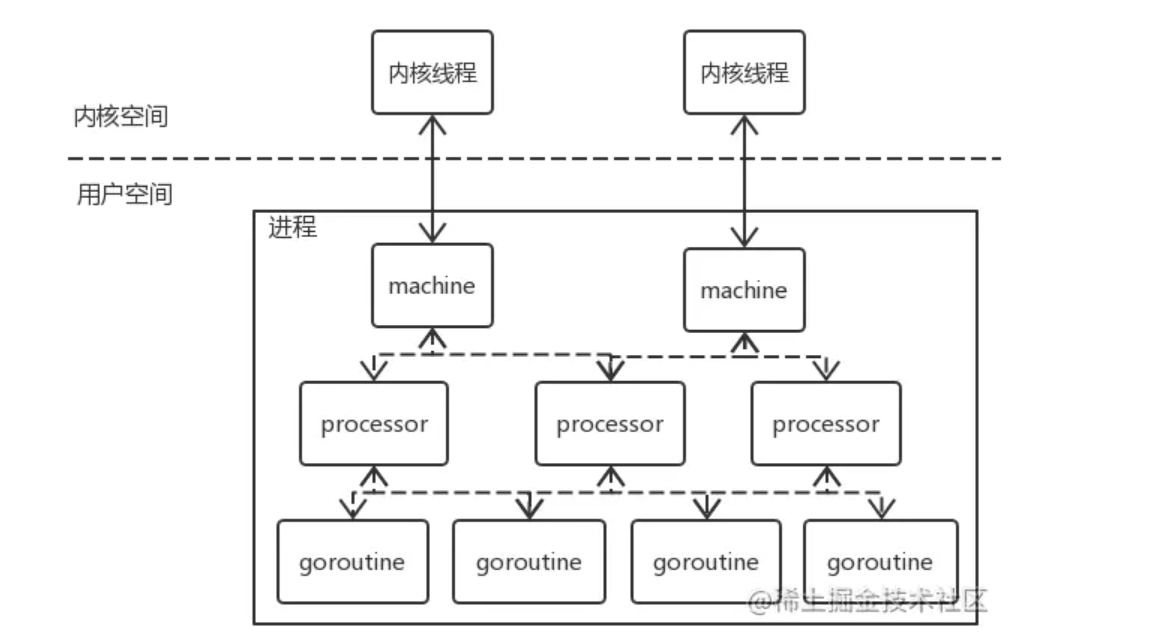
- machine,一个 machine 对应一个内核线程,相当于内核线程在 Go 进程中的映射
- processor,一个 prcessor 表示执行 Go 代码片段的所必需的上下文环境,可以理解为用户代码逻辑的处理器
- goroutine,协程,是对 Go 中代码片段的封装,其实是一种轻量级的用户线程。
MPG模式运行的状态一:
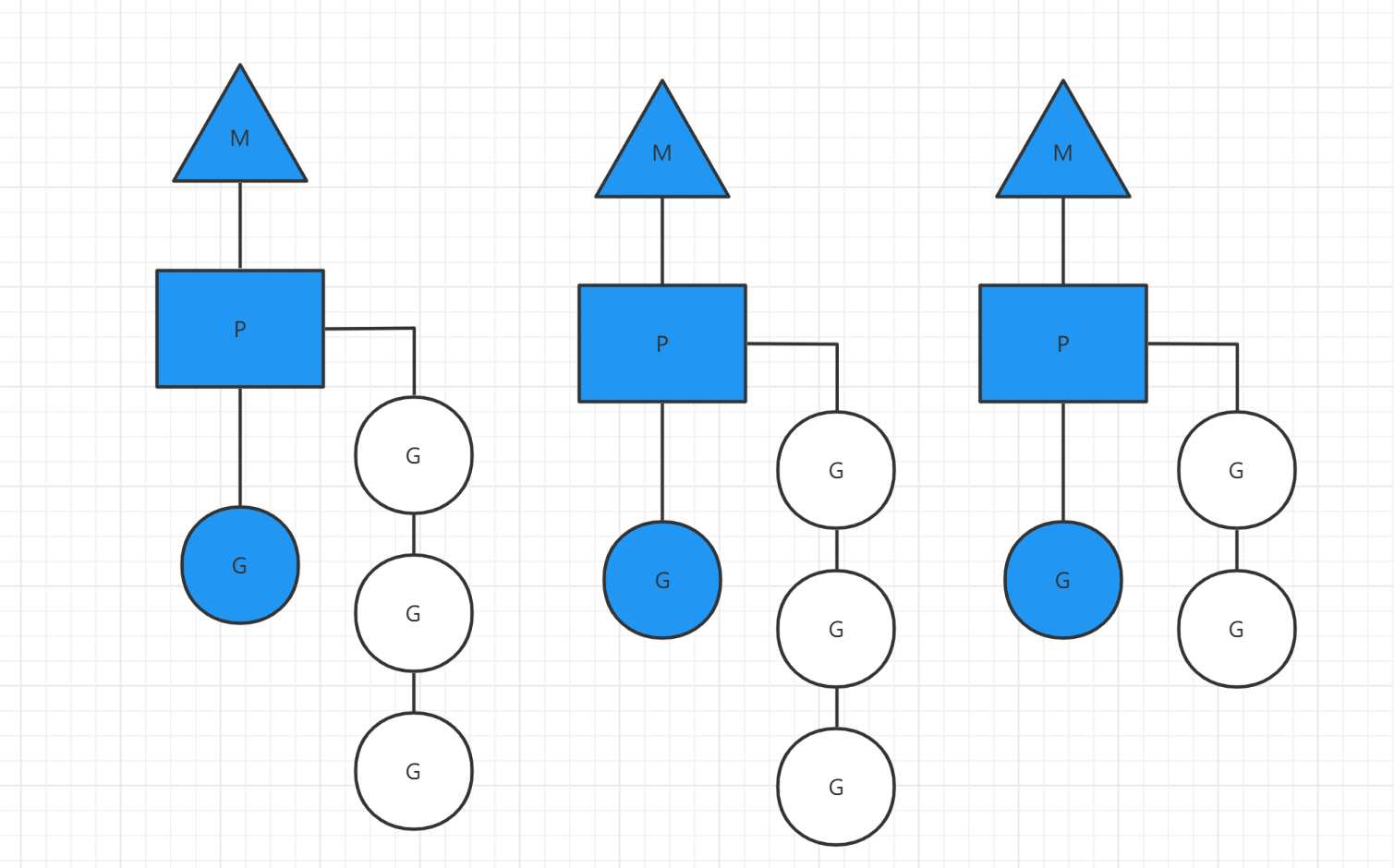
- 当前程序有三个M,如果三个M都在一个cpu运行,就是并发,如果在不同的cpu运行就是并行
- M1,M2,M3正在执行一个G,M1的协程队列有三个,M2的协程队列有3个,M3协程队列有2个
MPG模式运行的状态二:
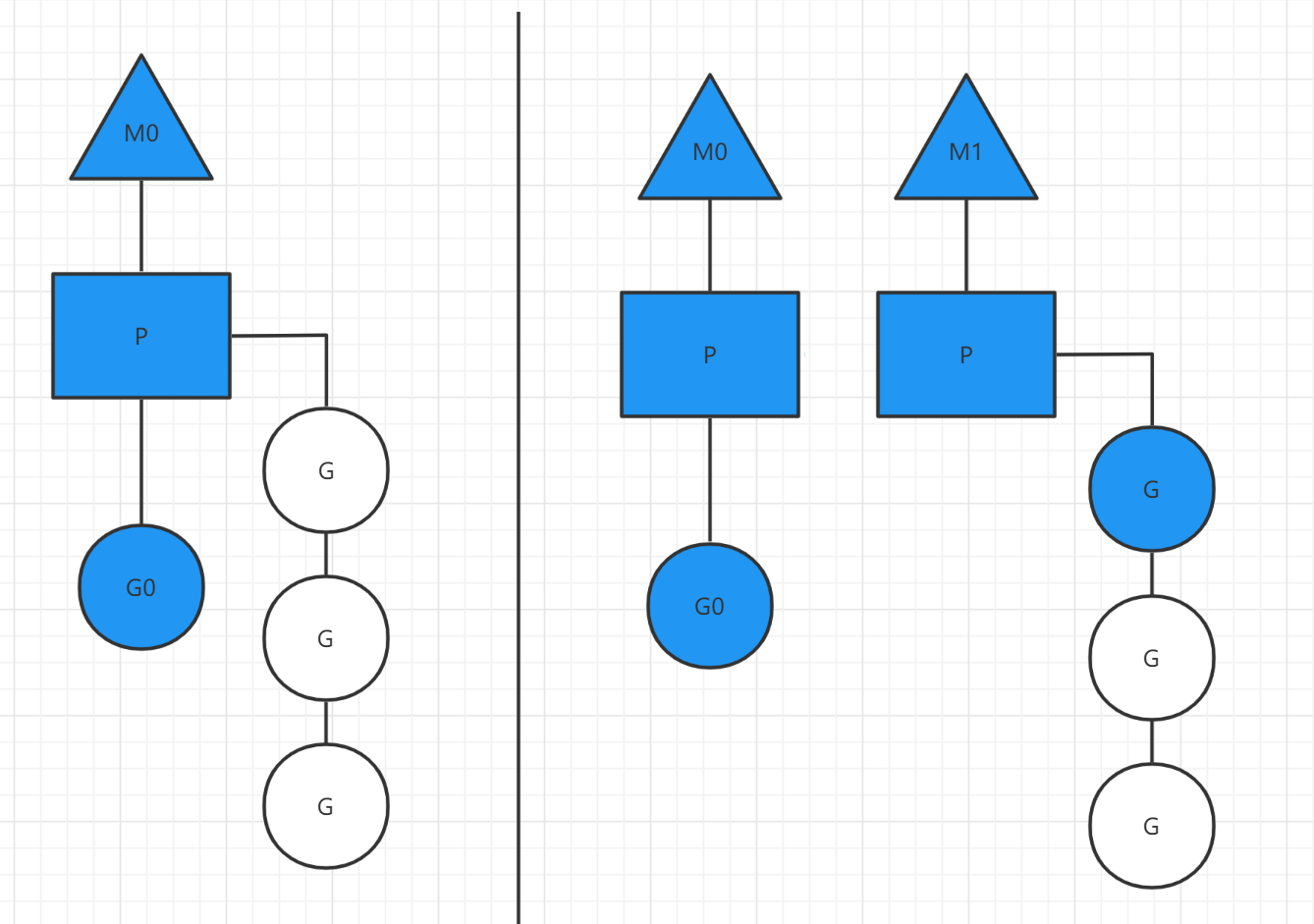
- 分成两个部分来看
- 原来的情况是MO主线程正在执行GO协程,另外有三个协程在队列等待
- 如果GO协程阻塞,比如读取文件或者数据库等,这时就会创建M1主线程(也可能是从已有的线程池中取出M1),并且将等待的3个协程挂到M1下开始执行, MO的主线程下的GO仍然执行文件io的读写。
- 这样的MPG调度模式,可以既让GO执行,同时也不会让队列的其它协程一直阻塞,仍然可以并发/并行执行。
- 等到G0不阻塞了,MO会被放到空闲的主线程继续执行(从已有的线程池中取),同时G0又会被唤醒。
4.2 goroutine
协程:coroutine。也叫轻量级线程。
与传统的系统级线程和进程相比,协程最大的优势在于“轻量级”。可以轻松创建上万个而不会导致系统资源衰竭。而线程和进程通常很难超过1万个。这也是协程别称“轻量级线程”的原因。
一个线程中可以有任意多个协程,但某一时刻只能有一个协程在运行,多个协程分享该线程分配到的计算机资源。
什么是goroutine?
-
goroutine 是轻量级线程,goroutine 的调度是由 Golang 运行时进行管理的
-
goroutine是Go并行设计的核心。goroutine说到底其实就是协程,它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
-
一般情况下,一个普通计算机跑几十个线程就有点负载过大了,但是同样的机器却可以轻松地让成百上千个goroutine进行资源竞争。
goroutine的创建:
-
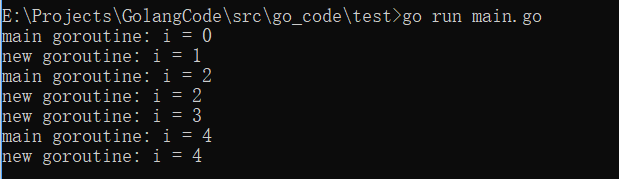
只需在函数调⽤语句前添加
go关键字,就可创建并发执⾏单元func newTask() { i := 0 for { i++ fmt.Printf("new goroutine: i = %d\n", i) time.Sleep(time.Second) //延时1秒 } } func main() { //创建一个goroutine,启动另外一个任务。开启携程 go newTask() //循环打印 for i := 0; i < 5; i++ { fmt.Printf("main goroutine: i = %d\n", i) time.Sleep(time.Second) //延时1秒 i++ } }执行结果:可以看到执行结果没有固定先后顺序
-
注意:主goroutine退出后,其它的工作的子goroutine也会自动退出
runtime包:
runtime.Gosched()
-
runtime.Gosched() 用于让出CPU时间片,让出当前goroutine的执行权限,调度器安排其他等待的任务运行,并在下次再获得cpu时间轮片的时候,从该出让cpu的位置恢复执行。
示例代码:
func main() { //创建一个goroutine go func(s string) { for i := 0; i < 2; i++ { fmt.Println(s) } }("world") for i := 0; i < 2; i++ { runtime.Gosched() //让出当前住线程的执行权限 fmt.Println("hello") } /* 添加runtime.Gosched()运行结果如下: world world hello hello 注释runtime.Gosched()运行结果如下: hello hello */ }以上程序的执行过程如下:
主协程进入main()函数,进行代码的执行。当执行到go func()匿名函数时,创建一个新的协程,开始执行匿名函数中的代码,主协程继续向下执行,执行到runtime.Gosched( )时会暂停向下执行,直到其它协程执行完后或时间片用完,再回到该位置,主协程继续向下执行。
runtime.Goexit()
-
调用 runtime.Goexit() 将立即终止当前 goroutine 执⾏,调度器确保所有已注册 defer延迟调用被执行。
示例代码:
func main() { go func() { defer fmt.Println("A.defer") func() { defer fmt.Println("B.defer") runtime.Goexit()//终止当前 goroutine, import "runtime" fmt.Println("B") //不会执行 }() fmt.Println("A") //不会执行 }() //死循环,目的不让主goroutine结束 for {} }程序运行结果:

runtime.GOMAXPROCS()
-
调用 runtime.GOMAXPROCS() 用来设置可以并行计算的CPU核数的最大值,并返回之前的值。(默认是跑满整个CPU)
示例代码:
func main() { //n := runtime.GOMAXPROCS(1) //第一次 测试 //打印结果: 111111111111111111111111110000000000000000000000000.... n := runtime.GOMAXPROCS(2) //第二次 测试 //打印结果: 1111111111111111111111110000000000000011111110000100000000111100001111 fmt.Println(n) for { go fmt.Print(0) fmt.Print(1) } }在第一次执行runtime.GOMAXPROCS(1) 时,最多同时只能有一个goroutine被执行。所以会打印很多1。过了一段时间后,GO调度器会将其置为休眠,并唤醒另一个goroutine,这时候就开始打印很多0了,在打印的时候,goroutine是被调度到操作系统线程上的。
在第二次执行runtime.GOMAXPROCS(2) 时, 我们使用了两个CPU,所以两个goroutine可以一起被执行,以同样的频率交替打印0和1。
4.3 channel
channel是一个引用数据类型,数据是先进先出的。主要用来解决协程 goroutine 的同步问题以及协程之间数据共享(数据传递)的问题。
引⽤类型 channel可用于多个 goroutine 通讯。其内部实现了同步,确保并发安全。
4.3.1 channel的使用
-
使用chan关键字即可,通道在使用前必须先创建
-
定义一个channel时,也需要定义发送到channel的值的类型。channel可以使用内置的make()函数来创建:
//声明 var intChan chan int = make(chan int) //intChan用于存放int数据 var mapChan chan map[int]string //mapChan用于存放map[int]string类型 //创建 make(chan Type) //等价于make(chan Type, 0) make(chan Type, capacity) -
当参数capacity= 0 时,channel 是无缓冲阻塞读写的;当capacity > 0 时,channel 有缓冲、是非阻塞的,直到写满 capacity个元素才阻塞写入。
-
channel通过操作符 <- 来接收和发送数据,发送和接收数据语法:
channel <- value //发送value到channel <- channel //取出channel里的一个值并丢弃 x := <-channel //从channel中接收数据,并赋值给x x, ok := <-channel //功能同上,同时检查通道是否已关闭或者是否为空 -
默认情况下,无缓冲的channel接收和发送数据都是阻塞的,除非另一端已经准备好,这样就使得goroutine同步变的更加的简单,而不需要显式的lock。
示例代码:
func main() {
c := make(chan int)
go func() {
defer fmt.Println("子协程结束")
fmt.Println("子协程正在运行.....")
c <- 666 //666发送到c
}()
num := <-c //从c中接收数据,并赋值给num
fmt.Println("num = ", num)
fmt.Println("main协程结束")
}
程序运行结果:

4.3.2 无缓冲的channel
-
这种类型的通道要求发送goroutine和接收goroutine同时准备好,才能完成发送和接收操作。否则,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。
-
无缓冲的channel创建格式:
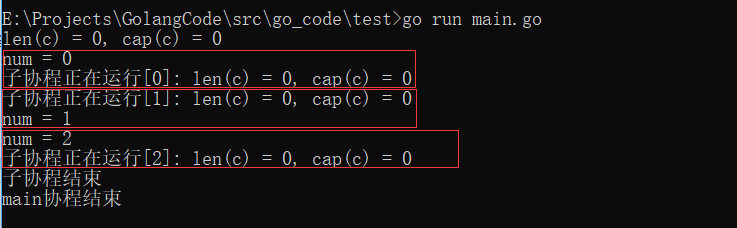
make(chan Type) //等价于make(chan Type, 0)代码示例:
func main() { c := make(chan int, 0) //创建无缓冲的通道c //内置函数len返回未被读取的缓冲元素数量,cap返回缓冲区大小 fmt.Printf("len(c) = %d, cap(c) = %d\n", len(c), cap(c)) go func() { defer fmt.Println("子协程结束") for i := 0; i < 3; i++ { c <- i fmt.Printf("子协程正在运行[%d]: len(c) = %d, cap(c) = %d\n", i, len(c), cap(c)) } }() time.Sleep(time.Second * 2) //延时2s for i := 0; i < 3; i++ { num := <-c //从c中接收数据,并复制给num fmt.Printf("num = %d\n", num) } fmt.Println("main协程结束") }执行结果:
4.3.3 有缓冲的channel
-
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个数据值的通道。
-
如果给定了一个缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
-
只有通道中没有可以接收的值时,接收动作才会阻塞。只有通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
-
有缓冲的channel创建格式:
make(chan Type, capacity)
示例代码:
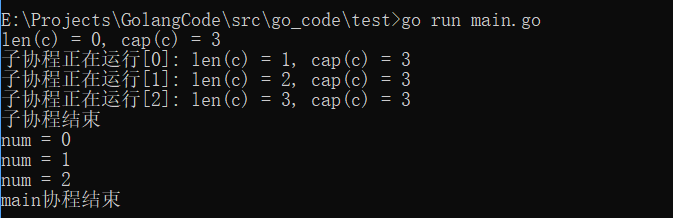
package main
import (
"fmt"
"time"
)
func main() {
c := make(chan int, 3) //创建无缓冲的通道c
//内置函数len返回未被读取的缓冲元素数量,cap返回缓冲区大小
fmt.Printf("len(c) = %d, cap(c) = %d\n", len(c), cap(c))
go func() {
defer fmt.Println("子协程结束")
for i := 0; i < 3; i++ {
c <- i
fmt.Printf("子协程正在运行[%d]: len(c) = %d, cap(c) = %d\n", i, len(c), cap(c))
}
}()
time.Sleep(time.Second * 2) //延时2s
for i := 0; i < 3; i++ {
num := <-c //从c中接收数据,并复制给num
fmt.Printf("num = %d\n", num)
}
fmt.Println("main协程结束")
}
执行结果:
4.3.4 channel的关闭和遍历
channel的关闭:
- 使用内置函数 close()可以关闭channel,当channel 关闭后,就不能再向channel写数据了,但是仍然可以从该channel读取数据
示例代码:
func main() {
intChan := make(chan int, 3)
intChan<- 100
intChan<- 200
close(intChan) // close
//这是不能够再写入数到channel,会报错
//intChan<- 300
fmt.Println("okook~")
//当管道关闭后,读取数据是可以的
n1 := <-intChan
fmt.Println("n1=", n1)
}
channel的遍历:
channel支持for–range的方式进行遍历,注意遍历是channel必须关闭
- 在遍历时,如果channel没有关闭,则回出现deadlock 的错误
- 在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历。
func main() {
//遍历管道
intChan2 := make(chan int, 100)
for i := 0; i < 5; i++ {
intChan2<- i * 2 //放入100个数据到管道
}
//遍历管道不能使用普通的 for 循环
//在遍历时,如果channel没有关闭,则会出现deadlock的错误
//在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
close(intChan2)
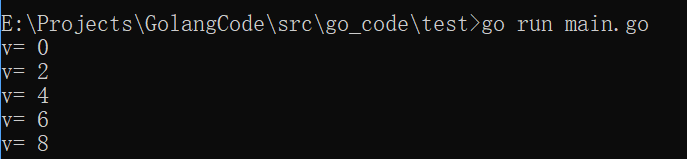
for v := range intChan2 {
fmt.Println("v=", v)
}
}
执行结果:
4.3.5 单向channel
- channel 可以声明为只读,或者只写性质。即单向通道
chan<- int是一个只能发送的通道,可以发送但是不能接收;<-chan int是一个只能接收的通道,可以接收但是不能发送。
//in变量为只写
func counter(in chan<- int) {
for i := 0; i < 5; i++ {
in <- i
}
close(in)
}
//in变量为只写,out变量为只读
func squarer(in chan<- int, out <-chan int) {
for i := range out {
in <- i * i
}
close(in)
}
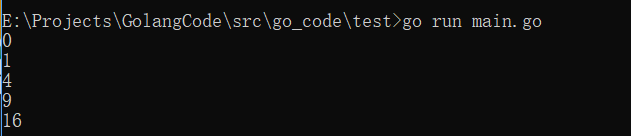
func printer(in <-chan int) {
for i := range in {
fmt.Println(i)
}
}
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go counter(ch1)
go squarer(ch2, ch1)
printer(ch2)
}
执行结果:
注意:在函数传参及任何赋值操作中将双向通道转换为单向通道是可以的,但反过来是不可以的。
4.3.6 select
Go里面提供了一个关键字select,通过select可以监听channel上的数据流动。select的用法与switch语言非常类似,由select开始一个新的选择块,每个选择条件由case语句来描述。
与switch语句相比, select有比较多的限制,其中最大的一条限制就是每个case语句里必须是一个IO操作,大致的结构如下:
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
执行流程:
- 在一个select语句中,Go语言会按顺序从头至尾评估每一个发送和接收的语句。
- 如果其中的任意一语句可以继续执行(即没有被阻塞),那么就从那些可以执行的语句中任意选择一条来使用。
- 如果没有任意一条语句可以执行(即所有的通道都被阻塞),那么有两种可能的情况:
- 如果给出了default语句,那么就会执行default语句,同时程序的执行会从select语句后的语句中恢复。
- 如果没有default语句,那么select语句将被阻塞,直到至少有一个通信可以进行下去。
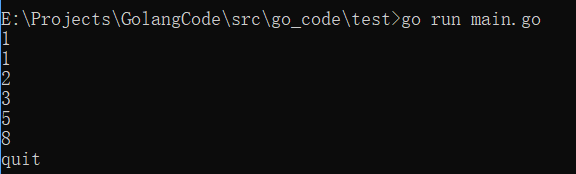
func fibonacci(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <-x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 6; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
运行结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









