



 本文探讨了自注意力框架在处理向量序列中的应用,其中每个输入向量可以与序列中所有其他位置的向量计算相似度。通过查询(Q)、键(K)和值(V)的概念,确定每个位置的重要性,并最终生成输出。该机制广泛应用于翻译任务等场景,其中模型自行决定输出的数量。计算过程涉及QKV矩阵的生成和位置重要性的量化,以确定最终的序列标签。
本文探讨了自注意力框架在处理向量序列中的应用,其中每个输入向量可以与序列中所有其他位置的向量计算相似度。通过查询(Q)、键(K)和值(V)的概念,确定每个位置的重要性,并最终生成输出。该机制广泛应用于翻译任务等场景,其中模型自行决定输出的数量。计算过程涉及QKV矩阵的生成和位置重要性的量化,以确定最终的序列标签。
输入:一堆向量(文字、语音、图...)
输出:
1.一个节点一个label(输入输出对应)
2.整个序列有一个label(输入的序列对应一个输出)
3.模型决定自己输出数目(如:翻译)
self-attention框架
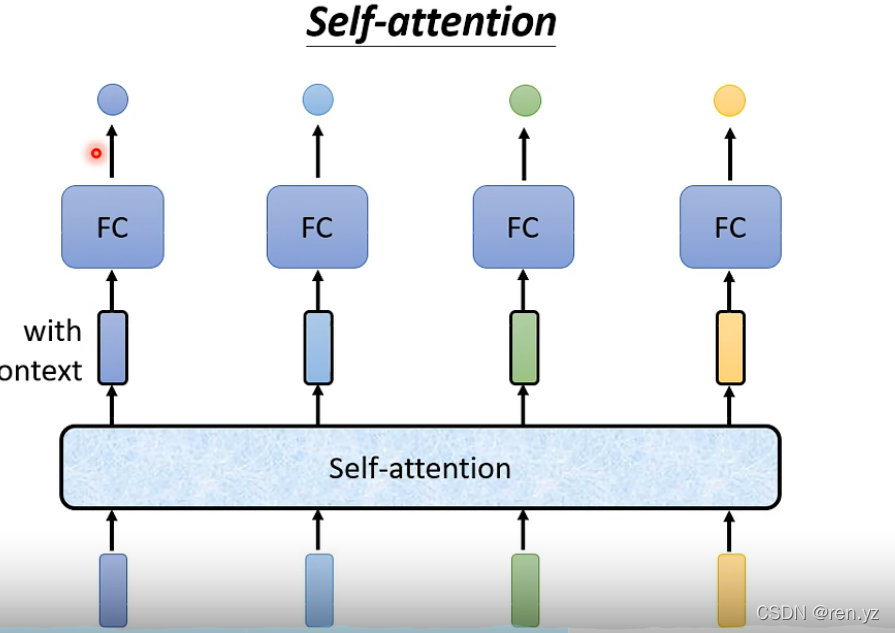
如图,每一个输出对应所有位置的输入, 每一个位置的输入需要计算和其他位置输入的相似度,计算方法为:
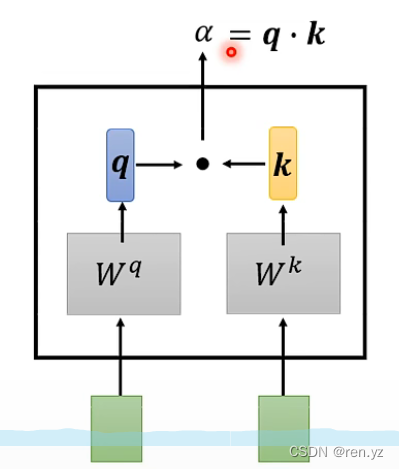
wq和wk为超参数,a为最终计算的相似度结果
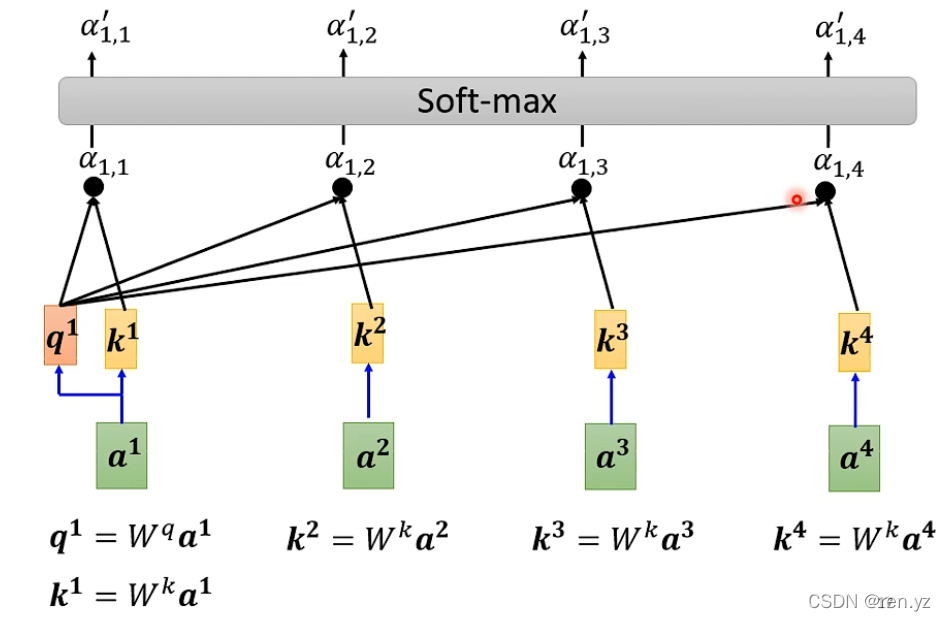
每一个输入对应一对q k,q查询向量 ,k被查向量,通过上述操作求出哪个向量和a1最相关,qk是位置关系,那如何通过位置重要度求最终的输出向量,引入v(v是携带信息的值)
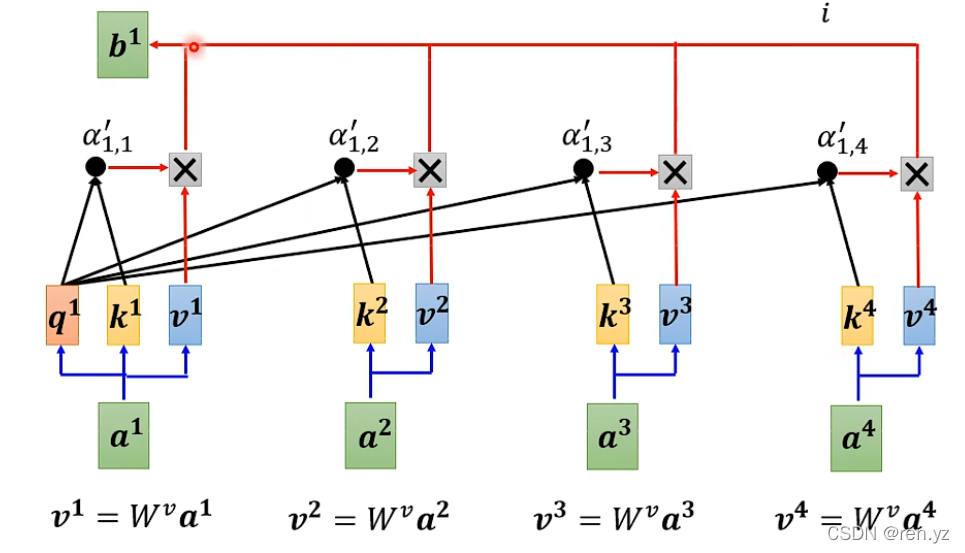
计算公式
如何从a得到QKV?QKV是矩阵:
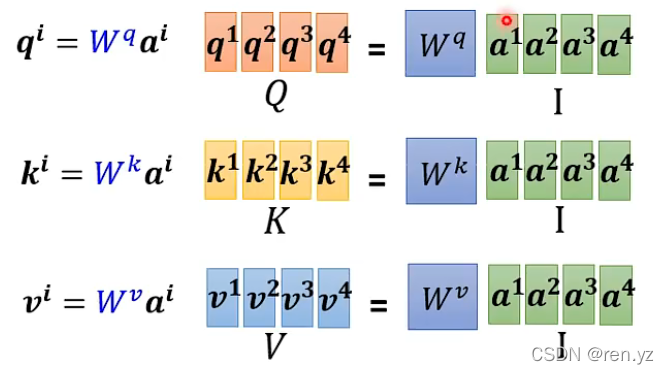
如何从QKV得打的这些位置重要性结果:
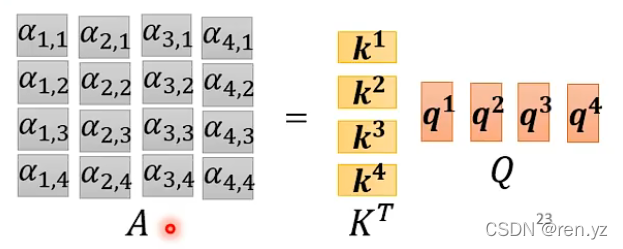
如何求b
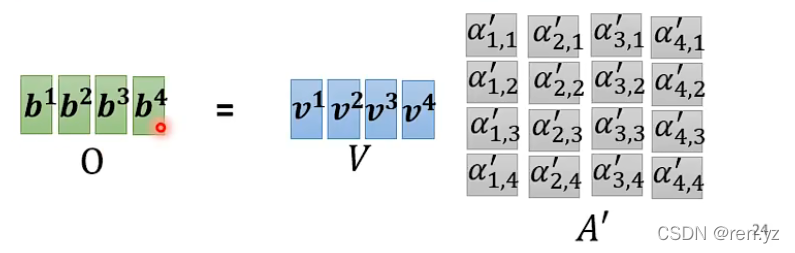
总体框架:
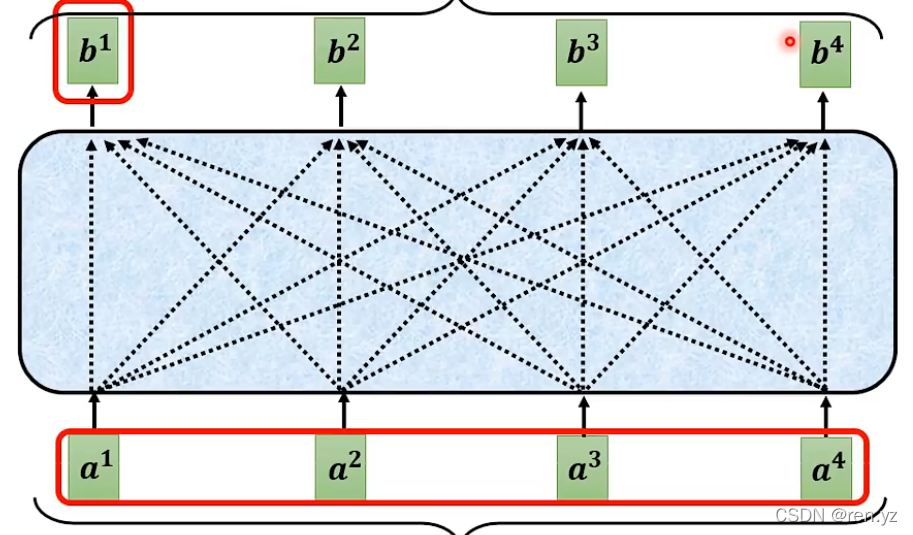

















 7840
7840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









