







 本文介绍了如何使用LinkedBlockingQueue实现简易线程池,对比了LinkedBlockingQueue与其他阻塞队列的区别,如ArrayBlockingQueue,强调了其无界特性可能导致的内存溢出问题,并详细解析了LinkedBlockingQueue的底层方法和常用函数,最后提供了简易版线程池的代码实现和总结。
本文介绍了如何使用LinkedBlockingQueue实现简易线程池,对比了LinkedBlockingQueue与其他阻塞队列的区别,如ArrayBlockingQueue,强调了其无界特性可能导致的内存溢出问题,并详细解析了LinkedBlockingQueue的底层方法和常用函数,最后提供了简易版线程池的代码实现和总结。
前一阵子在做联系人的导入功能,使用POI组件解析Excel文件后获取到联系人列表,校验之后批量导入。单从技术层面来说,导入操作通常情况下是一个比较耗时的操作,而且如果联系人达到几万、几十万级别,必须拆分成为子任务来执行。综上,可以使用线程池来解决问题。技术选型上,没有采用已有的 ThreadPoolExecutor 框架,而使用了自制的简易版线程池。该简易版的线程池,其实也是一个简易版的【生产者-消费者】模型,任务的加入就像是生产的过程,任务的处理就像是消费的过程。我们在这里不去讨论方案的合理性,只是从技术层面总结一下在实现简易版线程池的过程中,我所学到的知识。
代码放在Github上,分享一下:
https://github.com/Julius-Liu/threadpool
一、线程池设计
我们首先使用数组 ArrayList 来作为线程池的存储结构,例如数组大小为10就意味着这是一个大小为10的线程池。然后我们使用 LinkedBlockingQueue(链式阻塞队列)来存放线程的参数。示意图如下:
当线程池里的线程初始化完成后,我们希望线程都处于【饥饿】状态,随时等待参数传入,然后执行。所以,此时线程应该处于阻塞状态,如下图所示:
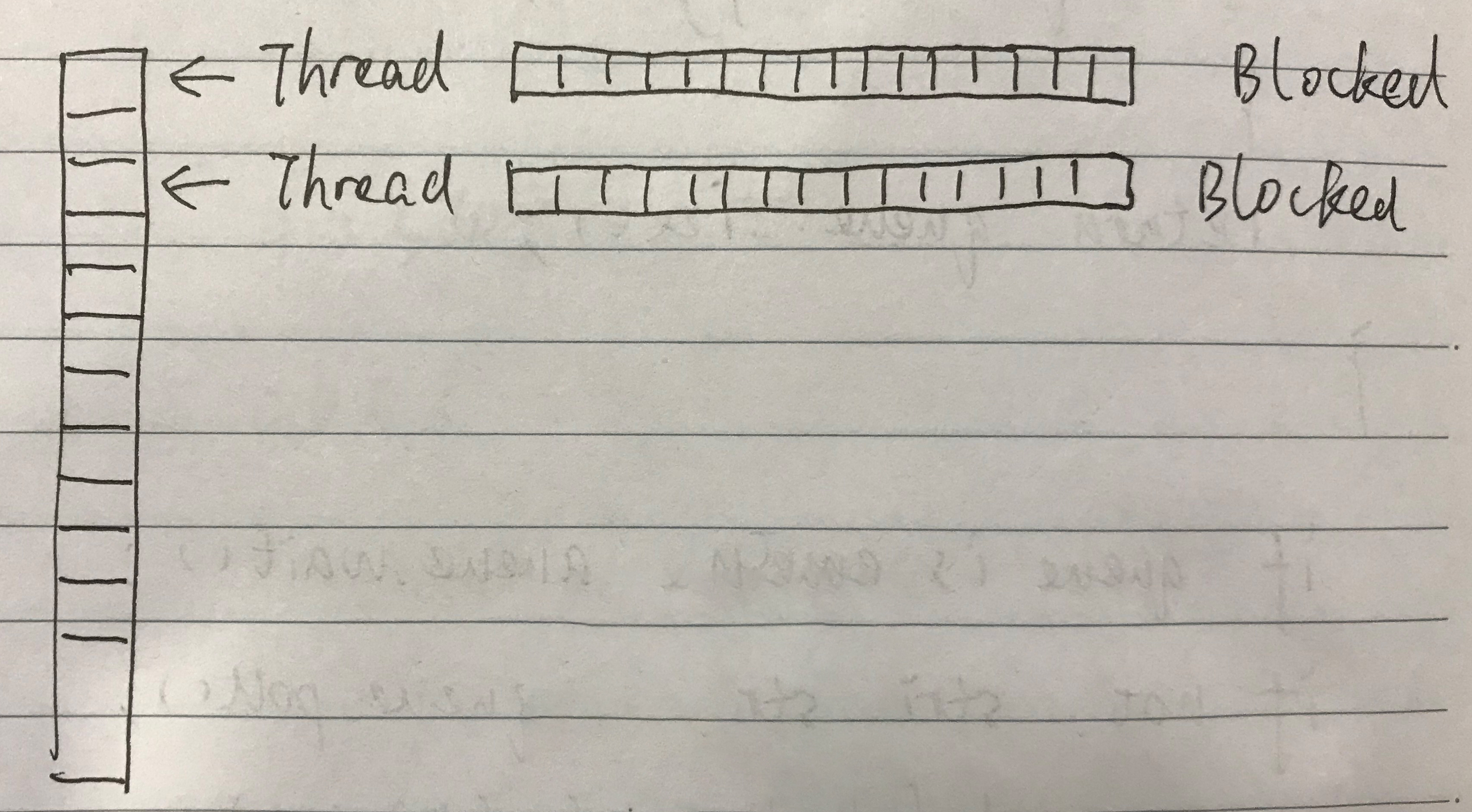
当我们将一个执行任务(一个参数)交给线程池以后,线程池会安排一个线程接收参数,这个线程会进入运行状态。线程执行完以后,线程又会因为参数队列为空而进入阻塞状态。某线程的执行状态如下图所示,执行完的阻塞态,如上图所示。
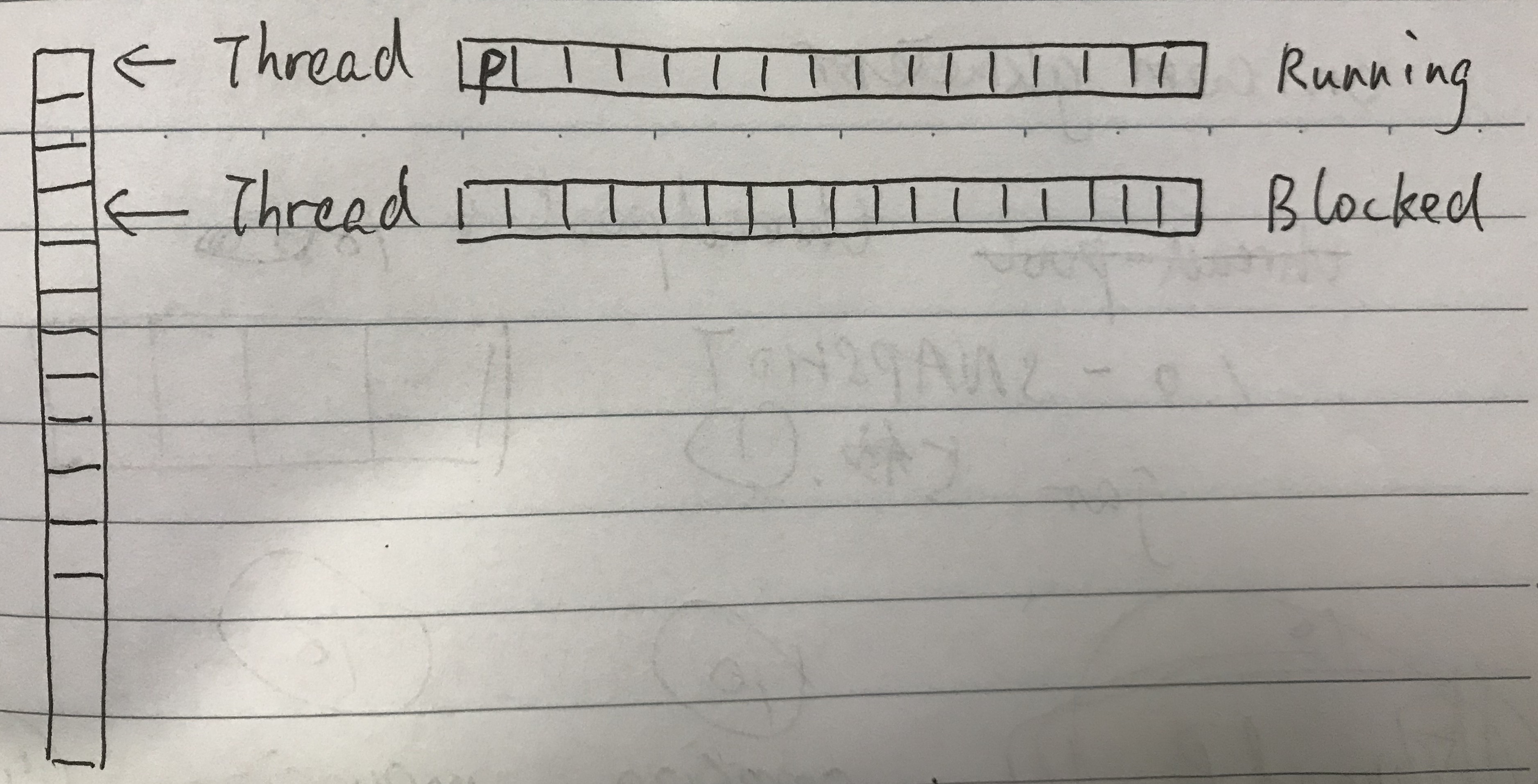
假设线程池中有3个线程,我们连续扔了3个参数给线程池,线程池会轮询获取线程,将参数塞给他们,然后这些线程会进入运行状态。运行完成后回归阻塞状态。如下图所示:
如下图所示,假设线程池中只有3个线程,我们连续发8个参数给线程池,那么池会轮流分配参数。线程在收到参数后就会执行。“消耗”掉一个参数后,会继续消耗下一个参数,直到参数列表为空为止。
二、为什么使用 LinkedBlockingQueue
1. BlockingQueue
我们必须先来说说为什么使用阻塞队列 BlockingQueue。BlockingQueue 队列为空时,尝试获取队头元素的操作会阻塞,一直等到队列中有元素时再返回。这个阻塞的特性,正是我们需要的,我们可以让线程一直等待元素插入,一旦插入立即执行。BlockingQueue 也支持在添加元素时,如果队列已满,那么等到队列可以放入新元素时再放入。如此一来,我们交给线程池的任务就不会丢失,哪怕超过了队列的容量。
所以我们定下方案,采用阻塞队列来作为数据结构,然后我们来调研阻塞队列常用的5种实现,
看看选择哪种实现来完成线程池。
2. ArrayBlockingQueue
ArrayBlockingQueue 是一个用数组实现的有界阻塞队列,其内部按先进先出的原则对元素进行排序,其中put方法和take方法为添加和删除的阻塞方法。可以说 ArrayBlockingQueue 是 阻塞队列的最直观的实现。
3. DelayQueue
DelayQueue是一个无界阻塞队列,延迟队列提供了在指定时间才能获取队列元素的功能,队列头元素是最接近过期的元素。没有过期元素的话,使用poll()方法会返回null值,超时判定是通过getDelay(TimeUnit.NANOSECONDS)方法的返回值小于等于0来判断。
DelayQueue阻塞队列在我们系统开发中也常常会用到,例如缓存系统的设计。缓存中的对象,超过了空闲时间,需要从缓存中移出;例如任务调度系统,需要准确的把握任务的执行时间。我们可能需要通过线程处理很多时间上要求很严格的数据,如果使用普通的线程,我们就需要遍历所有的对象,一个个检查看数据是否过期。首先这样在执行上的效率不会太高,其次就是这种设计的风格也大大的影响了数据的精度。一个需要12:00点执行的任务可能12:01 才执行,这样对数据要求很高的系统有更大的弊端。使用 DelayQueue 可以做到精准触发。
由上可知,延迟队列不是我们需要的阻塞队列实现。
4. LinkedBlockingQueue
LinkedBlockingQueue是一个由链表实现的有界队列阻塞队列,但大小默认值为Integer.MAX_VALUE,也可以在初始化的时候指定 capacity。和 ArrayBlockingQueue 一样,其中put方法和take方法为添加和删除的阻塞方法。
5. PriorityBlockingQueue
优先级阻塞队列通过使用堆这种数据结构实现将队列中的元素按照某种排序规则进行排序,从而改变先进先出的队列顺序,提供开发者改变队列中元素的顺序的能力。队列中的元素必须是可比较的,即实现Comparable接口,或者在构建函数时提供可对队列元素进行比较的Comparator对象。不可以放null,会报空指针异常,也不可放置无法比较的元素;add方法添加元素时,是自下而上的调整堆,取出元素时,是自上而下的调整堆顺序。
我们放入参数队列中的参数都是平级的,不涉及优先级,因此我们不考虑优先级阻塞队列。
6. SynchronousQueue
同步队列实际上不是一个真正的队列,因为它不会为队列中元素维护存储空间。与其他队列不同的是,它维护一组线程,这些线程在等待着把元素加入或移出队列。同步队列是轻量级的,不具有任何内部容量,我们可以用来在线程间安全的交换单一元素。
因为同步队列没有存储功能,因此put和take会一直阻塞,直到有另一个线程已经准备好参与到交付过程中。仅当有足够多的消费者,并且总是有一个消费者准备好获取交付的工作时,才适合使用同步队列。
应用场景,我们来看一下Java并发包里的 newCachedThreadPool 方法:
1 package java.util.concurrent; 2 3 /** 4 * 带有缓存的线程池 5 */ 6 public static ExecutorService newCachedThreadPool() { 7 return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 8 60L, TimeUnit.SECONDS, 9 new SynchronousQueue<Runnable>()); 10 }
Executors.newCachedThreadPool() 方法返回的 ThreadPoolExecutor 实例,其内部的阻塞队列使用的就是同步队列。由于ThreadPoolExecutor内部实现任务提交的时候调用的是工作队列的非阻塞式入队列方法(offer方法),因此,在使用同步队列作为工作队列的前提下,客户端代码向线程池提交任务时,而线程池中又没有空闲的线程能够从同步队列队列实例中取一个任务,那么相应的offer方法调用就会失败(即任务没有被存入工作队列)。此时,ThreadPoolExecutor会新建一个新的工作者线程用于对这个入队列失败的任务进行处理(假设此时线程池的大小还未达到其最大线程池大小)。
如上所述,同步队列没有内部容量来存放参数,因此我们不选择同步队列。
7. 阻塞队列选择
研究了阻塞队列的5中实现以后,候选者就在 ArrayBlockingQueue 和 LinkedBlockingQueue 两者中。其实要实现本文的简易版线程池,使用数组阻塞队列和链接阻塞队列都可以,如果你要考虑一些极端情况下的性能问题,那么透彻的研究两者的使用场景就非常有必要。数组阻塞队列和链接阻塞队列的成员变量和方法都很相似,相同点我们就先不说了。下面我们来看看两者的不同点:
- 队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE)。对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
- 数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
- 由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
- 实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReentrantLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
三、LinkedBlockingQueue 底层方法
我们来调研一下 LinkedBlockingQueue,看看哪些变量和方法可以使用。
先来看一下 LinkedBlockingQueue 的数据结构,有一个直观的了解:
说明:
- LinkedBlockingQueue继承于AbstractQueue,它本质上是一个FIFO(先进先出)的队列。
- LinkedBlockingQueue实现了BlockingQueue接口,它支持多线程并发。当多线程竞争同一个资源时,某线程获取到该资源之后,其它线程需要阻塞等待。
- LinkedBlockingQueue是通过单链表实现的。
-
- head是链表的表头。取出数据时,都是从表头head处获取。
- last是链表的表尾。新增数据时,都是从表尾last处插入。
- count是链表的实际大小,即当前链表中包含的节点个数。
- capacity是列表的容量,它是在创建链表时指定的。
- putLock是插入锁,takeLock是取出锁;notEmpty是“非空条件”,notFull是“未满条件”。通过它们对链表进行并发控制。
我们来看一下 LinkedBlockingQueue 常用的变量:
1 // 容量 2 private final int capacity; 3 4 // 当前数量 5 private final AtomicInteger count = new AtomicInteger(0); 6 7 // 链表的表头 8 transient Node<E> head; 9 10 // 链表的表尾 11 private transient Node<E> last; 12 13 // 用于控制删除元素的【取出锁】和锁对应的【非空条件】 14 private final ReentrantLock takeLock = new ReentrantLock(); 15 private final Condition notEmpty = takeLock.newCondition(); 16 17 // 用于控制添加元素的【插入锁】和锁对应的【非满条件】 18 private final ReentrantLock putLock = new ReentrantLock(); 19 private final Condition notFull = putLock.newCondition();
这里的两把锁,takeLock 和 putLock,和两个条件,notEmpty 和 notFull 是我们考察的重点。
LinkedBlockingQueue在实现“多线程对竞争资源的互斥访问”时,对于“插入”和“取出(删除)”操作分别使用了不同的锁
- 对于插入操作,通过 putLock(插入锁)进行同步
- 对于取出操作,通过 takeLock(取出锁)进行同步
此外,插入锁putLock和notFull(非满条件)相关联,取出锁takeLock和notEmpty
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









