






 本文讲述了作者在爬虫比赛中利用Python和selenium抓取lagou.com平台大数据工程师职位信息,包括工资、经验、地区、学历和行业,通过FineBI分析影响薪资因素和行业需求,展示了数据获取、处理和初步洞察的过程。
本文讲述了作者在爬虫比赛中利用Python和selenium抓取lagou.com平台大数据工程师职位信息,包括工资、经验、地区、学历和行业,通过FineBI分析影响薪资因素和行业需求,展示了数据获取、处理和初步洞察的过程。
最近小编参加了学校的爬虫比赛,由于我是比赛开始后一天我才知道有这个比赛,这个比赛不止需要做爬数据,还需要做数据分析,因此时间比较紧。
本次比赛的主题是围绕着大数据工程师进行数据的爬取和分析。
目标网站
aHR0cHMlM2ElMmYlMmZ3d3cubGFnb3UuY29tL2pvYnMvbGlzdF8lRTUlQTQlQTclRTYlOTUlQjAlRTYlOEQlQUU/bGFiZWxXb3Jkcz0mZnJvbVNlYXJjaD10cnVlJnN1Z2lucHV0PQ==
目录:
一、数据获取
- 1、环境
- 2、分析网站
- 3、实现爬取
二、数据分析
- 1、分析影响工资的因素
- 2、行业需求分析
一、数据获取
1、环境
Python3.7、requests、selenium
2、分析网站
先打开开发者工具,再在搜索栏中输入大数据
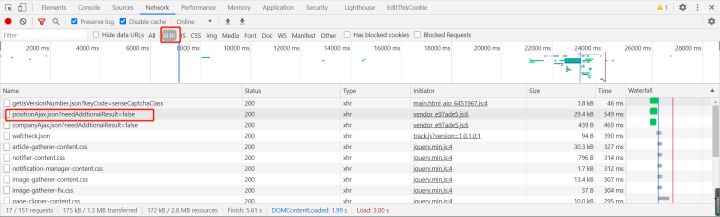
筛选XHR请求很容易就可以发现目标数据所在的请求如图3
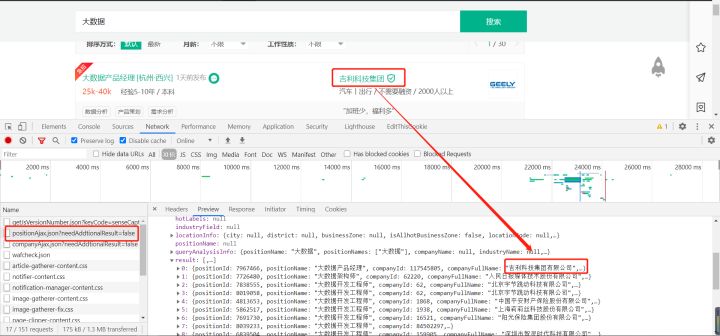
找到了请求,第二步就是分析请求是否有加密,我的习惯是直接看最下面的请求参数
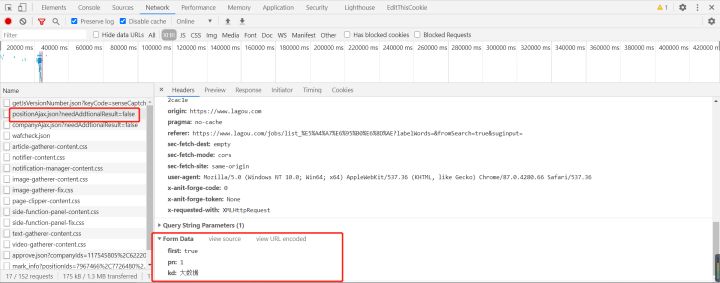
很明显没有加密参数,直接请求这个数据的接口,得到如图5,没有得到数据,肯定有什么地方是加密了的,估计就是cookie加密了

看一下cookie,如图6
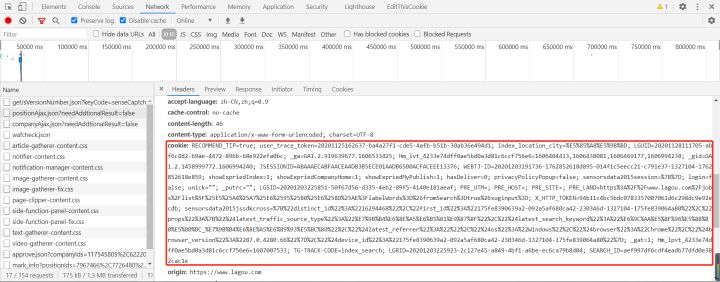
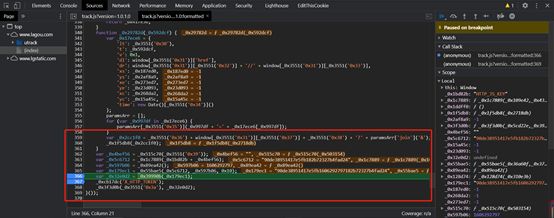
我看了一下背后的逻辑,是经过混淆的如图7
由于比赛时间比较紧,我就直接用selenium获取cookie,拿到数据进行数据分析再说。
3、实现爬取
用selenium爬取就基本没有难点,用selenium运行js代码得到cookie即可
def get_cookie(url):
browser.get(url)
js = 'var c = document.cookie;return c' # js语句
return browser.execute_script(js) # 执行js
这里是post请求,需要改变参数已达到请求不同页码的数据
def get_json(content):
a = content.get('content').get('positionResult').get('result')
city, jod_year, experience, XL, ave_money, business = [], [], [], [], [], []
for i in a:
city.append(i.get('city'))
jod_year.append(i.get('workYear'))
XL.append(i.get('education'))
ave_money.append((i.get('salary')))
business.append(i.get('industryField'))
for i in range(len(city)):
data = {'ave_money': ave_money[i], 'HY': business[i], 'job_year': jod_year[i], 'XL': XL[i], 'zone': city[i]}
print(data)
def main():
cookie = get_cookie(url=goal_url)
headers['cookie'] = cookie
for i in range(1):
data = {
'first': 'true',
'pn': f'{i+1}',
'kd': 'python'
}
# allow_redirects=True, verify=False
response = requests.post(url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false',
headers=headers, data=data)
# 休眠随机时间
sleep_time = random.uniform(0, 5)
time.sleep(sleep_time)
get_json(response.json())

我需要的数据:工资、工资经验、地区、学历、行业,构成字典直接存入MongoDB中
def get_json(content):
a = content.get('content').get('positionResult').get('result')
city, jod_year, experience, XL, ave_money, business = [], [], [], [], [], []
for i in a:
city.append(i.get('city'))
jod_year.append(i.get('workYear'))
XL.append(i.get('education'))
ave_money.append((i.get('salary')))
business.append(i.get('industryField'))
for i in range(len(city)):
data = {'ave_money': ave_money[i], 'HY': business[i], 'job_year': jod_year[i], 'XL': XL[i], 'zone': city[i]}
print(data)
在这挖个坑,之后我会更新如何逆向出cookie的生成逻辑。
一、数据分析
这里使用FineBI进行分析,本篇不会涉及finebi的基础操作。
1、分析影响工资的因素
2、行业需求分析
1、分析影响工资的因素
我将从地区、行业、工作经验三个维度进行分析。
- 薪资-地区分析
将城市拆分为经纬度即可制作地理图。
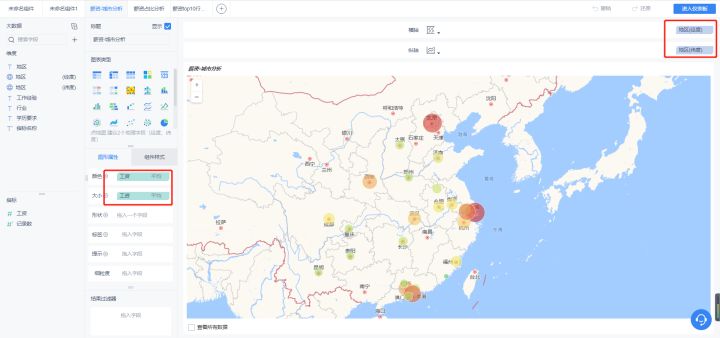
大数据是新兴产业,因此总体还是以京津翼、长三角、珠三角为主。 这图的亮点是四川、
湖北等中部省份的需求量也不小,这也能侧面的印证近些年中部地区的GDP增速较高。
- 行业-薪资分析
这里采用条形图进行展示,数据截取了top10。
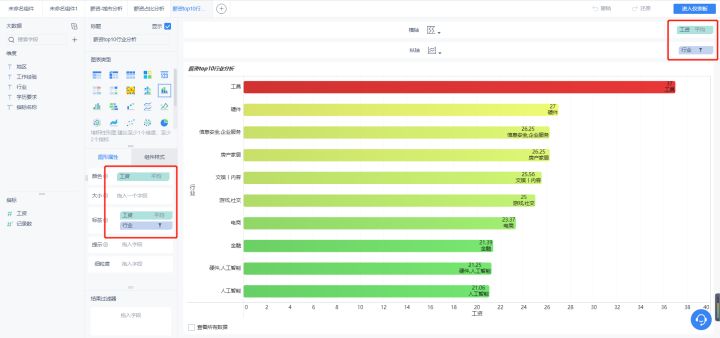
排名前三位的行业是工具、硬件、信息安全,企业服务。我对工具排第一位还挺好奇
的,于是乎查看数据是什么情况,如下图

数据有点少就五条,如果是数据量大的话就可以尽量的减小误差。
- 工作经验-薪资分析
这里顺带分析一下各个经验要求下的岗位需求数量。

可以看出经验对大数据岗位的工资影响还是很大的,工作经验低于3年的工资都普遍低于20k。
2、行业需求量分析
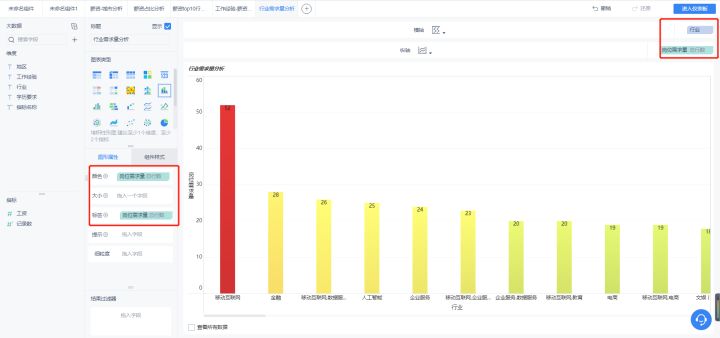
可以看到移动互联网行业大幅高于其他行业,其次是金融、数据服务,大数据岗位是近几年才新起的岗位,在能产生大量数据的行业需求量最大的。
可视化总览:
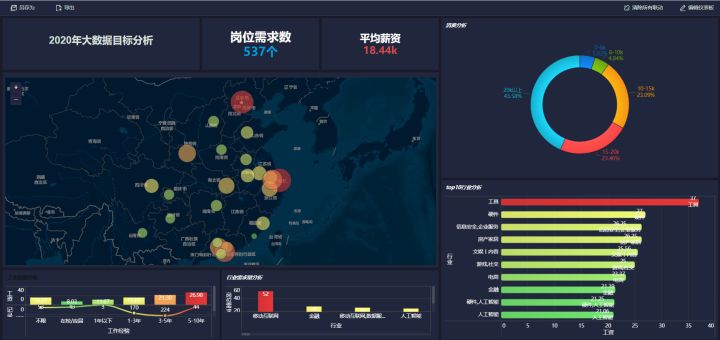
总结:从大数据的岗位需求量分布上可以明显看出,行业的涉及面越来越广;从平均薪资来看,高薪普遍集中在北、上、广、深这样的一线城市;但是二三线城市专门做大数据业务的公司呈上升趋势,薪资在本地行业中也是普遍偏高的。大数据就业会在未来呈现良好的上升趋势,但业界需要专业与肯于深耕的人才。

















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









