







Proposal-based Multiple Instance Learning for Weakly-supervised Temporal Action Localization 论文阅读
文章信息:

源码:https://github.com/RenHuan1999/CVPR2023_P-MIL
发表于:CVPR 2023
Abstract
弱监督时序动作定位旨在在训练期间仅使用视频级别的类别标签来定位和识别未修剪的视频中的动作。在没有实例级别注释的情况下,大多数现有方法都遵循基于片段的多实例学习(S-MIL)框架,其中片段的预测受视频标签的监督。然而,在训练期间获取片段级别得分的目标与在测试期间获取提议级别得分的目标不一致,导致结果不佳。为了解决这个问题,我们提出了一种新颖的基于提议的多实例学习(P-MIL)框架,该框架直接对候选提议进行分类,包括以下三个关键设计:1)周围对比特征提取模块,通过考虑周围对比信息抑制具有区分性的短提议;2)提议完整性评估模块,通过完整性伪标签的指导抑制低质量的提议;和3)实例级别的排名一致性损失,通过利用RGB和FLOW模态的互补性实现稳健的检测。对包括THUMOS14和ActivityNet在内的两个具有挑战性的基准进行的大量实验结果表明了我们方法的优越性能。
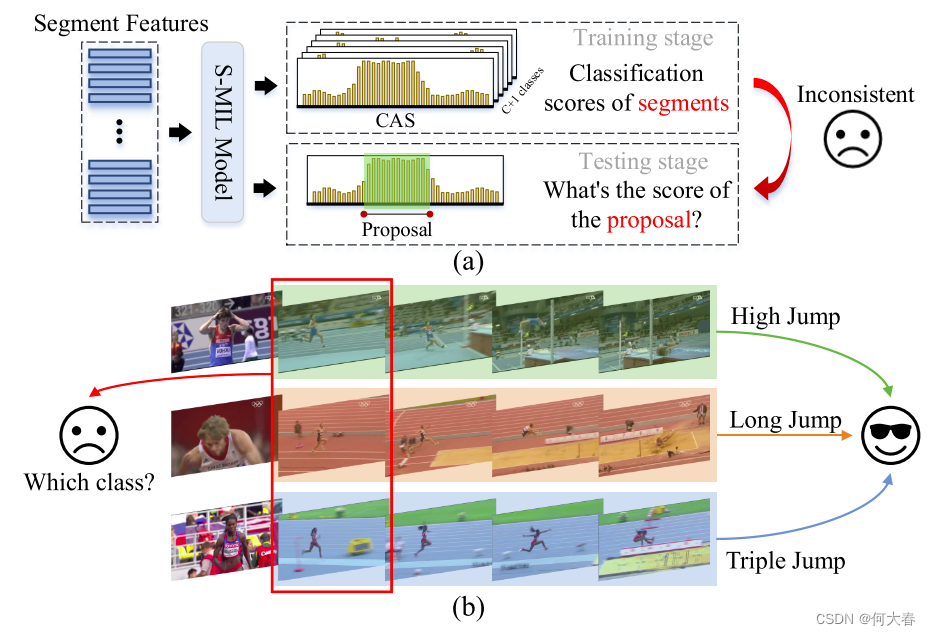
图 1. 基于段的多实例学习框架的缺陷。 (a) 训练和测试阶段的目标不一致。 (b) 观察红框中的单个运行段,很难确定它属于哪个类别。
1. Introduction
时序动作定位(TAL)是视频理解中的一项重要任务之一,旨在在未修剪的视频中同时发现动作实例并识别它们的类别。TAL 最近受到研究界的日益关注,因为它具有广泛的应用潜力,例如智能监视、视频摘要、精彩片段检测和视觉问答等领域。大多数现有方法在完全监督的环境下处理这项任务,这需要实例级别的注释。尽管这些方法取得了成功,但如此大量的实例级别注释要求限制了它们在实际场景中的应用。为了克服这一限制,弱监督时序动作定位(WTAL)受到了广泛的研究,因为它只需要视频级别的标签,这要容易收集得多。
大多数现有的弱监督时序动作定位(WTAL)方法遵循基于片段的多实例学习(S-MIL)框架,其中片段的预测受视频标签的监督。具体而言,使用类别无关的注意力分支来计算注意力序列,该序列指示每个片段的前景概率。同时,使用分类分支来计算类别激活序列(CAS),该序列指示每个片段的类别概率。在训练阶段,通过将 CAS 与注意力序列聚合,可以得到视频级别的分类分数,然后由视频级别的类别标签对其进行监督。在测试阶段,通过对注意力序列进行阈值处理来生成候选提议,然后将与每个提议对应的片段级别的 CAS 进行聚合,以对每个提议进行评分。
尽管这些方法取得了相当大的进展,但 S-MIL 框架存在两个缺点。首先,训练和测试阶段的目标不一致。如图 1(a)所示,测试阶段的目标是对动作提议作为整体进行评分,但分类器在训练阶段是针对片段进行评分的。这种评分方法的不一致性可能会导致次优的结果,就像其他弱监督任务中所示的那样。其次,在许多情况下,单独对每个片段进行分类是困难的。如图 1(b)所示,观看单个运动片段时,很难确定它是属于跳高、跳远还是三级跳。只有观看整个动作实例并利用上下文信息,我们才能确定它属于哪个类别。
受以上讨论的启发,我们提出了一种新颖的基于提议的多实例学习(P-MIL)框架,该框架采用了两阶段的训练流程。在第一阶段,训练一个 S-MIL 模型并通过对注意力序列进行阈值处理来生成候选提议。在第二阶段,对候选提议进行分类,并将其聚合成视频级别的分类分数,这些分数由视频级别的类别标签进行监督。由于候选提议在训练和测试阶段都直接进行分类,所以所提出的方法可以有效地处理 S-MIL 框架的缺点。然而,在 P-MIL 框架中有三个需要考虑的问题。首先,模型倾向于关注具有区分性的短提议。由于训练阶段主要由视频级别的分类进行引导,分类器倾向于关注最具区分性的提议,以最小化分类损失。为了解决这个问题,我们提出了一个周围对比特征提取模块。具体来说,我们扩展了候选提议的边界,然后计算了提议的外部-内部对比特征。通过考虑周围对比信息,可以有效地抑制那些具有区分性的短提议。第二,由 S-MIL 方法生成的候选提议可能过于完整,包括不相关的背景片段。在这方面,我们提出了一个提议完整性评估模块。具体来说,我们将高置信度的提议视为伪实例,然后通过计算与这些伪实例的交集比(IoU)来获得每个提议的完整性伪标签。在完整性伪标签的指导下,可以抑制低质量提议的激活。第三,由于测试阶段的非极大值抑制(NMS)过程,属于同一动作实例的提议的相对得分对检测结果有重要影响。为了学习稳健的相对得分,我们设计了一个实例级别的排名一致性损失,利用 RGB 和 FLOW 模态的互补性。那些与给定候选提议重叠的提议被视为一个簇。通过约束 RGB 和 FLOW 模态之间的簇内标准化相对得分保持一致,我们可以通过在 NMS 过程中丢弃相对得分低的提议来实现可靠的检测。
综上所述,本文的主要贡献如下:
(1)我们提出了一种新颖的基于提议的多实例学习(P-MIL)框架,用于弱监督的时间动作定位,在训练和测试阶段直接对候选提议进行分类,从而解决了 S-MIL 框架的缺点。
(2)我们提出了三个关键设计(周围对比特征提取模块、提议完整性评估模块、实例级别排名一致性损失),可以应对 P-MIL 框架不同阶段的挑战。
(3)在 THUMOS14 和 ActivityNet 数据集上的大量实验结果表明,所提出的框架相对于最先进的方法具有卓越的性能。
2. Related Work
在本节中,我们简要概述与完全监督和弱监督时间动作定位相关的方法。
Fully-supervised Temporal Action Localization.时间动作定位(TAL)旨在同时在未剪辑的视频中定位和识别动作实例。类似于目标检测[5, 11, 27, 39]的发展,现有的完全监督方法可以分为两类:两阶段方法[7, 42, 50, 59, 63, 65]和一阶段方法[3, 8, 27, 30, 47, 53, 62]。两阶段方法首先生成候选提议,然后将其馈送到动作分类器中,通过改善提议的质量[7,42,59,65]或分类器的鲁棒性[50,63]来实现。相反,一阶段方法可以同时生成候选提议并对其进行分类,最近通过引入Transformer架构[8, 47, 62]已经取得了显著的性能。尽管取得了成功,但对大量和昂贵的实例级别注释的要求限制了它们在实际场景中的应用。
Weakly-supervised Temporal Action Localization.为解决上述问题,研究人员广泛研究了弱监督时间动作定位(WTAL)[13, 26, 31, 36, 45, 54, 57, 60],该方法仅需要视频级别的类别标签。UntrimmedNet [45] 是第一个引入多实例学习(MIL)框架 [33] 来处理WTAL任务的方法,通过对片段进行分类并使用选择模块生成动作提议。然而,由于分类和定位任务之间的差异,模型倾向于关注最具区分性的片段。Step-by-step [64] 允许模型在训练过程中逐渐擦除最具区分性的片段,从而学习更完整的定位。WTALC [38] 通过将相同类别的特征拉近,同时将不同类别的特征推远,学习紧凑的类内特征表示。通过引入用于前景-背景分离的类不可知注意力分支,基于注意力的方法 [15,21,26,31,36] 成为主流,因为它们具有出色的性能和模型架构的灵活性。STPN [36] 在注意力序列上引入了稀疏性损失,以捕获关键的前景片段。CMCS [26] 采用多分支架构来发现具有良好设计的多样性损失的独特动作部分。BaS-Net [21] 和WSAL-BM [37] 引入了一个额外的背景类别来明确建模背景。CO2-Net [15] 设计了一个跨模态注意力机制,通过过滤掉任务无关的冗余信息来增强特征。最近,一些研究 [17, 32, 55, 60] 尝试生成伪标签来指导模型训练。在 [32] 中,类不可知注意力序列和类激活序列在期望最大化框架中为彼此提供伪标签。TSCN [60] 融合了RGB和FLOW模态的注意力序列,生成片段级伪标签,而UGCT [55] 利用它们的互补性为彼此生成伪标签。与之不同,ASMLoc [13] 不仅利用伪标签监督模型训练,还利用动作提议增强片段特征,用于片段级别的时间建模。尽管之前的方法取得了可观的进展,但它们几乎都遵循基于片段的MIL框架来实现时间动作定位,在训练和测试阶段之间的目标不一致。为了解决这个问题,我们提出了一种新颖的基于提议的MIL框架,以直接在训练和测试阶段对候选提议进行分类。
3. Our Method
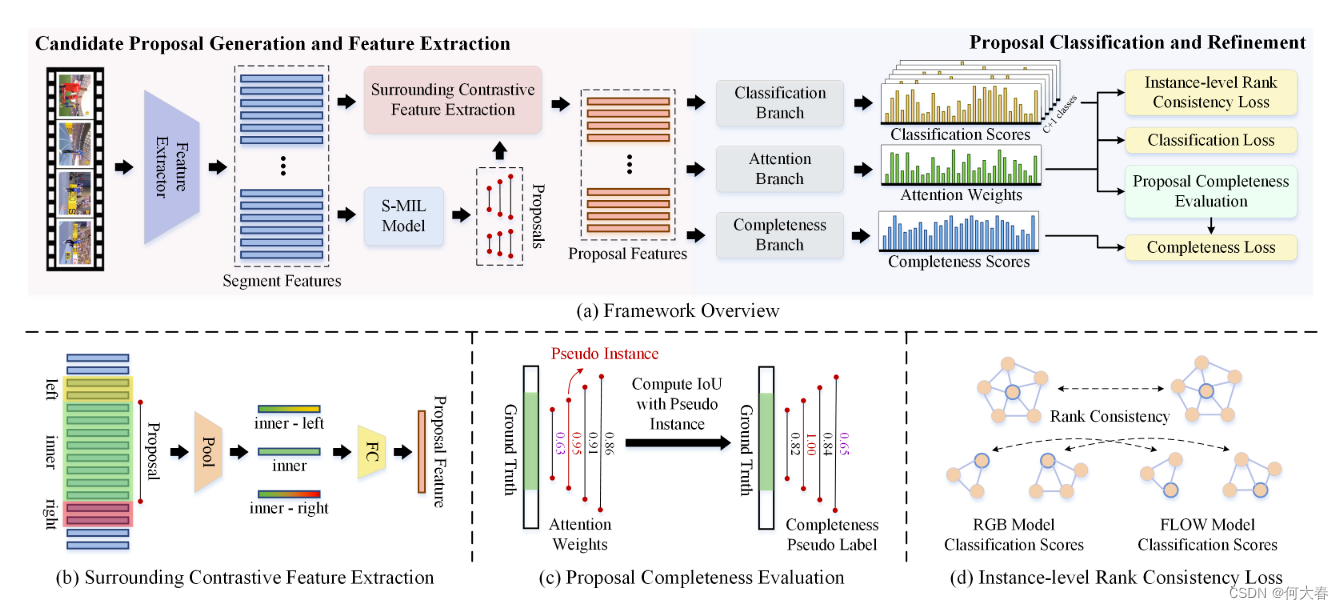
图 2. \color{red}{2.} 2. (a) 展示了提出的基于提议的多实例学习框架的概述,包括候选提议生成、提议特征提取、提议分类和细化等步骤。 (b) 环绕对比特征提取(SCFE)模块扩展了候选提议的边界,然后计算了候选提议的外-内对比特征。 (c ) 提议完整性评估(PCE)模块通过计算与所选伪实例的IoU来生成完整性伪标签。 (d) 实例级别排名一致性(IRC)损失约束RGB和FLOW模态之间的归一化相对分类分数在簇内保持一致。
在本节中,我们详细阐述了针对弱监督时间动作定位(WTAL)提出的基于提议的多实例学习框架(P-MIL),如图 2. \color{red}{2.} 2.所示。给定一个视频V,WTAL的目标是预测一组动作实例 { ( c i , s i , e i , q i ) } i = 1 M p \left\{(c_i,s_i,e_i,q_i)\right\}_{i=1}^{M_p} {(ci,si,ei,qi)}i=1Mp,其中 s i s_i si和 e i e_i ei表示第 i i i个动作的开始时间和结束时间, c i c_i ci和 q i q_i qi分别表示动作类别和置信度分数。在训练期间,每个视频V都有其地面真实的视频级别类别标签 y ∈ R C \boldsymbol{y}\in\mathbb{R}^C y∈RC,其中 C C C表示动作类别的数量。如果第 j j j个动作在视频中出现,则 y ( j ) = 1 \boldsymbol{y}(j)=1 y(j)=1,否则 y ( j ) = 0 \boldsymbol{y}(j)=0 y(j)=0。所提出的P-MIL框架包括三个步骤,包括候选提议生成(第3.1节)、提议特征提取和分类(第3.2节)、提议细化(第3.3节)。具体细节如下。
3.1. Candidate Proposal Generation
为了生成候选提议,我们训练了一个 S-MIL 模型。首先,我们将每个未剪辑视频分割成不重叠的 16 帧段,然后应用预训练的特征提取器(例如 I3D)来提取 RGB 和 FLOW 两种模态的段特征 X S ∈ R T × D \mathbf{X}_{S}\in\mathbb{R}^{T\times D} XS∈RT×D,其中 T T T 表示视频中的段数, D D D 是特征维度。遵循典型的双分支架构,我们利用一个类别无关的注意力分支来计算注意力序列 A ∈ R T × 1 \mathbf{A}\in\mathbb{R}^{T\times1} A∈RT×1,并且使用一个分类分支来预测基础的类激活序列(CAS) S b a s e ∈ R T × ( C + 1 ) \mathbf{S}_{base}\in\mathbb{R}^{T\times(C+1)} Sbase∈RT×(C+1),其中第 ( C + 1 ) (C+1) (C+1) 类表示背景。通过在时间维度上将 S b a s e \mathbf{S}_{base} Sbase 与 A \mathbf{A} A 相乘,我们可以获得抑制背景的 CAS S s u p p ∈ R T × ( C + 1 ) \mathbf{S}_{supp}\in\mathbb{R}^{T\times(C+1)} Ssupp∈RT×(C+1)。之后,通过对 S b a s e \mathbf{S}_{base} Sbase 和 S s u p p \mathbf{S}_{supp} Ssupp 应用时间上的前 k 聚合策略,分别得到了预测的视频级分类分数 y ^ b a s e , y ^ s u p p ∈ R ^ C + 1 \hat{\boldsymbol{y}}_{base}, \hat{\boldsymbol{y}}_{supp} \in \hat{\mathbb{R}}^{C+1} y^base,y^supp∈R^C+1,然后进行 softmax 操作。
在视频级别类别标签
y
y
y 的指导下,分类损失被表述为
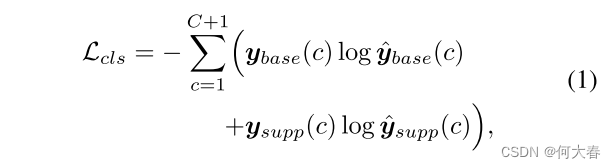
其中
y
b
a
s
e
=
[
y
,
1
]
∈
R
C
+
1
y_{base}=[\boldsymbol{y},1]\in\mathbb{R}^{C+1}
ybase=[y,1]∈RC+1 和
y
s
u
p
p
=
[
y
,
0
]
∈
R
C
+
1
\boldsymbol{y}_{supp}=[\boldsymbol{y},0]\in\mathbb{R}^{C+1}
ysupp=[y,0]∈RC+1,基于这样的假设:背景在所有视频中都存在,但被注意力序列
A
A
A 过滤掉了。此外,还在注意力序列
A
A
A 上采用了稀疏性损失[36]
L
n
o
r
m
=
1
T
∑
t
=
1
T
∣
A
(
t
)
∣
\mathcal{L}_{norm}=\frac1T\sum_{t=1}^T|\mathbf{A}(t)|
Lnorm=T1∑t=1T∣A(t)∣,以便专注于关键的前景段。总体而言,训练目标如下:
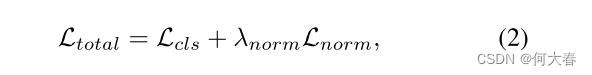
其中, λ n o r m λ_{norm} λnorm 是一个平衡因子。
使用训练好的 S-MIL 模型,在注意力序列 A 上应用多个阈值
θ
a
c
t
\theta_{act}
θact 生成候选动作提议
P
a
c
t
=
{
(
s
i
,
e
i
)
}
i
=
1
M
1
P_{act}=\left\{(s_{i},e_{i})\right\}_{i=1}^{M_{1}}
Pact={(si,ei)}i=1M1。为了让我们的 P-MIL 模型在训练阶段学习更好的前景背景分离,我们还对注意力序列 A 应用额外的阈值
θ
b
k
g
\theta_{bkg}
θbkg 生成背景提议
P
b
k
g
=
{
(
s
i
,
e
i
)
}
i
=
1
M
2
P_{bkg}=\left\{(s_{i},e_{i})\right\}_{i=1}^{M_{2}}
Pbkg={(si,ei)}i=1M2,其中注意力序列 A 低于
θ
b
k
g
\theta_{bkg}
θbkg。因此,训练的最终候选提议被定义为:
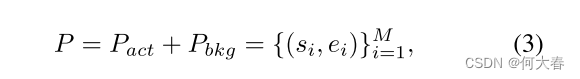
其中
M
=
M
1
+
M
2
M=M_1+M_2
M=M1+M2 表示候选提议的总数。请注意,我们在推断阶段只使用动作提议
P
a
c
t
P_{act}
Pact。
3.2. Proposal Feature Extraction and Classificatio
在给定候选提议 P P P 的情况下,先前的 S-MIL 方法使用 CAS 来计算每个提议的置信度分数(例如,Outer-Inner Score [41])。然而,这些间接的评分方法可能导致次优的结果。为解决这个问题,我们提出直接对候选提议进行分类,并将它们聚合成视频级分类分数,这些分数由视频级别的类别标签进行监督。
Surrounding Contrastive Feature Extraction.对于给定的候选提议
P
P
P,我们首先提取相应的提议特征
X
P
∈
R
M
×
D
.
\mathbf{X}_P\in\mathbb{R}^{M\times D}.
XP∈RM×D. 由于训练阶段主要由视频级分类引导,分类器倾向于专注于具有较强区分性的短提议,以最小化分类损失。为了解决这个问题,我们提出了一个周围对比特征提取 (SCFE) 模块。具体地,给定一个候选提议
P
i
P_{i}
Pi =
(
s
i
,
e
i
)
( s_{i}, e_{i})
(si,ei),我们首先在其长度的左右两侧分别扩展
α
\alpha
α,形成三个区域:左、内部和右。对于每个区域,我们然后使用 RoIAlign [14] 后跟着最大池化对段特征
X
S
\mathbf{X}_S
XS 进行提取,得到一个关联的
D
D
D 维特征向量,分别表示为
X
i
l
,
X
i
n
\mathbf{X}_{i}^{l},\mathbf{X}_{i}^{n}
Xil,Xin 和
X
i
r
\mathbf{X}_{i}^{r}
Xir。获得提议特征的一种直观方法是直接连接这三个特征向量并将它们馈送到全连接层。然而,受到 AutoLoc [41] 的启发,我们采取了一种更有效的方法,即计算提议的外部内部对比特征,然后接上一个全连接层,表达为:

这里的 “Cat” 表示连接操作。通过考虑周围的对比信息,可以有效地抑制那些具有较强区分能力的短提议。
Classification Head.类似于 S-MIL 框架的流程,给定提议特征 X P \mathbf{X}_P XP,然后使用一个类别无关的注意力分支来预测注意力权重 A ∈ R M × 1 \mathbf{A}\in\mathbb{R}^{M\times1} A∈RM×1,它表示每个提议的前景概率。同时,使用一个分类分支来预测提议的基础分类得分 S b a s e ∈ R M × ( C + 1 ) \mathbf{S}_{base}\in\mathbb{R}^{M\times(C+1)} Sbase∈RM×(C+1)。通过将 S b a s e \mathbf{S}_{base} Sbase 与 A \mathbf{A} A 相乘,我们得到了抑制背景的分类得分 S s u p p ∈ R M × ( C + 1 ) \mathbf{S}_{supp}\in\mathbb{R}^{M\times(C+1)} Ssupp∈RM×(C+1)。最后,通过对 S b a s e \mathbf{S}_{base} Sbase 和 S s u p p \mathbf{S}_{supp} Ssupp 分别应用 top- k k k 池化和 softmax 操作,得到了预测的视频级分类得分 y ^ b a s e , y ^ s u p p ∈ R ^ C + 1 \hat{\boldsymbol{y}}_{base},\hat{\boldsymbol{y}}_{supp}\in\hat{\mathbb{R}}^{C+1} y^base,y^supp∈R^C+1,这些得分受视频级别的类别标签监督。
3.3. Proposal Refinement
Proposal Completeness Evaluation.
由 S-MIL 方法生成的候选提议可能过于完备,其中包括不相关的背景片段。
为此,我们提出了一个提案完整性评估(PCE)模块。给定候选提案,我们使用注意权重来选择高置信度提案作为伪实例,然后通过计算与这些伪实例的交并比(IoU)来获取每个提案的完整性伪标签。形式上,我们首先将阈值 γ ⋅ m a x ( A ) \gamma\cdot max(\mathbf{A}) γ⋅max(A)(在我们的情况下 γ \gamma γ 设置为 0.8)应用于提案的注意权重 A \mathbf{A} A,以选择一组高置信度提案 Q Q Q。然后,按照非最大抑制(NMS)过程,我们选择具有最高注意权重的提案作为伪实例,从 Q Q Q 中删除与其重叠的提案,并重复此过程,直到 Q Q Q 为空为止。之后,我们获得一组伪实例 G = { ( s i , e i ) } i = 1 N G=\{(s_{i},e_{i})\}_{i=1}^{N} G={(si,ei)}i=1N。通过计算候选提案 P P P 和伪实例 G G G 之间的 IoU,我们可以获得一个 M × N M\times N M×N 维的 IoU 矩阵。我们通过在 N N N 维上取最大值,为每个提案分配具有最大 IoU 的伪实例,然后我们获得了候选提案的完整性伪标签 q ∈ R M \boldsymbol q\in\mathbb{R}^M q∈RM。在 q q q 的指导下,引入了一个完整性分支,以与注意分支和分类分支并行预测完整性得分 q ^ ∈ R M \hat{\boldsymbol{q}}\in\mathbb{R}^M q^∈RM,这有助于抑制低质量提案的激活。
Instance-level Rank Consistency.由于测试阶段的NMS过程,属于同一动作实例的候选提案的相对得分对检测结果有重要影响。为了学习稳健的相对得分,我们设计了一个实例级别的排名一致性(IRC)损失,利用RGB和FLOW模态的互补性。具体来说,我们首先将阈值
m
e
a
n
(
A
)
mean(\mathbf{A})
mean(A) 应用于注意序列
A
\mathbf{A}
A,以消除低置信度的提案,剩下的提案记为
R
R
R。对于
R
R
R 中的每个提案
r
r
r,与其重叠的那些候选提案被视为一个聚类
Ω
r
\Omega_r
Ωr,其中
∣
Ω
r
∣
=
N
r
|\Omega_r|=N_r
∣Ωr∣=Nr。该聚类对应的分类分数
S
b
a
s
e
\mathbf{S}_{base}
Sbase 从RGB和FLOW模态中索引,分别表示为
p
r
,
c
R
G
B
p_{r,c}^{RGB}
pr,cRGB 和
p
r
,
c
F
L
O
W
p_{r,c}^{FLOW}
pr,cFLOW,其中
c
c
c 表示地面实况类别之一。然后,聚类内的归一化相对得分被表述为:
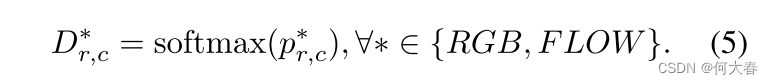
Kullback-Leibler(KL)散度用于约束RGB和FLOW模态之间的一致性,定义为:
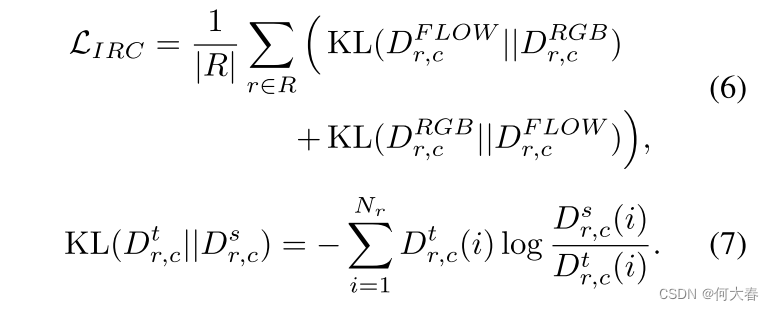
通过IRC损失,我们可以在NMS过程中丢弃具有较低相对分数的提议,从而实现可靠的检测。
3.4. Network Training and Inference
Network Training.在训练阶段,根据视频级别的类别标签 y,主要的分类损失被表述为:
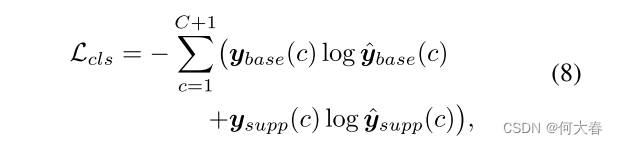
其中,
y
base
=
[
y
,
1
]
∈
R
C
+
1
\boldsymbol{y}_\text{base}=[\boldsymbol{y},1]\in\mathbb{R}^{C+1}
ybase=[y,1]∈RC+1 和
y
supp
=
[
y
,
0
]
∈
R
C
+
1
.
\boldsymbol{y}_\text{supp}=[\boldsymbol{y},0]\in\mathbb{R}^{C+1}.
ysupp=[y,0]∈RC+1. 另外,使用了 PCE 模块后,完整性损失被定义为完整性伪标签
q
q
q 和预测的完整性得分
q
^
\hat{q}
q^ 之间的均方误差(MSE):
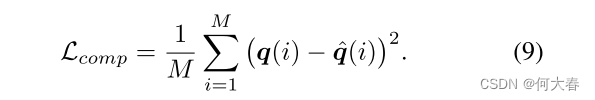
总的来说,我们模型的训练目标是
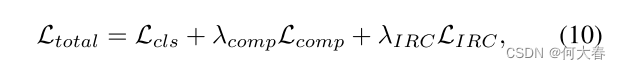
其中
λ
c
o
m
p
λ_{comp}
λcomp和
λ
I
R
C
λ_{IRC}
λIRC是平衡超参数。
Inference.在测试阶段,我们首先将阈值
θ
c
l
s
\theta_{cls}
θcls 应用于视频级分类分数
y
^
s
u
p
p
\hat{y}_{supp}
y^supp,并忽略那些低于
θ
c
l
s
\theta_{cls}
θcls 的类别。对于每个剩余的类别
c
c
c,我们将第
i
i
i 个候选提议的评分定义为:
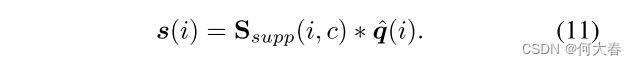
最后,采用类别级软非最大抑制(soft-NMS)[2] 来移除重复的提议。
3.5. Discussions
在这一部分,我们讨论了所提方法与几种相关方法之间的差异,包括 AutoLoc [41] 和 CleanNet [29]。为了解决测试阶段的定位目标与训练阶段的分类目标之间的不一致,AutoLoc 和 CleanNet 提出直接预测动作实例的时间边界,分别通过 Outer-Inner-Contrastive 损失和时间对比损失进行监督。与这些方法不同,我们关注 S-MIL 框架中另一个关于在训练和测试阶段之间应该评分什么的不一致性。候选提案需要在测试阶段得分,而 S-MIL 分类器在训练期间被训练为对片段进行评分。为了解决这种不一致性,我们提出了一种新颖的基于提案的多实例学习框架,该框架在训练和测试阶段直接对候选提案进行分类。
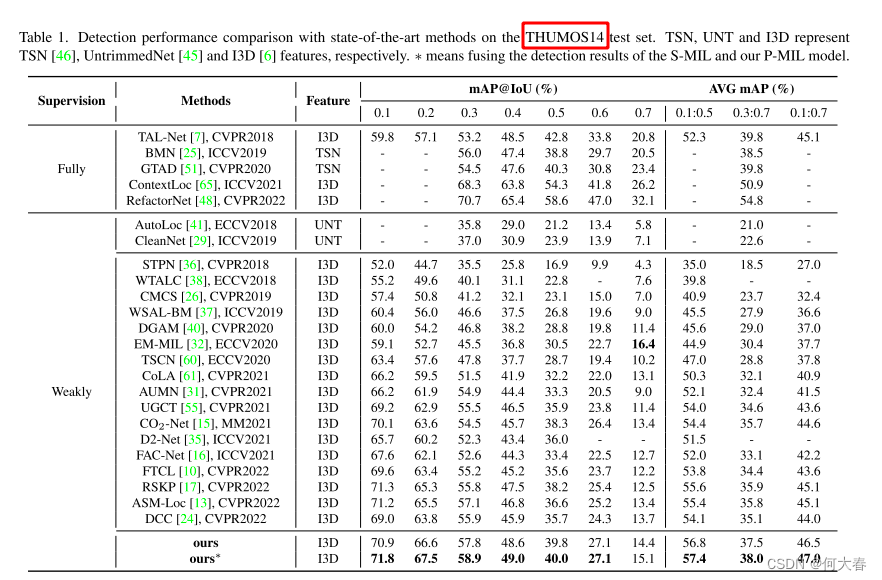
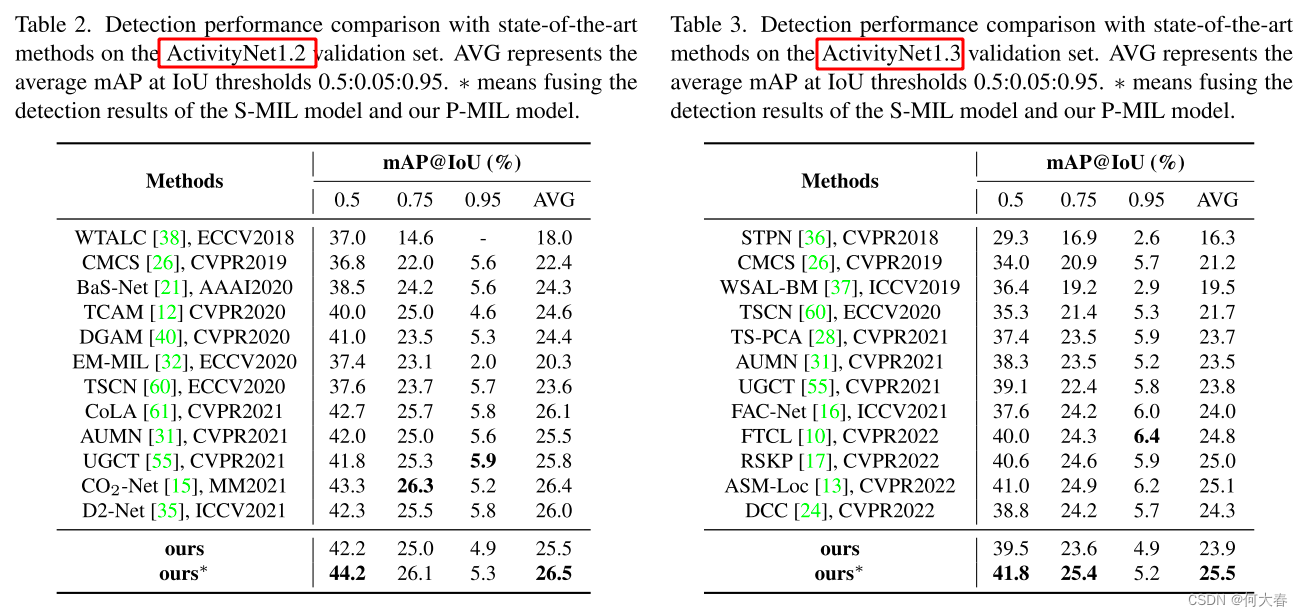
4. Experiment
5. Conclusion
本文提出了一种新颖的基于提案的多实例学习(P-MIL)框架,用于弱监督下的时间动作定位,通过直接对候选提案进行分类,可以实现训练和测试阶段的统一目标。我们引入了三个关键设计来应对P-MIL框架不同阶段的挑战,包括周围对比特征提取模块、提案完整性评估模块和实例级别的排名一致性损失。对两个具有挑战性的基准数据集进行的大量实验结果证明了我们方法的有效性。

















 2923
2923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









