







 本文提出一种无监督视觉异常检测方法,引入新颖的分区存储库(PMB)模块,有效学习和存储正常样本特征,使异常样本重建误差变大。还提出直方图误差估计模块,消除累积重建误差。在三个数据集上实验,证明该方法在异常检测和定位方面的有效性。
本文提出一种无监督视觉异常检测方法,引入新颖的分区存储库(PMB)模块,有效学习和存储正常样本特征,使异常样本重建误差变大。还提出直方图误差估计模块,消除累积重建误差。在三个数据集上实验,证明该方法在异常检测和定位方面的有效性。
Visual Anomaly Detection via Partition Memory Bank Module and Error Estimation 论文阅读
文章信息:

中文标题:基于分区记忆库模块的视觉异常检测与误差估计
发表于:IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY(中科院1区,JCR Q1,CCF-B,IF=4.685)
原文链接:https://arxiv.org/abs/2209.12441
无代码
Abstract
基于存储模块的视觉异常检测的重建方法试图缩小正常样本的重建误差,同时扩大异常样本的重建误差。不幸的是,现有的存储模块并不完全适用于异常检测任务,异常样本的重建误差仍然较小。为此,本工作提出了一种新的无监督视觉异常检测方法,共同学习有效的正常特征并消除不利的重建误差。
具体来说,提出了一种新颖的分区存储库(PMB)模块,用于有效地学习和存储具有语义完整性的正常样本的详细特征。
它开发了一种新的分区机制和独特的查询生成方法来保留上下文信息,然后提高存储模块的学习能力。交替探索提出的PMB和跳跃连接,使异常样本的重建变得更糟。
为了获得更精确的异常定位结果并解决累积重建误差的问题,提出了一种新颖的直方图误差估计模块,通过差异图的直方图自适应消除不利的误差。它提高了异常定位性能,而不增加成本。
为了评估所提方法在异常检测和定位方面的有效性,对三个广泛使用的异常检测数据集进行了大量实验。与基于存储模块的最新方法相比,所提方法的令人鼓舞的性能证明了其优越性。
I. INTRODUCTION
视觉异常检测旨在检测与正常视觉数据不同的异常数据[1],[2],在工业异常检测[3],[4],[5],[6],[7]、异常分割[8]和医学诊断[9]等各种应用中显示出巨大潜力。由于异常模式多样且视觉异常数据的发生频率远低于正常数据[3],[10],[11],[12],[13],[14],因此几乎不可能获取具有不同异常模式的足够异常训练样本。因此,仅使用正常训练数据就能成功检测异常数据具有挑战性。
一些方法已被研究用于解决异常检测任务。最近,在[17]、[18]和[19]中,自编码器(Autoencoder,AE)[20]被引入到无监督异常检测中,基于重建误差[17],[21],[22]来检测异常样本。这些方法期望AE能够用小的重建误差重建正常样本,用大的重建误差重建异常样本。众所周知,在许多计算机视觉任务中,AE具有强大的重建能力[23],[24],[25],[26]。然而,AE强大的重建能力对视觉异常检测[15],[27]并不利。即使对于未学习的异常样本,AE仍然能够用较小的重建误差很好地重建它们[15]。因此,单独使用AE重建的重建误差不足以解决异常检测的挑战。一些工作提出了更复杂的自监督任务,例如图像着色[28]。复杂的自监督任务使AE学习正常的语义信息来恢复原始图像。对于未学习的异常样本,异常的语义无法恢复,使得重建误差更大。然而,由于异常和正常样本之间的语义信息存在微小差异,这些方法并不能很好地检测到异常样本。
在现有的方法中,现有的存储模块实际上并不存储正常特征,而是逻辑信息。如图1(1)和图1(2)所示,传统方法生成的查询是原始特征图中同一位置但来自不同通道的特征的逻辑重组。通过滑动窗口方法,单个通道特征是由前一层特征图中相同的卷积核提取的,其中包含类似的关键特征信息。然而,特征图的逻辑重组生成的查询破坏了卷积网络学习到的关键特征,使得存储模块能够学习到重组后的逻辑信息。当异常特征作为查询地址存储模块时,传统模块将适应异常特征读取逻辑关系以支持图像重建。因此,它使得异常样本的检测和定位在小的重建误差下失败。图2(1)展示了异常样本B的检测失败示例,它通过传统的查询生成方法学习了存储模块(图1(1))。
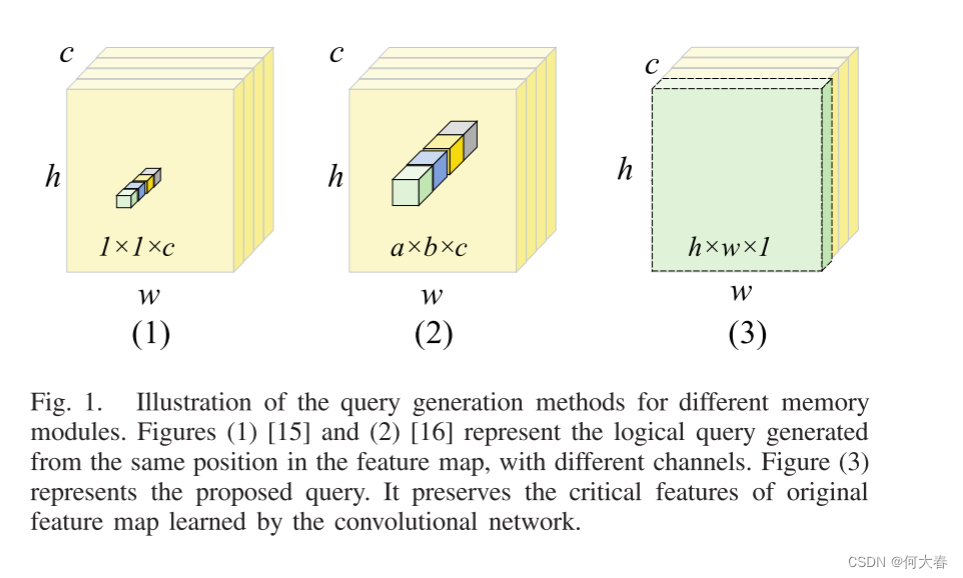
图1. 不同存储模块的查询生成方法示意图。图(1)[15]和(2)[16]表示从特征图中相同位置生成的逻辑查询,具有不同的通道。图(3)代表了提出的查询方法。它保留了由卷积网络学习到的原始特征图的关键特征。
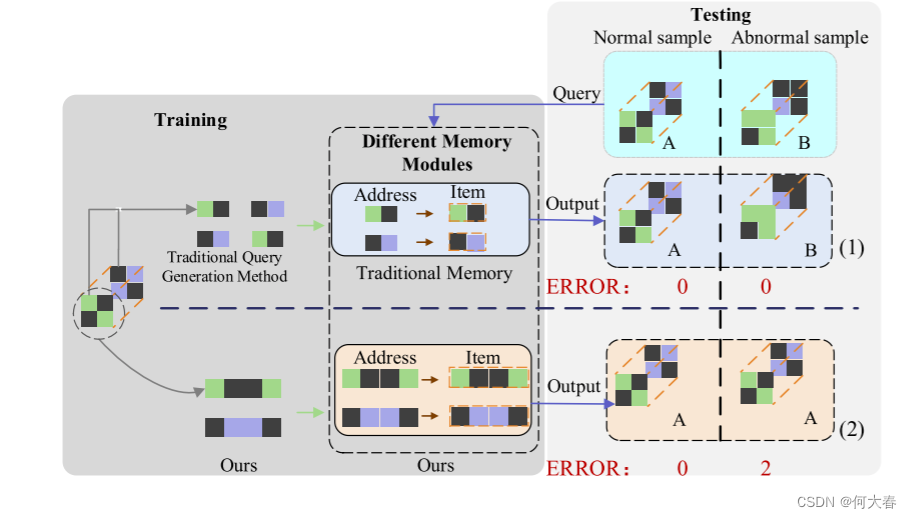
图2. 展示了传统存储模块和提出的PMB模块学习到的存储项以及它们的查询生成策略的示意图。所提出的方法从特征图的每个通道生成查询,而传统方法则通过重新组织不同通道中相同位置的特征来生成查询。 "ERROR"表示重建误差。虚线框表示两个不同存储模块学习到的存储项。当正常样本A(A与训练样本相同)查询传统存储模块和提出的PMB时,得到了重建误差较低的重建样本。然而,当异常样本B查询两个存储模块时,传统存储模块仍然可以读取传统的存储项来重建异常样本B。提出的方法无法读取相应的异常特征,只能将B重建为A以获得较大的重建误差。
当面对微小区域异常样本时,还有另一个方面需要考虑 - 累积重建误差的影响。引入存储模块使得自编码器即使对于正常区域也无法实现零误差重建。由于累积误差,一些正常样本的异常分数可能超过了小异常区域(例如小划痕)的异常样本分数,导致不正确的检测和定位结果。
此外,现有方法[15],[27]采用一种方案,即将上一个编码器的输出和存储模块的读取连接起来作为解码器的输入。然而,这种方法无法很好地探索存储模块的存储,因为编码器分支可以为重建提供足够的特征。此外,这些方法将存储模块放置在编码器的最后一层之后,更加注重高级特征,这些特征不适用于需要低级特征的异常定位。因此,基于自编码器的所有异常检测方法都无法达到像素级的异常定位。
为此,本文提出了一种新颖的自编码器联合存储模块网络,如图3所示。它利用了一个Partition Memory Bank(PMB)模块来提高学习和存储正常特征的能力,以及一个直方图误差估计模块来自适应地消除存储模块引起的累积重建误差的影响。为了保留从原始特征图中学习到的关键特征信息,PMB模块开发了一种新颖的查询生成方法,利用每个通道特征生成查询,如图1(3)所示。它使得存储模块能够学习到正常的语义特征而不是逻辑特征的重新组织。当异常特征作为查询地址PMB模块时,它按语义关系读取存储的正常特征以获得正常特征。因此,重建误差变大。图2(2)展示了一个成功检测的示例,其中PMB模块导致异常样本B被重建为正常样本A(重建误差足够大以成功检测为异常)。同时,PMB需要使正常区域的重建误差尽可能小。提出了一个分区机制来进一步提高存储模块的表达能力,它使用多个存储单元独立存储不同分区的正常特征。因此,PMB模块使得正常区域的重建误差较小,而异常区域的误差较大,这有利于异常样本的检测。直方图误差估计模块利用重建误差图构建直方图,然后用于自适应地估计每个图像的正常区域的重建误差,以获得更有效的修正误差图。更重要的是,它是一种非参数方法,不消耗额外资源。
为了使PMB模块更加关注低级特征以实现更精确的定位,我们开发了一种新的方案。我们直接将skip连接作为解码器的高级特征输入,并将存储模块的读取作为低级特征的输入。PMB的读取和skip连接的输出分别在不同的层次上单独使用,而不是在同一层级上连接,这使得存储模块能够学习到更加详细的正常样本特征。对广泛使用的数据集进行的实验结果表明,所提出的方法获得了竞争性的结果。
主要贡献概述如下:
- 本文提出了一种新颖的Partition Memory Bank(PMB)模块。PMB的独特分区机制和查询生成方法可以有效学习和存储正常特征,并在异常检测任务中取得了出色的结果。
- 为了解决更精确的异常定位的挑战,我们开发了一个新的非参数直方图误差估计模块,用于消除累积重建误差,可以获得更好的异常检测结果和异常定位图。
- 我们共同探索了自编码器(AE)、PMB模块和直方图误差估计模块的最佳兼容性。我们在三个基准数据集上进行了实验,结果显示所提出的方法能够有效解决成功重建异常样本的问题。
II. RELATED WORK
A. Unsupervised Visual Anomaly Detection
对于无监督的异常检测,检测模型仅通过正常样本进行训练,用于检测异常样本并定位异常区域[18]。传统的分类器被引入用于异常检测,例如SVM [30]和OC-SVM [31]。随着深度学习的普及,研究人员提出了深度单类方法,如DSVDD [32]和OCNN [33]。这些方法的共同思想是学习正常样本的决策边界。例如,DSVDD学习一个球形判别平面来提高判别效率。然而,这些方法在处理高维数据方面效果较差。
基于预训练模型的计算机视觉任务引起了广泛关注。一些异常人脸识别任务[34],[35],[36]或异常检测任务[5],[37],[38]引入了预训练模型作为特征提取器。在U-Std [5]中,引入了基于预训练教师网络的知识蒸馏。由于学生网络仅学习正常样本的潜在表示,样本异常程度是通过多个学生和教师网络之间潜在特征表示的差异来衡量的。然而,它们依赖于额外的训练数据集和巨大的资源消耗。一些研究提出了利用GAN [39]来解决异常检测问题。GAN中的生成器用于学习正常样本特征,鉴别器用于识别异常[40],[41],[42]。然而,GAN可能不稳定,并且在实际情况中往往产生不理想的结果。
最近,基于重建的方法在异常检测中变得流行起来,它期望能够较差地重建异常样本,并扩大异常样本和正常样本重建误差之间的差距[17],[18],[19],[28],[43],[44],[45],[46],[47]。例如,AE-SSIM [19]试图直接使用自编码器重建正常样本,而ARFAD [28]通过自监督任务(如旋转)学习正常样本的重建特征。然而,这些方法不仅成功地重建了正常样本,还重建了异常样本,导致性能受限。
与上述方法不同,本文提出了一种新的PMB模块来重建成功的正常样本和不良异常样本。
B. Memory Network
记忆模块最初是适用于自然语言处理领域的[23],[24],[48],[49]。记忆模块包括查询项和记忆项以及查询的结果。查询项和记忆项通过相似性计算获取查询权重,然后根据权重读取记忆项的内容以获取读取结果。最近,一些现有作品将记忆库引入计算机视觉任务[50],[51],例如假视频检测[52]和异常检测[27],[29]。Gong等人[15]提出了MemAE,它使用记忆模块来减少AE [20]对异常样本的重建能力。这可以从特征选择[53]的角度解释,因为记忆模块存储了正常特征,无法从记忆模块中选择异常特征。然而,由于其简单的记忆模块和组合方法的缺点,它很难对微小异常样本的检测和定位任务产生有效结果。Park等人[27]提出了一个AE和记忆模块的组合网络用于视频异常检测。它构建了一个记忆模块的记忆项更新方法,并将AE和记忆模块的输出连接起来作为解码器的输入。然而,由于它更多关注高级特征,因此不适合复杂场景的定位挑战。其次,AE的输出作为解码器的输入导致了记忆模块中存储特征的限制。Wang等人[29]在MemAE框架上引入了一个额外的评估网络作为鉴别器,用于检测样本是否异常。然而,使用鉴别器很难实现异常区域的定位。
与提出方法最相关的研究是DAAD [16]。它使用图1(2)中的方法生成大小为 a × b × c ( a ≤ h , b ≤ w ) a×b×c(a≤h,b≤w) a×b×c(a≤h,b≤w)的记忆查询,并使用鉴别器识别样本是否异常。DAAD使用较大的查询(通常为8×8×c)来使不共享相同块模式的异常和正常样本。然而,这破坏了卷积网络学习到的特征的完整性,导致记忆模块学习到了重新组织的逻辑信息。因此,异常特征也可以逻辑上适应异常,使得重建误差较小。所提出的PMB模块使用了大小为 h × w × 1 h×w×1 h×w×1的新型查询(图1(3)),使得记忆模块能够存储从卷积网络学到的正常特征。因此,所有的查询都可以定位到PMB模块以获取正常特征。与DAAD不同的是,它不降低AE的重建能力,而是使记忆模块无法处理异常特征。此外,DAAD引入了具有对抗损失的鉴别器来解决累积误差引起的不正确判别问题,这导致了额外的资源消耗和异常定位的失败。在本文中,我们不仅确保了正常特征能够被良好地重建,而且异常定位结果可以从误差图中得出,而不需要额外的资源。
III. THE PROPOSED METHOD
A. Overview
这项工作提出了基于重建方案来解决无监督异常检测问题。拟议框架的概述如图3所示。所提出的框架包含三个基本结构:1)AE,2)PMB模块,和3)直方图误差估计模块。
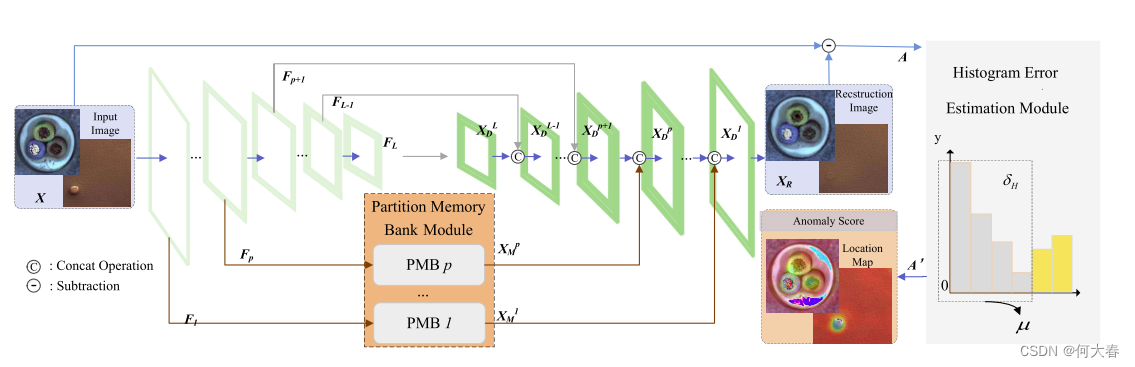
提出框架的图示3如下。它包含了自编码器(AE)、PMB模块和直方图误差估计模块。首先,在AE结构的编码器模块中提取了L层特征图。PMB模块存储了第一个P层低级特征,并随后使用了跳跃连接。重建图像
X
R
X_R
XR与原始图像
X
X
X形成误差图
A
A
A。其次,直方图误差估计模块利用
A
A
A构建直方图,估计并消除
μ
μ
μ,并获得校正的误差图
A
′
A'
A′ 。
A
′
A'
A′用于异常检测和定位。
给定输入样本X,编码器首先提取多尺度特征 F = { F 1 , F 2 , . . . , F L } F = \{F_1,F_2,...,F_L\} F={F1,F2,...,FL}。为了充分利用记忆模块提供的表示信息,并允许记忆模块专注于低级特征,我们利用编码器的第1层到第 p p p层的PMBs的输出以及后续 p + 1 p+1 p+1到 L L L层的输出,并通过跳跃连接。因此,设计了 p p p个PMBs,独立地学习和存储不同尺度的特征图。提出的PMB模块的读取由 X M = { X M 1 , X M 2 , . . . , X M p } X_M = \{X^1_M,X^2_M,...,X^p _M\} XM={XM1,XM2,...,XMp}表示。然后,将 X M X_M XM和前一个解码器的输出 X D X_D XD进行通道连接,作为下一个解码器的输入。解码器之后获得重建图像XR。使用方程式1获得原始差分图像A。

其中,
X
X
X表示输入样本,
X
R
X_R
XR表示重建样本。此外,还开发了直方图误差估计模块,用于消除正常区域的重建误差,从而获得更准确的校正误差图
A
′
A'
A′,用于异常定位和检测。基于
A
′
A'
A′,获得样本的异常分数和异常定位图。
B. Partition Memory Bank Module
如图4所示,PMB模块用于学习和存储正常样本的潜在特征表示。通过探索所提出的联合划分机制和一种新的查询生成方法,实现了异常样本重构误差变大的挑战。
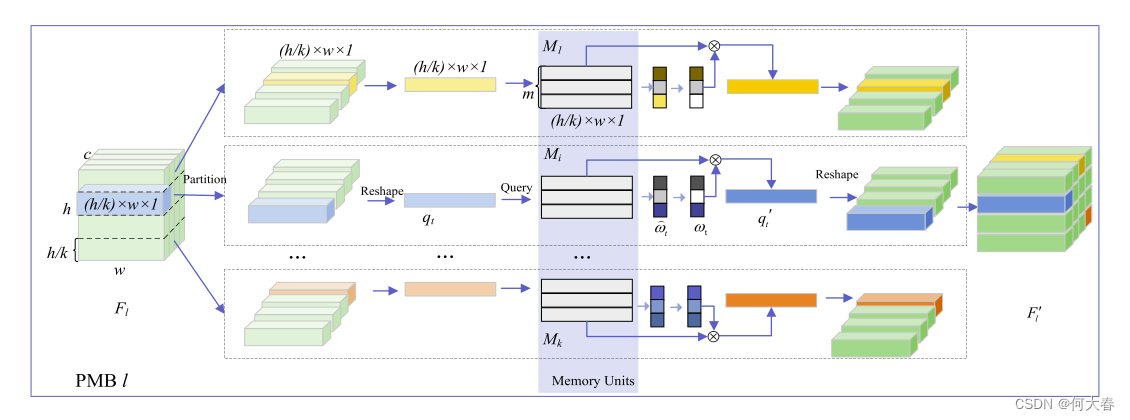
图4:提出的PMB模块的框架。对于每一层特征图 F l F_l Fl,分区机制导致特征图被划分为单独的分区。每个分区都有一个单独的记忆单元来存储正常特征。每个查询以注意力方式定位到记忆单元,以获取有效的正常特征读取作为解码器的输入。
为了生成具有关键特征信息的查询,开发了一种新颖的查询生成方法,如图1(3)所示。它直接从特征图的每个通道生成查询。因此,每个查询包含单个通道的语义信息,使得PMB模块只能存储正常的语义信息。此外,为了增强记忆模块的学习能力和表达能力,并使正常区域的重建误差变小,提出了一个分区机制。它引入了多个局部单元,分别存储不同区域的正常特征。每个记忆单元能够存储单个区域的详细特征信息。多个记忆单元使得记忆模块的表达能力得到增强。
具体而言,对于来自特征集
F
F
F的大小为
h
×
w
×
c
h × w × c
h×w×c的每个特征图
F
l
F_l
Fl,使用图4所示的提出的查询生成方法进行分区。沿着特征图的
‘
h
’
‘h’
‘h’维度,
F
l
F_l
Fl被分成
k
k
k个大小为
h
k
×
w
×
c
\frac{h}{k}×w×c
kh×w×c的区域,每个区域由单独的记忆单元存储和查询。每个分区中每个通道的特征图被展平成一个
h
k
×
w
\frac{h}{k}×w
kh×w维度的向量。因此,我们可以在每个分区中获得查询集合
Q
=
{
q
t
∣
t
∈
[
1
,
c
]
}
Q = \{\pmb{q_t}|t ∈[1, c]\}
Q={qt∣t∈[1,c]}。每个PMB包含
k
k
k个记忆单元
M
=
{
M
1
,
M
2
,
.
.
.
,
M
k
}
\pmb{M} = \{\pmb{M_1}, \pmb{M_2}, ..., \pmb{M_k}\}
M={M1,M2,...,Mk},每个记忆单元包含
m
m
m个记忆项,记忆项的大小与查询
q
t
\pmb{q_t}
qt相同。最后,如图4(4)所示,假设
q
t
\pmb{q_t}
qt是
F
l
F_l
Fl的第
i
i
i个分区的查询,首先将
q
t
\pmb{q_t}
qt和
M
i
\pmb{M_i}
Mi中相应的记忆项归一化,以提高注意力权重的准确性。归一化操作如下:
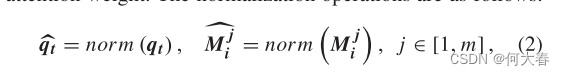
其中,
n
o
r
m
(
⋅
)
norm(·)
norm(⋅)表示
l
2
l_2
l2范数。
q
t
^
\widehat{q_t}
qt
表示归一化的查询
q
t
\pmb{q_t}
qt。
M
i
^
\widehat{M_i}
Mi
表示归一化后的记忆项。然后,使用
q
t
\pmb{q_t}
qt和记忆项
M
i
^
\widehat{M_i}
Mi
之间的相似度来计算注意力权重
w
t
^
\widehat{w_t}
wt
,如下所示:
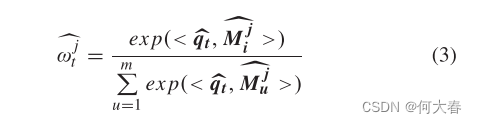
这里的
<
⋅
,
⋅
>
< ·, · >
<⋅,⋅> 表示余弦相似度。然而,最近的研究[15]提到权重
w
i
j
^
\widehat{w^j_i}
wij
太小,导致从存储器库查询结果是通过逻辑方式将存储器库中的每个存储项进行拟合,而不包含正常的语义信息。因此,本文提出通过引入阈值来过滤小的权重。查询存储器库的结果仅受具有较大权重的特定存储项的影响,并且不能通过多个存储项进行逻辑拟合。对于异常特征从正常特征的存储器库中查询相应的异常结果更加困难。因此,当异常特征用作查询时,只能读取存储的正常特征,然后异常区域的重建误差就会变大。
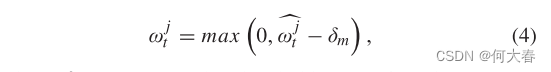
这里
δ
m
δ_m
δm 表示阈值。通过使用存储器模块,我们可以通过使用记忆单元
M
i
M_i
Mi 的输出来为每个查询
q
t
\pmb{q_t}
qt获得一个新的特征向量
q
t
′
\pmb{q'_t}
qt′。
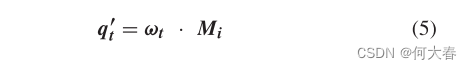
然后,通过重新排列所有的 q t ′ \pmb{q'_t} qt′,可以获得一个新的特征图 F ′ F' F′,并将其输入解码器生成重建图像 X R X_R XR。值得注意的是,通过使用 q t ′ \pmb{q'_t} qt′,可以提高重建网络的稳定性,因为 q t ′ \pmb{q'_t} qt′ 的值变化不大。
C. Histogram Error Estimation Module
对于每个图像,通过使用公式 1 获得原始的误差图 A,其中每个像素的值表示重建误差。在提出的方法中,重建误差来自于提出的PMB模块和AE。PMB模块学习和存储正常特征,从而确保了正常区域的重建误差明显小于异常区域的重建误差。然而,由于存在存储模块,AE很难在正常区域实现零误差重建。这些累积的重建误差可能导致原始误差图中的误检测。因此,我们需要进一步减轻累积重建误差对检测和定位性能的影响。
在本文中,我们探索了一个简单但有效的直方图误差估计模块来估计误差 μ。如图 3 所示,
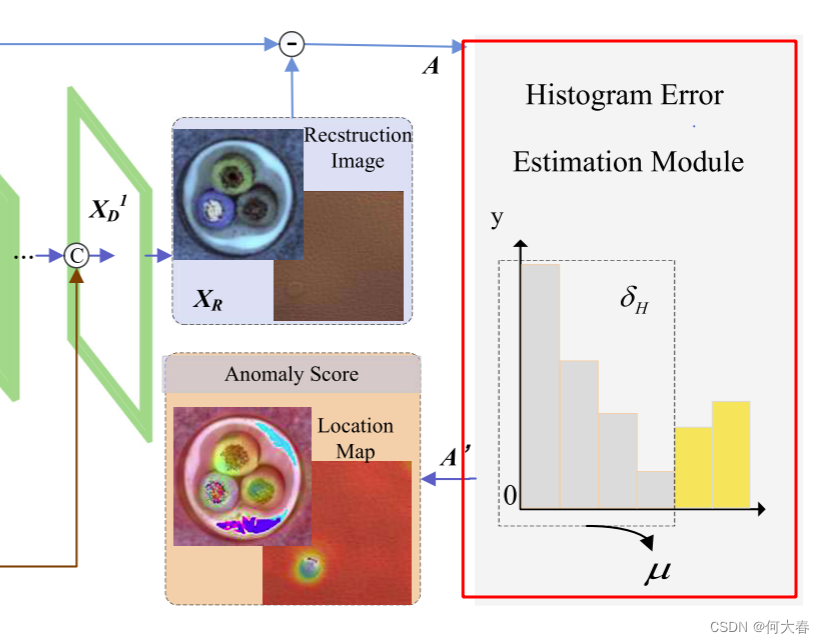
首先构建误差图的直方图。由于正常区域的重建误差很小,因此正常区域的像素始终位于直方图的左侧。因此,我们可以快速在直方图中找到正常像素。然后,在图 3 的直方图的虚线框中选择小重建误差的百分比
δ
H
δ_H
δH 来估计
μ
μ
μ。选择的这些像素的误差的平均值被用来估计
μ
μ
μ。然后,根据以下方式获得校正的差异图
A
′
A'
A′:
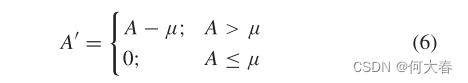
对于异常检测和异常定位任务,图像的异常程度由异常分数来衡量。对于异常定位任务,需要获取每个测试图像
T
T
T 的每个像素的异常分数
S
T
(
i
,
j
)
S^{(i, j)}_T
ST(i,j)。对于异常检测任务,需要获取图像 T 的整体异常分数
S
^
t
\hat{S}_t
S^t。
S
T
(
i
,
j
)
S^{(i, j)}_T
ST(i,j)和
S
^
t
\hat{S}_t
S^t都可以从 A 中推断出来。
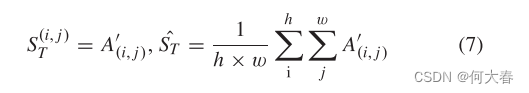
其中,
h
h
h 和
w
w
w 分别表示原始图像
T
T
T 的高度和宽度,而
A
′
(
i
,
j
)
A'(i, j )
A′(i,j) 表示
A
′
A'
A′ 中位置
(
i
,
j
)
(i, j)
(i,j) 的值。
D. Loss Function
为了训练提出的模型,联合探索了重建图像的质量和人类视觉系统的直观感受。引入了重建损失
L
M
S
E
\mathcal{L}_{MSE}
LMSE和结构相似性指数(SSIM) [60] 损失
L
S
S
I
M
\mathcal{L}_{SSIM}
LSSIM,它们的定义如下:

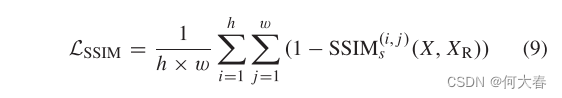
这里的
h
h
h 和
w
w
w 表示图像的高度和宽度。
S
S
I
M
s
(
i
,
j
)
SSIM^{(i, j)}_s
SSIMs(i,j)
(
X
,
X
R
)
(X, X_R)
(X,XR) 表示图像
X
X
X 和图像
X
R
X_R
XR 在中心位置
(
i
,
j
)
(i, j)
(i,j) 的结构相似性指数,其核大小为
s
s
s。
最后得出训练总损失如下:
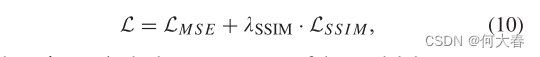
其中
λ
S
S
I
M
λ_{SSIM}
λSSIM是衡量
S
S
I
M
SSIM
SSIM损失重要性的模型的超参数。
IV. EXPERIMENTS
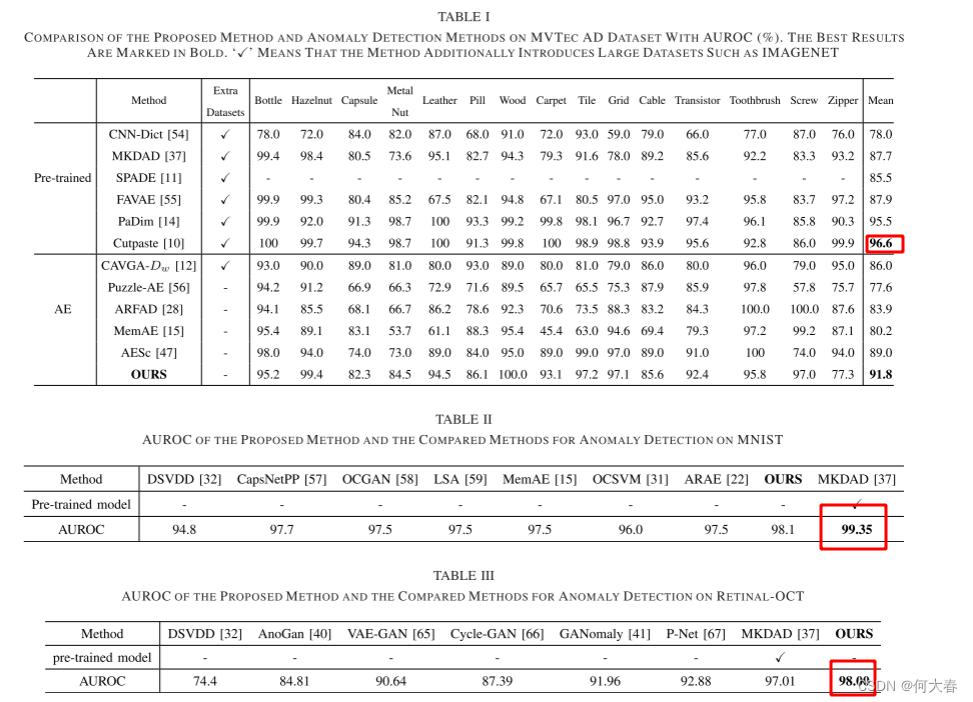
异常检测:
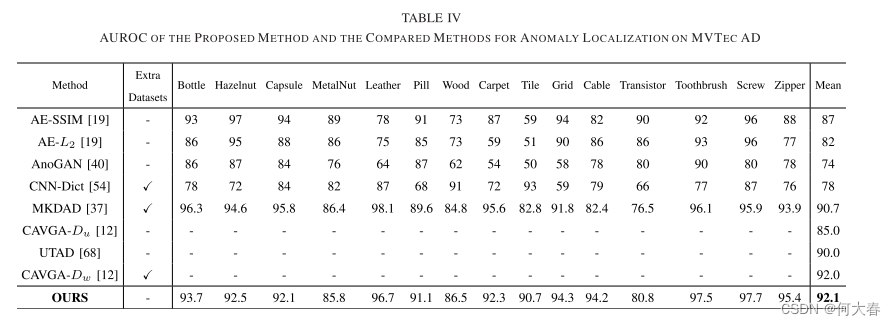
异常定位:
V. CONCLUSION
本文提出了一种新的无监督视觉异常检测方法,通过联合探索自动编码器(AE)和新型记忆模块。为了解决现有记忆模块存在的问题,引入了一种新的Partition Memory Bank(PMB)模块,并采用新颖的查询生成方法,可以学习和存储正常样本的特征。通过成功重建正常特征,使得异常特征只能与PMB中存储的正常特征匹配,导致异常区域的重建误差变大。此外,为了消除AE造成的累积重建误差,提出了一种新颖的直方图误差估计模块,通过探索正常区域的重建误差。检测和定位性能得到了显著提高。最后,我们探索了记忆模块和跳跃连接的最佳组合方式。我们在三个广泛使用的数据集上进行了大量实验证实了所提方法对视觉异常检测的有效性。未来,我们将探索更适合估算AE引起的误差的模型,并探索所提PMB模块对其他计算机视觉任务的泛化能力。
阅读总结
没代码,没在论文中说记忆模块是怎么更新的,只说了怎么查询。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









