







ECCV2020
Appearance-Preserving 3D Convolution for Video-based Person Re-identification
本文仅作学习使用
论文地址:AP3D
项目地址:AP3D
参考:【ECCV2020 Oral】AP3D:解决3D Conv中的表观破坏问题
贡献
- 发现现有的 3D 卷积在存在错位时提取外观表示存在问题;
- 提出一种AP3D方法来解决这个问题,在卷积操作之前根据语义相似度对齐像素级的特征图;
- 与最先进的方法相比,在基于视频的 ReID 上实现了卓越的性能。
背景
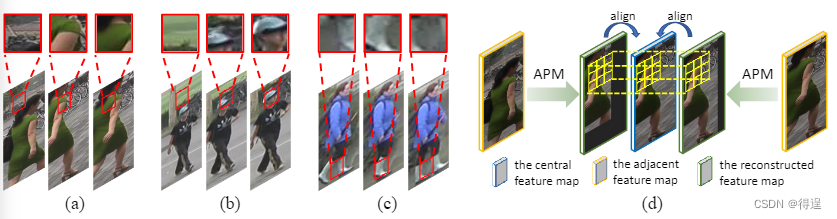
不同于大多数视频分类问题,video re-id的数据来源于检测算法得到的bounding box (如上图),而非监控视频原始帧。这就导致了当检测结果存在误差时(检测框过小或者过大)相邻帧之间的表观会对不齐,比如图(b)中相连三帧红框框住的区域分别对应背景、帽子以及整个头部。即使检测结果相对准确时,由于人的姿态变化,不对齐现象也会不可避免,如图(c)。
有人可能会有疑问:正常视频分类里相邻帧或者采样跨度较大时,视频中很多目标也是不对齐的。3D Conv在这种情况下刚好可以捕捉运动的motion,最终表现在性能上也会有所提升,为什么单独拿video re-id中的不对齐来说事?
这就涉及到当前video re-id的第二个和大多数视频分类问题的不同点。由于目前的video re-id数据集构建还不涉及换衣服问题,所以在识别过程中占主导作用的还是表观特征,而非motion特征。当采样帧间存在表观不对齐时,3D Conv就会把来自不同部位的特征卷成一个值,这在一定程度上会对表观特征造成破坏。这也就可以解释为什么3D Conv在video re-id问题上不work了。
本文提出了外观保持3D卷积(AP3D)来解决现有3D卷积的外观破坏问题。如图1(d)所示,AP3D由一个外观保持模块(APM)和一个3D卷积核组成。对于每个中心特征图,APM根据跨像素语义相似度重建其相邻特征图,并保证重建的特征图与中心特征图之间的时间外观对齐。APM 的重建过程可以看作是两帧之间的特征图配准。
针对外观信息不对称的问题,提出了Contrastive Attention来寻找图像之间的不匹配区域重建和中心特征图。然后,将学习的注意力掩码施加到重建的特征图上,以避免错误传播。在 APM 保证外观对齐的情况下,后续的 3D 卷积可以更有效地对时空信息进行建模,增强视频表示,具有更高的判别能力,但不会破坏外观。因此,基于视频的 ReID 的性能可以大大提高。
AP3D
框架
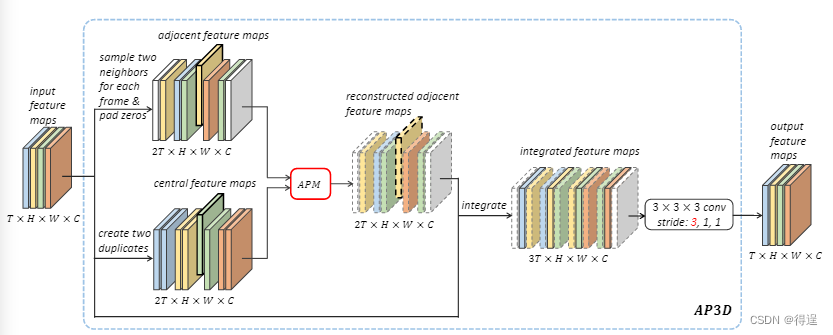
本文中提出了一种新的AP3D方法来解决上述问题。提出的AP3D由一个APM和一个后续的3D卷积组成。具有3 × 3 × 3 卷积核的AP3D示例如图2所示。
具体来说,给定一个具有T帧的输入张量,每个帧都被视为中心帧。
首先为每帧采样两个邻居,并在填充零后总共获得2T个相邻特征图。
其次,APM用于重建每个相邻的特征图,以保证外观与相应的中心特征图对齐。
然后,将重建的相邻特征图和原始输入特征图整合形成一个临时张量。
最后,执行步长为( 3 , 1 , 1 ) 的3 × 3 × 3 卷积,可以生成具有T帧的输出张量。在APM保证外观对齐的情况下,后面的3D卷积可以在不破坏外观的情况下对时间关系进行建模。
首先假设我们有[3,2,1,0]的特征图传过来,里面的数字代表编号。然后再下面的stream,我们传入【3,3,2,2,1,1,0,0】的特征图给网络。
然后上面的stream我们对于每个帧,找到他的前后帧,输入【-1,2,3,1,2,0,1,-1】其中-1代表因为没有前后帧,只能用全为0的特征图。
这样传入网络的时候,就会是一个输入是当前帧,一个是前一帧或者是后一帧,然后我们使得相邻两帧同一个位置对应的是一个行人部位。然后不断这样处理,就会使得整个视频段基本同一个位置对应就是一个行人部位,就做到了特征的对齐,后面就可以直接使用3d卷积了。
APM
特征图配准
APM的目标是重建每个相邻的特征图,以保证重建的和对应的中心特征图上的相同空间位置属于同一身体部位。它可以被认为是每两个特征图之间的图匹配或注册任务。一方面,由于人体是一个非刚性物体,简单的仿射变换无法实现这一目标。另一方面,现有的基于视频的ReID数据集没有额外的对应标注。因此,注册过程并不是那么简单。
注意到来自ConvNet的中级特征包含一些语义信息。一般来说,具有相同外观的特征具有较高的余弦相似度,而具有不同外观的特征具有较低的余弦相似度。如图3所示,红叉表示中心(图3(a))和相邻(图3(b))框架上的相同位置,但它们属于不同的身体部位。计算中心特征图上标记位置与相邻特征图上所有位置之间的跨像素余弦相似度。归一化后,相似性分布在图 3 © (s = 1) 中可视化。可以看出,外观相同的区域被突出显示。因此,在本文中,根据跨像素相似度来定位相邻帧中的相应位置,以实现特征图配准。

对比注意力
由于行人检测的误差,一些回归边界框小于ground truth,因此一些身体部位可能会在相邻帧中丢失(见图1(a))。在这种情况下,相邻的特征图不能与中心特征图完美对齐。为了避免不完美的配准引起的错误传播,提出了对比注意力来寻找重建和中心特征图之间的不匹配区域。然后,将学习到的注意力掩码施加到重建的特征图上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









